Networking Essentials | Core Concepts - System Design Interview
시스템 디자인(System Design)에 있어, 네트워킹(Netwoking)은 고려해야하는 필수적인 부분중 하나입니다.
이 Post에선, 네트워킹에서도 가장 중요한 부분만 정리하려고 합니다.
네트워킹 기초(Networking 101)
OSI(Open Systems Interconnection) Model 7 Layers
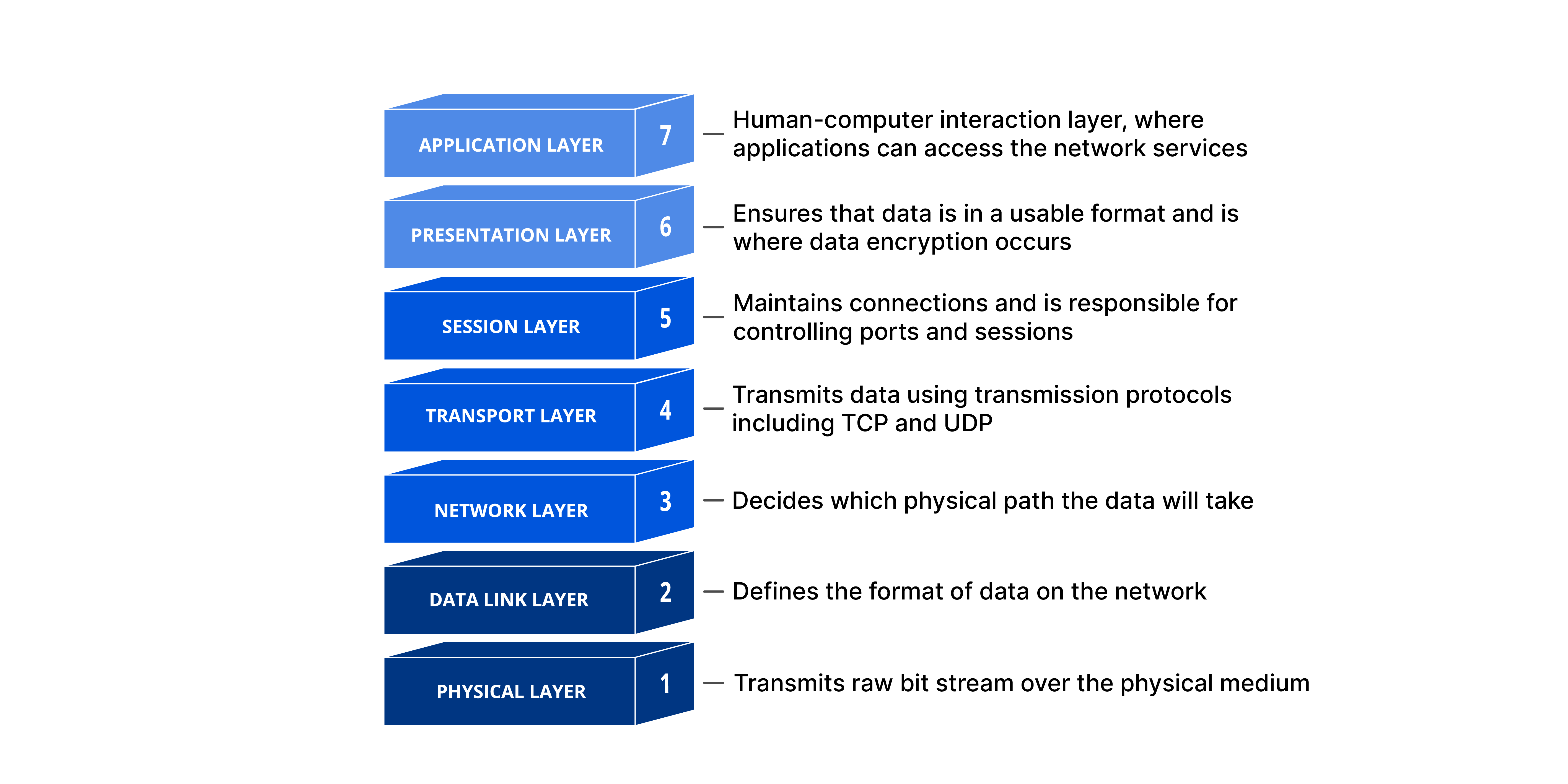 OSI Model 7 Layers
OSI Model 7 Layers
‘OSI 7 Layers’는 네트워크의 구조를 추상화(Abstract)하여 계층(Layer)으로 표현하는 모델입니다.
OSI의 배경
초기 네트워크가 설계될 때부터, 물리적으로 구현된 Architecture는 아닙니다.
이미 네트워크가 만들어진 이후, 네트워크를 정리(교육, 표준화, 문서화 목적으로)하기 위해, 네트워크 계층을 나누어 정리하기 시작했습니다.
이후, ISO/IEC 7498 표준을 통해 OSI가 공식화 되었습니다.
Q: OSI(Open Systems Interconnection)이라는 이름의 의미?
A: OSI가 ‘서로 다른 벤더의 시스템들이, 개방된(open) 표준을 통해 상호연결(interconnect)되어야 한다’라는 목적을 담고 있어서, 지어졌다고 합니다.
OSI가 만들어지던 시절, 각 벤더들은 자기만의 독자적인 프로토콜을 사용하여, 닫힌(Closed) 네트워크를 구축했다고 합니다.
OSI 작동 Flow
OSI 모델이 실제로 동작할 때, 데이터가 시스템 간에 오가는 흐름은 크게 송신 측(Send) 과 수신 측(Receive) 으로 나눠 볼 수 있습니다.
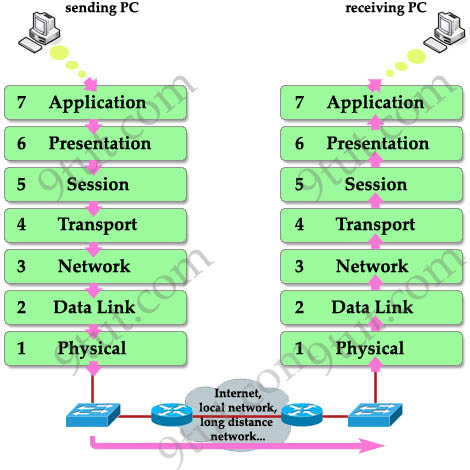 간략하게 표현한 OSI Flow
간략하게 표현한 OSI Flow
](/assets/img/for-post/Networking%20Essentials/image%202.png) OSI 작동 Flow | from bytebytego.com
OSI 작동 Flow | from bytebytego.com
각 계층은 자신에게 할당된 책임만 다루고, 상하위 계층은 인터페이스(헤더·트레일러, API 등)로만 통신하기 때문에 유연한 확장성과 호환성을 보장할 수 있습니다.
Encapsulation
상위 계층의 데이터를 받은 후, 각 계층이 자신만의 헤더(또는 트레일러)를 순서대로 “캡슐”처럼 씌워 물리 매체(Physical Layer)로 보낼 준비를 합니다.De-encapsulation
물리 계층으로 들어온 비트를 받아, 프레임 → 패킷 → 세그먼트 → 데이터 순서로 ‘껍질’을 벗기듯 떼어내며 최종 애플리케이션 데이터로 복원합니다.
Web Request 예시(example)
‘Web Request’ 예시를 통해, ‘Request’가 처리되는 과정을 따라가 봅니다.
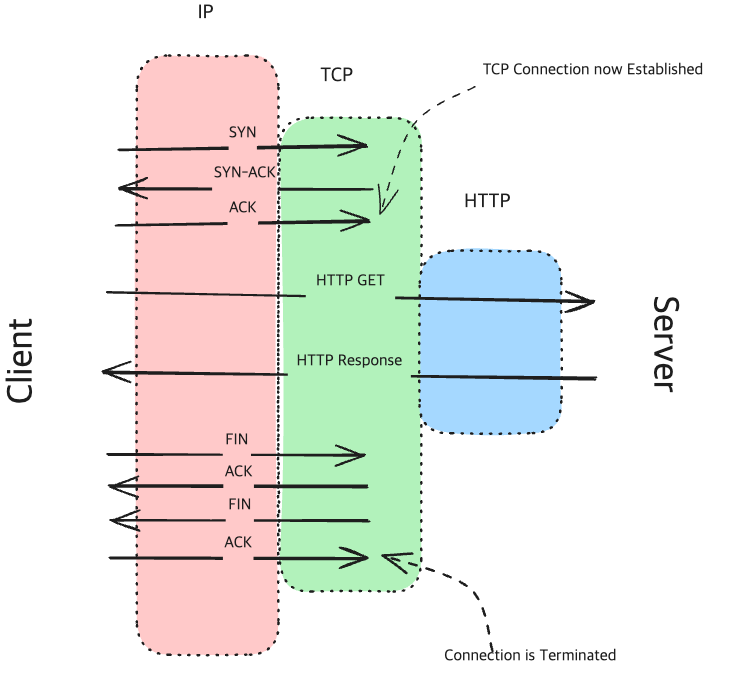 Client → Server Request Example
Client → Server Request Example
DNS Resolution
Client는 Domain name을 IP로 변환합니다.(DNS를 통해)- TCP Handshake
Client는 TCP Connection을 생성하기 위한 작업(‘three-way handshake’)을 실행합니다.- SYN: Client가 보내는 ‘synchronize’ Packet입니다. Connection 생성을 요청하기 위해 보냅니다.
- SYN-ACK: Server는 SYN-ACK(synchronize-acknowledge) Packet으로 Client에게 응답합니다.
- ACK: Client는 ACK(acknowledge) Packet을 서버에 보내며, Connection이 생성(establish)됩니다.
HTTP Request
TCP Connection이 만들어지면, Client는 이를 통해HTTP GET요청을 보냅니다.(서버로부터 웹페이지 가져오기)Server processing
Server에서 Client의 Request를 처리하고, Web Page를 생성하여 HTTP Response를 수행할 준비를 합니다.HTTP Response
Server가 만들어진 Response를 Client에게 전달합니다. 이 Response에는 생성한 Web Page도 포함되어 있습니다.- TCP Teardown
전송(HTTP Response에 대한)이 완료되면, Client와 Server는 TCP Connection을 종료합니다.(four-way handshake)- FIN: Client가 FIN(finish) packet을 서버에 보냅니다.
- ACK: Server가 FIN을 받았다는 의미로 ACK를 보냅니다.
- FIN: Server또한 FIN Packet을 Client에 보냅니다.(Client와 Server 양쪽 모두 종료시키기 위함)
- ACK: Client는 Server가 보낸 FIN Packet을 잘 받았다는 의미로 ACK를 보냅니다.
Network Layer Protocols(Layer 3)
OSI 모델에서 ‘패킷(Packet)’ 단위의 전송을 담당하며, 주로 논리적 주소 지정과 경로 설정(Routing) 기능을 수행합니다.
패킷(Packet)과 IP 데이터그램(IP Datagram)
패킷은 OSI의 네트워크 계층에서 사용하는 추상적이 데이터 단위입니다.
IP 데이터그램은, IP 프로토콜에서 실제로 전송되는 단위를 말합니다.
IP(Internet Protocol) Address
IP Address는 ‘전 지구적 라우팅을 위한 주소 체계’입니다.
- IP버젼에 따라,
- IPv4와 IPv6로 나뉩니다.
- IP의 역할에 따라,
- Public IP(공인 IP)와 Private IP(사설 IP)로 구분하여 설명합니다.
IPv4와 IPv6
| 항목 | IPv4 | IPv6 |
|---|---|---|
| 주소 길이 | 32비트 | 128비트 |
| 주소 공간 | 약 42억 개 (2³²) | 약 3.4×10³⁸ (2¹²⁸) |
| 표기법 | 점으로 구분된 10진수 (예: 192.0.2.1) | 콜론으로 구분된 16진수 (예: 2001:0db8:85a3::8a2e:0370:7334) |
IPv6의 필요성
IPv4의 32비트 공간은 인터넷 기기 폭발적 증가로 고갈되어, NAT(Network Address Translation) 같은 우회책(Private IP를 사용하는)이 필요해졌습니다.
IPv6는 128비트 주소 덕분에 거의 무제한에 가까운 주소를 제공하며, 각 기기에 고유 글로벌 주소를 부여할 수 있습니다.
IPv4와 IPv6를 모두 사용하는 것을 ‘Dual-stack(듀얼 스택)’이라고 합니다.
Public IP와 Private IP
IPv4의 주소가 고갈되면서, ‘IPv4’의 체계를 유지하면서 시스템 확장에 대응하기 위해, ‘Private IP(사설 IP)’가 만들어졌습니다.
Public Network와 Private Network사이에서, NAT(Network Address Translator)를 통해 IP가 치환되어 전송됩니다.
](/assets/img/for-post/Networking%20Essentials/image%203.png) NAT의 역할을 보여주는 이미지. 출처: https://en.wikipedia.org/wiki/Network_address_translation
NAT의 역할을 보여주는 이미지. 출처: https://en.wikipedia.org/wiki/Network_address_translation
Private IP는 RFC 1918(사설 인터넷에 대한 주소 할당 표준)을 통해 별도의 IPv4의 영역으로 구분되어 있습니다.
아래와 같은 주소 범위가 Private IP로 사용됩니다.
1
2
3
10.0.0.0 - 10.255.255.255 (10/8 prefix)
172.16.0.0 - 172.31.255.255 (172.16/12 prefix)
192.168.0.0 - 192.168.255.255 (192.168/16 prefix)
‘RFC 1918’에 따라, Public Network에서는 해당 IP대역이 라우팅되지 않도록 필터링 됩니다.
IPv4 Header 구조
 IPv4 Header 구조
IPv4 Header 구조
ICMP(Internet Control Message Protocol)
ping www.google.com 으로 대표되는 Protocol입니다.
주로 네트워크 통신문제를 진달할 때 사용되며, 데이터가 ‘의도한 대상에게 도달하는지’를 확인하는데 사용됩니다.
IPSec(Internet Protocol Security)
인터넷 프로토콜(IP)을 통해 전송되는 데이터를 안전하게 보호하기 위한 프로토콜 모음입니다.
호스트 간, 게이트웨이(라우터/방화벽)간 터널링, VPN 등에 사용됩니다.
IPSec은 보호 수준에 따라서, 2가지 모드를 제공합니다.
전송 모드(Transport Mode)
- 원본 IP 헤더는 그대로 두고, 페이로드(예: TCP/UDP 데이터)만 보호합니다.
- 호스트 간(end-to-end) 보안에 주로 사용합니다.
터널 모드(Tunnel Mode)
- 원본 IP 패킷 전체를 새로운 IP 헤더 뒤에 캡슐화(encapsulation)합니다.
- 게이트웨이 간(site-to-site) VPN 터널에 주로 사용합니다.
- 외부에서는 터널링 장비의 IP 두 개만 보이고, 내부 네트워크 구조는 은닉합니다.
Transport Layer(Layer 4)
Transport Layer (4계층) 은 호스트 간(혹은 어플리케이션 간)의 종단간(end-to-end) 통신을 책임지며, 주로 세그먼트(segment) 단위로 데이터를 처리합니다.
주요 Protocol로는 TCP, UDP, QUIC가 있습니다.
대부분의 시스템 디자인 인터뷰에서는 TCP나 UDP(거의 TCP) 위주로 다룹니다.
TCP(Transmission Control Protocol, 전송제어 프로토콜)
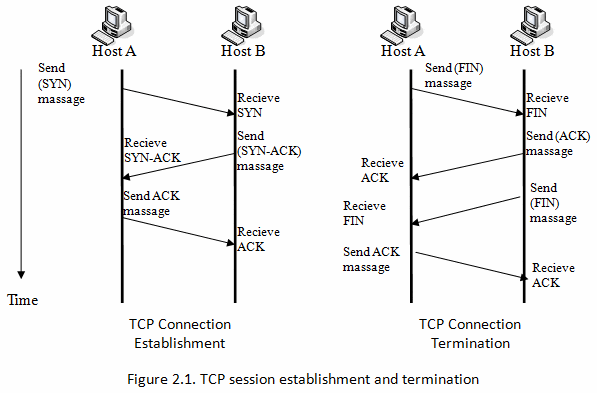 TCP Connection 생성과 종료과정의 Handshake
TCP Connection 생성과 종료과정의 Handshake
](/assets/img/for-post/Networking%20Essentials/image%206.png) How TCP manages a byte stream. | tcpcc.systemapproach.org
How TCP manages a byte stream. | tcpcc.systemapproach.org
TCP는 연결 상태에 대한 강한 신뢰가 필요할때 사용합니다. TCP는 다음과 같은 특징을 갖고 있습니다.
여기서 ‘신뢰’는 모든 Packet이 ‘결과적으로’ 정확하게 도착하는것을 말합니다.
Connection-oriented(연결형 서비스)
통신을 시작하기 전에, 송·수신 간에 3-way Handshake로 논리적인 ‘Session(세션)’을 설정합니다.Reliability(신뢰성, 신뢰할 수 있습니다.)
전송된 Segment(세그먼트, 조각)에 대해 ACK응답을 받고(받았는지 확인하는 신호), 누락 혹은 손상된 경우에는 재전송합니다.In-order Delivery(순서 보장)
수신측에서 순서가 뒤바뀐 Segment를 버퍼링하여 원래 순서대로 어플리케이션에 전달합니다.Flow Control(흐름 제어)
수신 측이 처리 가능한 만큼만 보내도록 송신 윈도우 크기(Rwnd, Receiver Window)를 조절합니다. (슬라이딩 윈도우 사용)Congestion Control(혼잡 제어)
네트워크 과부하를 방지하도록 송신 속도를 조절합니다. (Slow Start, Congestion Avoidance, Fast Recovery 등 이용)Error Detection(오류 검출)
헤더와 페이로드에 대해 Checksum을 계산하여 손상 여부를 검사합니다.
사용 사례
파일 전송(FTP/SFTP), 이메일(SMTP/IMAP), 데이터베이스 요청, 결제 트랜잭션, HTTP/HTTPS, SSH 등…
TCP Segment Header Format
](/assets/img/for-post/Networking%20Essentials/image%207.png) TCP header format | tcpcc.systemapproach.org
TCP header format | tcpcc.systemapproach.org
- Sequence Number: ‘이 세그먼트에 담긴 데이터 바이트 중 첫 번째 바이트가 전체 바이트 스트림에서 몇 번째 바이트인가‘를 나타냅니다. 전체 바이트 스트림중 세그먼트의 위치를 알 수 있게 해줍니다.
- 예를 들면, 다음과 같은 값이 설정되게 됩니다.
첫 세그먼트에 바이트 #1~#500이 담겼다면 Sequence Number = 1
두 번째 세그먼트에 바이트 #501~#1000이 담겼다면 Sequence Number = 501
- 예를 들면, 다음과 같은 값이 설정되게 됩니다.
- Acknowledgment Number: 다음에 기대하는 바이트 위치(즉, 마지막으로 받은 바이트+1)
- Flags:
각 플래그 값의 의미는 다음과 같습니다.- SYN: 연결 요청
- ACK: 응답 확인
- FIN: 연결 종료 요청
- PSH, RST, URG 등
- Window Size: 수신자 버퍼 여유 공간(Rwnd, Receiver Window)을 나타냅니다.
- Checksum: 헤더+데이터 무결성 확인용으로 사용됩니다.
TCP Keepalive
- TCP Keepalive는
- TCP 연결이 유휴 상태(idle)가 된 후에도 피어(peer)가 살아 있는지 확인해 주기 위한 운영체제(OS) 수준의 기능입니다.
- ‘half-open 연결(TCP를 구성하는 Host중 한쪽만 열린 상태)’을 정리하거나 방화벽·NAT 매핑 유지를 목적으로 사용합니다.
HTTP Header의
Connection: keep-alive는 동작하는 Layer가 다르며, HTTP KeepAlive가 반드시 TCP KeepAlive를 기반으로 작동하는것은 아닙니다.
](/assets/img/for-post/Networking%20Essentials/image%208.png) TCP Keepalive가 connection이 닫히는걸 방지하는 Flow | from aws.amazon.com
TCP Keepalive가 connection이 닫히는걸 방지하는 Flow | from aws.amazon.com
Idle 타이머 시작(Start Keepalive Idle Timer)
연결이 ESTABLISHED 상태로 일정 시간(예: 2시간) 동안 데이터 교환이 없으면, 커널은 Keepalive Probe를 보내기 위해 타이머를 시작합니다.Probe 전송(Keepalive Probe)
상대방에게 “아직 살아 있나?”를 묻는 빈 ACK 세그먼트(페이로드 0) 또는 윈도우 프로브(window=0) 형태로 전송합니다.
이때 SEQ 번호는 SND.UNA-1 (즉, 마지막으로 성공적으로 ACK된 바이트 이전)으로 설정해, 상대가 ACK를 답하도록 유도합니다.응답 대기 및 재전송(Keepalive Retransmit)
첫 Probe 후 일정 시간(예: 75초) 동안 응답이 없으면 재전송 합니다.
재전송 횟수(예: 9회)를 초과할 때까지 Probe를 반복합니다.연결 해제(Keepalive Timeout)
지정된 횟수만큼 Probe에 답이 없으면 “peer unreachable”로 간주합니다.
소켓을 강제 종료하고, 애플리케이션에 오류(ETIMEDOUT)를 알리게 됩니다.
Congestion Control
- TCP Congestion Control(혼잡 제어)는
- 네트워크 혼잡(congestion) 상황에서 패킷 손실과 지연(latency) 폭발을 방지하기 위해, 송신(Sender) 측이 전송 속도를 동적으로 조절하는 메커니즘입니다.
다음과 같은 효과가 있습니다.
버퍼 오버플로우 방지
라우터·스위치의 큐(buffer)가 가득 차면 패킷 손실이 급증하게 되는데, 이를 예방합니다.네트워크 사용에 대한 공정성(Fairness) 제공
여러 송신자가 하나의 링크(네트워크상의 경로를 의미)를 공유할 때, 서로 과도하게 대역폭을 가져가지 않도록 조절합니다.효율성(Efficiency) 증대
네트워크 용량(capacity)을 최대한 활용하되, 손실 없이 안정적으로 작동하게 합니다.
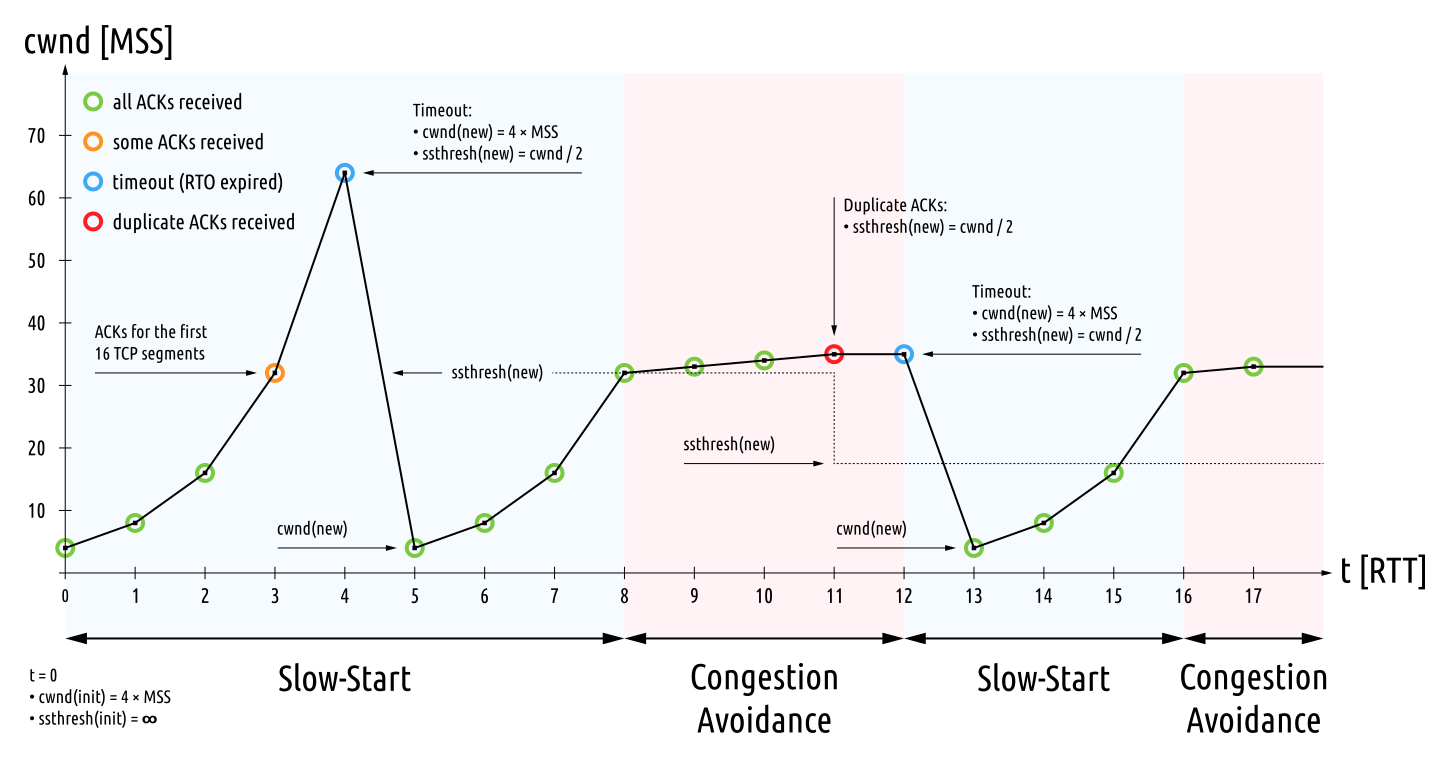 주요 Algorithm Flow
주요 Algorithm Flow
Slow-Start
적은 데이터를 전송하면서, 네트워크의 허용량을 가늠하며, 전송할 데이터의 양을 늘립니다.
ACK(수신완료 신호)가 올 때마다 cwnd(Congestion Window)를 2배씩(지수적으로) 증가합니다.Congestion Avoidance
패킷 손실이 발생하면, 해당 부분부터는 조금씩(1 MSS, 선형적으로)증가시킵니다.
네트워크 용량 한계 근처에서 안정적으로 대역폭을 탐색하기 위한 과정입니다.
TCP는 언제 선택하면 되나요?
- 신뢰성(신뢰할 수 있는 전송)이 필요할 때
- 순서 보장(in-order delivery)이 필요할 때
- 흐름 제어(flow control)와 혼잡 제어(congestion control)가 필요할 때
- 연결 지향(connection-oriented) 통신이 자연스러운 프로토콜
UDP(User Datagram Protocol)
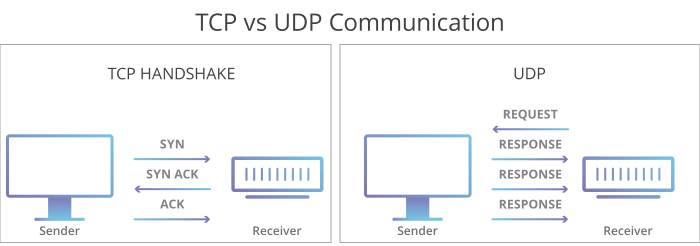 TCP의 Handshake와 같은 과정이 없는 UDP.
TCP의 Handshake와 같은 과정이 없는 UDP.
비연결형, 비신뢰성 전송 프로토콜입니다. TCP와 달리 최소한의 헤더만 붙여 빠른 전송을 목표로 합니다.
UDP는 다음과 같은 특징을 갖고 있습니다.
Connectionless(비연결형)
세션 설정(handshake) 과정 없이 곧바로 데이터를 전송합니다.
각 데이터그램을 독립적으로 취급합니다.Unreliable(신뢰할 수 없는)
UDP에서는 데이터 손실이 발생할 수 있습니다.
ACK/Re-transmission 없어, → 손실·순서 뒤바뀜 감지·복구 기능을 제공하지 않습니다.
애플리케이션이, 필요 시 자체 재전송·순서 보장 로직을 구현해야 합니다.Low Overhead(낮은 오버헤드)
헤더 크기 아주 작습니다.(8바이트) → 실시간성이 중요한 서비스에 유리합니다.
각종 기능들이 최소화 되어 있어, 지연(latency)과 처리 부하가 적습니다.애플리케이션 주도 제어
흐름 제어나 혼잡 제어 기능 없어, → 개발자가 직접 조절하거나 라이브러리를 사용해야 합니다.
브라우져에서 Native로 지원하지 않아, Web App같은 경우 적합하지 않습니다.
UDP Header
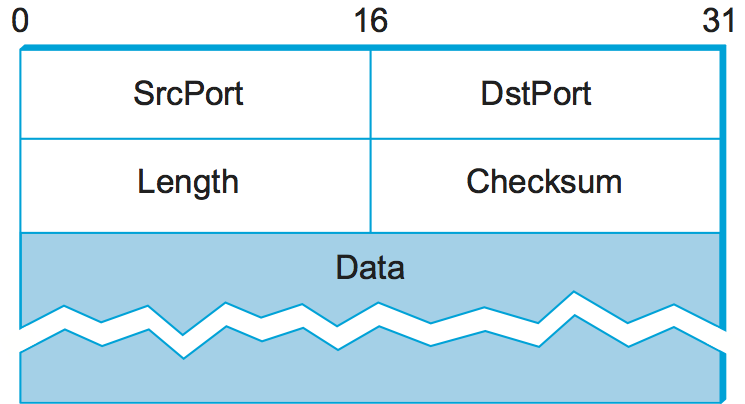 Format for UDP header
Format for UDP header
사용 사례
- 실시간 멀티미디어가 필요한 경우: VoIP, 화상회의, 실시간 스트리밍(지연 최소화)
DNS: 요청-응답이 작고, 그 과정이 빠르게 이루어져야 합니다. 재시도 로직은 클라이언트에서 처리합니다.
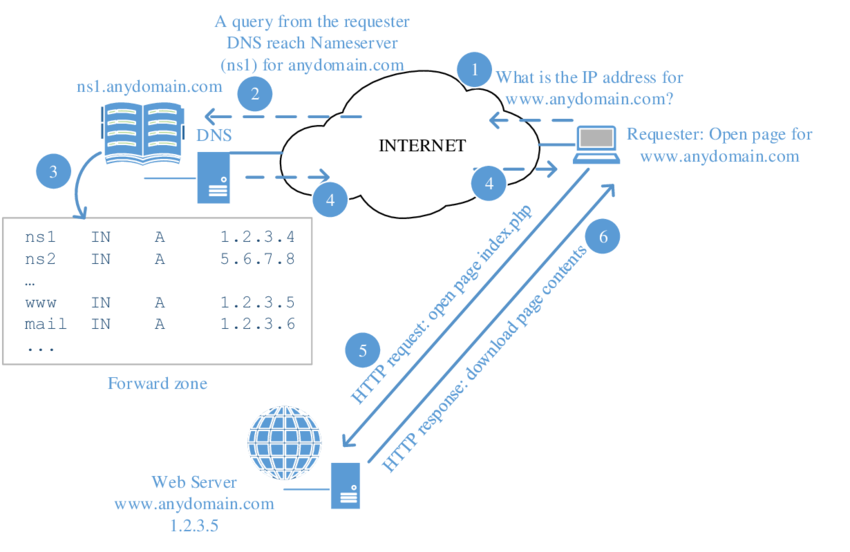 Domain Resolve 과정
Domain Resolve 과정- DHCP, SNMP: 간단한 질의응답 프로토콜
- 게임 서버: 일부 패킷 손실을 허용하지만, 높은 처리량이 요구될 때.
언제 UDP를 사용하면 되나요?
- 지연(Latency) 최소화가 우선일 때
- 일부 데이터 손실을 애플리케이션 레벨에서 허용·복구할 수 있을 때
- 연결 설정·유지에 드는 오버헤드를 줄이고 싶을 때
QUIC(Quick UDP Internet Connections)
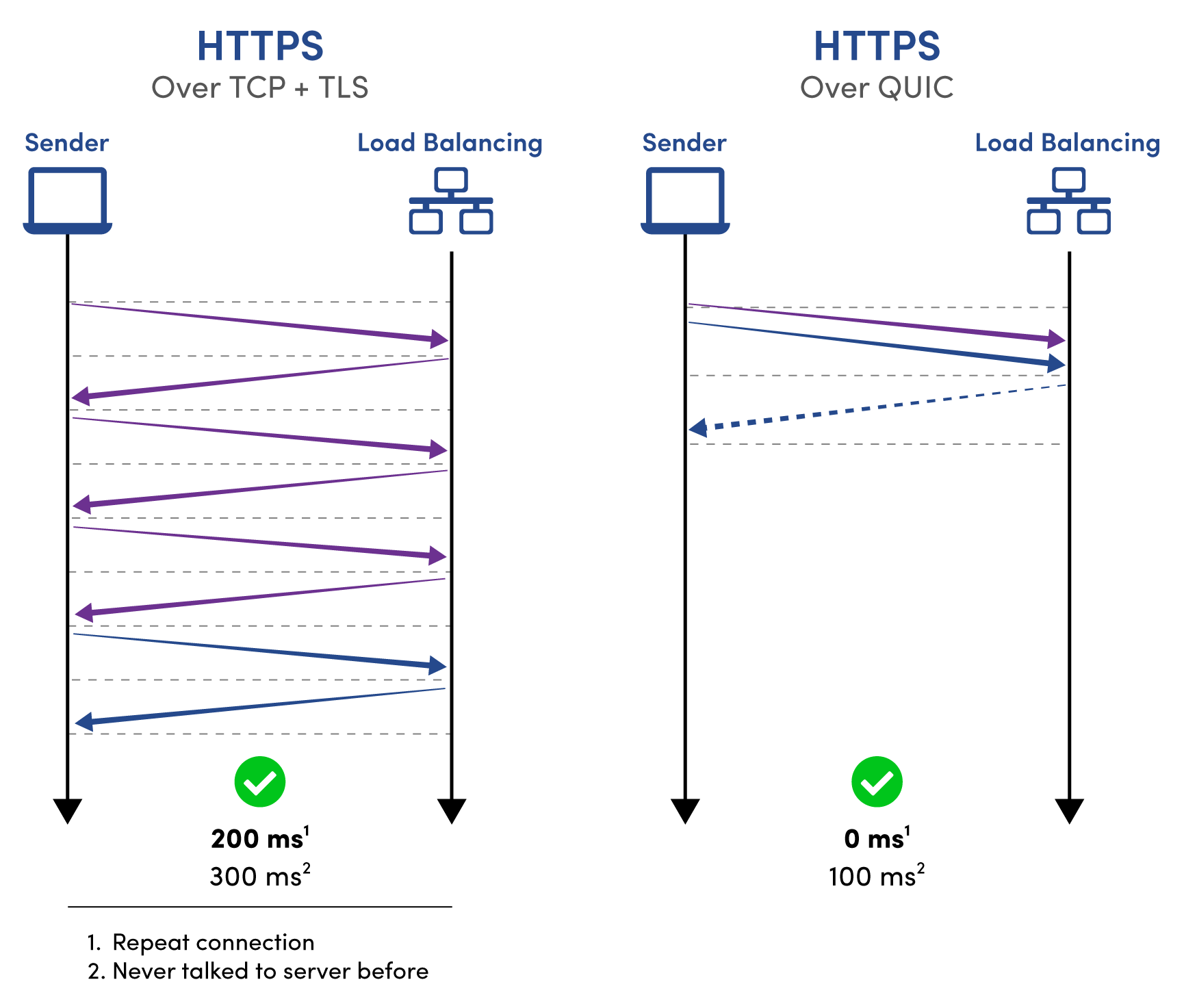 TCP + TLS와 QUIC를 비교
TCP + TLS와 QUIC를 비교
UDP위에 구현된 차세대 전송 프로토콜입니다.
UDP를 기반으로, TCP처럼 연결 지향적(end-to-end) 스트림을 제공하고, 흐름·혼잡 제어(congestion control), 신뢰성 보장(reliability) 메커니즘을 포함하고 있습니다.
이에 따라, OSI의 Transport Layer로 포함시키고 있습니다.
주요 특징
TLS와 Handshake과정 통합
TLS 1.3 암호화 핸드셰이크를 QUIC 연결 설정 과정과 결합하여, 0-RTT 또는 1-RTT로 빠른 보안 설정을 제공합니다.Multiplexing(멀티플렉싱)
하나의 QUIC 연결(connection) 위에 다중 스트림(stream)을 생성해, 개별 스트림 지연이 다른 스트림에 영향을 주지 않음Connection Migration(연결 이주)
클라이언트 IP나 포트가 바뀌어도(예: Wi-Fi→LTE 전환) 동일한 연결 ID를 유지해, 세션 끊김 없이 재개할 수 있습니다.경량 헤더와 확장성을 갖추고 있습니다.
UDP 기반으로 작동하므로 가벼운 헤더를 갖고 있고, 헤더 압축 및 확장 헤더 디자인을 통해 미래 기능 추가에 유연하게 대응합니다.User-Space에서 구현(OS 커널이 아닌, App으로 구현되어 있음)
전통적인 TCP/IP 스택처럼 운영체제 커널 내부가 아니라, 애플리케이션 라이브러리나 프로세스 레벨의 코드로 동작합니다.
덕분에 플랫폼에 독립적이며, 빠른 배포 및 업데이트가 가능합니다.
언제 QUIC를 사용하면 되나요?
- 높은 지연 민감도를 갖고 있을때: 초기 페이지 로드나 모바일 환경 전환 시 0-RTT로 빠른 연결할 수 있습니다.
- 멀티플렉싱이 필요할 때: HTTP/3으로 대량의 작은 리소스를 동시에 전송할 때 헤드-오브-라인 차단 없이 처리
- 네트워크 이주 환경이 필요할 때: 모바일 클라이언트의 IP 변경에도 세션 유지가 필요할 때
TCP와 UDP 비교
| 구분 | TCP | UDP |
|---|---|---|
| 연결 | 연결형 (3-way handshake) | 비연결형 |
| 신뢰성 | 신뢰성 (ACK, 재전송, 순서 보장) | 비신뢰성 (손실·순서 뒤바뀜 가능) |
| 흐름·혼잡 제어 | 있음 (슬라이딩 윈도우, 혼잡 제어) | 없음 |
| 헤더 오버헤드 | 최소 20바이트 (+옵션) | 8바이트 |
| 전송 속도 | 상대적으로 느림 (오버헤드·제어 기능) | 매우 빠르고 지연 낮음 |
Application Layer(Layer 7)
‘Application Layer’는 대부분의 개발자가 가장 많은 시간을 보내는 layer입니다.
전송계층(Transport Layer)의 최상단에서, 어플리케이션이 통신하는 방법을 정의합니다.
보통 Application Layer는 ‘User-space(사용자 공간)’에서 처리되는 반면에, 그 아래에 있는 Layer는 OS Kernel에서 처리됩니다.
덕분에, Application Layer는 더 유연하고, 수정이 쉽습니다. 하위계층은 변경이 어렵지만, 그 처리능력이 매우 효율적입니다.
HTTP(Hypertext Transfer Protocol)
Web에서 Data를 교환하는데 사용하는 표준 Protocol입니다.
‘Stateless Protocol’로서, 각각의 request가 독립적(서버가 이전 request를 알 필요가 없다)으로 작동합니다.
대부분의 System Design에서 유용하게 사용됩니다.
이런 부분이, ‘System Design’관점에서는 System의 표면(surface area)를 최소화할 수 있는 장점이 있습니다.
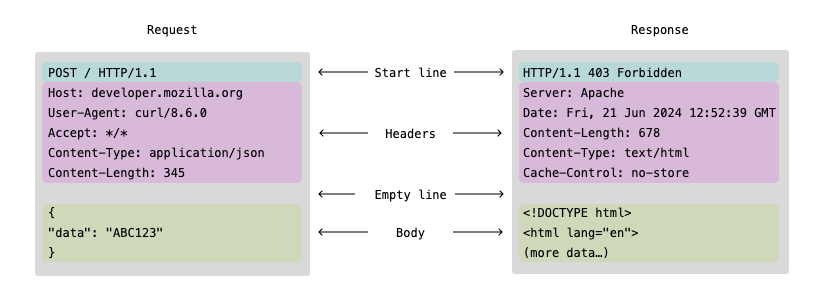 HTTP Message 예시
HTTP Message 예시
Key Concepts
HTTP는 다음과 같은 요소들로 구성됩니다.
- Request methods: GET, POST, PUT, DELETE, etc.
- Status codes: 200 OK, 404 Not Found, 500 Server Error, etc.
- Headers: Request나 Response의 Metadata역할을 합니다.
- Body: 전송되는 실제 데이터가 위치하는 곳 입니다.
HTTP Content-negotiation
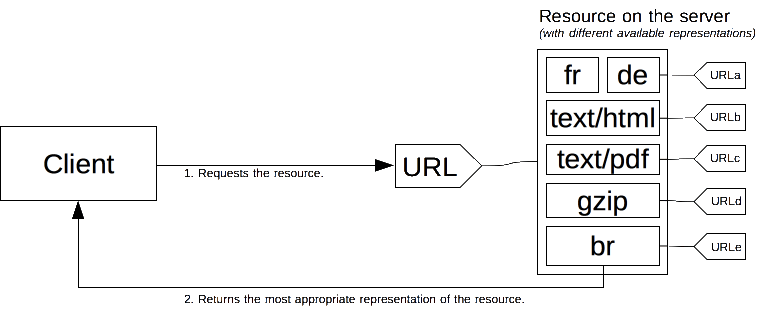 Content-negotiation 메커니즘
Content-negotiation 메커니즘
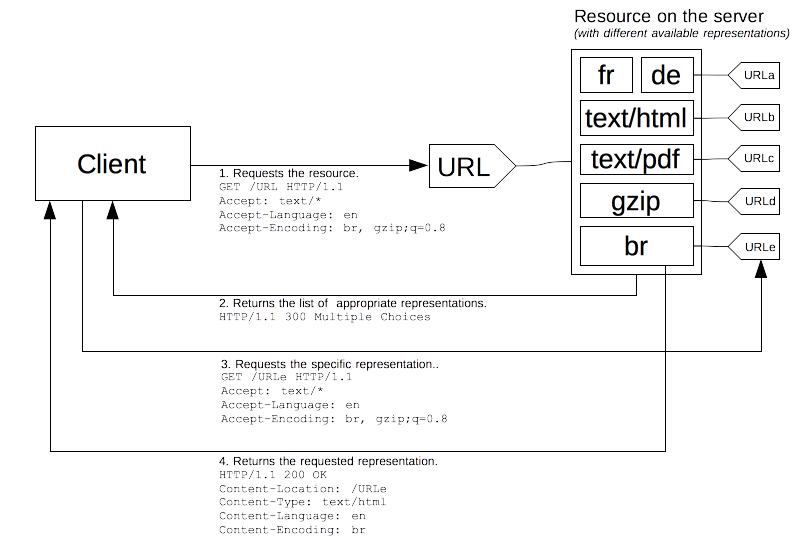 Agent-driven negotiation 메커니즘
Agent-driven negotiation 메커니즘
클라이언트가 원하는 표현 방식(미디어 타입·언어·인코딩·캐릭터 셋 등)을 명시하면, 서버가 그중 가장 적합한 표현을 골라 응답하는 메커니즘입니다.
협상(negotiation)을 위해, HTTP Header특정 Field를 사용합니다.
| 협상 카테고리 | 요청 헤더 | 예시 값 |
|---|---|---|
| 미디어 타입 | Accept | text/html, application/json;q=0.8, /;q=0.1 |
| 언어 | Accept-Language | ko-KR, en-US;q=0.7, en;q=0.5 |
| 인코딩 | Accept-Encoding | gzip, deflate, br |
| 캐릭터 셋 | Accept-Charset | utf-8, iso-8859-1;q=0.5 |
HTTP Versions
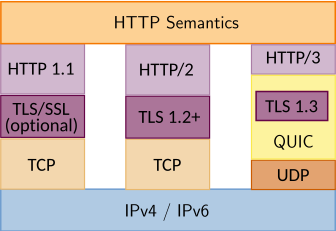 다양한 HTTP version과 그 구조.
다양한 HTTP version과 그 구조.
HTTPS(Hypertext Transfer Protocol Secure)
HTTP의 Secure Protocol입니다. Client와 Server간 데이터를 암호화된 상태로 주고 받는 프로토콜 입니다.
HTTPS는 ‘Handshake’과정을 통해 작동되며, 크게 2가지 방식의 암호화 방식을 각 목적에 따라 다르게 사용합니다.
- ‘Handshake 과정’: 비대칭키(Asymmetric encryption, 공개키) 암호화 방식을 사용하여, ‘데이터 교환’과정에서 사용할 대칭 Key를 만들어냅니다.
- ‘데이터 교환 과정’: 대칭키(Symmetric encryption) 암호화 방식을 사용합니다.
TLS Handshake
 _TLS Handshake full flow - from Wikipedia
{kind=link}
TCP Connection을 생성한 후에, TLS Handshake가 추가로 이루어집니다.(HTTP/2 이하에서, HTTP/3에선 QUIC와 결합)
HTTP와 HTTPS의 용도 구분
HTTP
내부 네트워크, 성능 테스트, 암호화가 필요 없는 간단 API 개발 등으로 사용됩니다.HTTPS
사용자 개인정보, 로그인·결제 페이지, API 토큰 전송, SEO 최적화, 브라우저 보안 정책 준수하기 위해 사용됩니다.
REST(Representational State Transfer) API
- REST는
- 웹의 특성(HTTP, URI, 미디어 타입 등)을 최대한 활용해 리소스 중심의 API를 설계하는 아키텍처 스타일입니다.
- API를 디자인하는 패러다임(Paradigm)중 하나입니다. 가장 흔하게 사용되는 패러다임입니다.
REST의 핵심 원리는, ‘Client가 resource중심으로 작업을 수행하는 경우가 많다’는 것입니다.
RESTful API Design에서, 가장 선행되어야 하는것은 ‘리소스(resource)와 그 작동(operation)을 모델링하는 것’입니다.
REST를 ‘RESTful HTTP’로서 HTTP기반의 아키텍쳐로 많이 쓰이지만, HTTP가 필수조건은 아닙니다. REST의 제약들은 이론상 HTTP뿐 아니라 SMTP, CoAP, 심지어 메시지 큐 프로토콜 위에도 적용될 수 있습니다.
주요 개념과 설계 원칙
리소스(Resource) 중심으로 설계합니다.
URI를 통해 모든 리소스를 고유하게 식별할 수 있어야 합니다.
이때, 데이터 모델 객체(예: User, Order, Product 등)는 ‘명사’로 URI에 표현합니다.
1
2
3
4
5
6
GET /users → 전체 사용자 리소스 컬렉션
GET /users/123 → ID=123 사용자의 리소스
POST /users → 새 사용자 생성
PUT /users/123 → ID=123 사용자 전체 교체
PATCH /users/123 → ID=123 사용자 일부 수정
DELETE /users/123 → ID=123 사용자 삭제
HTTP Method(Verb의 의미를 담고 있는)에 따른 ‘행위 표현’을 사용합니다.
| 메서드 | 의미 | 멱등성(Idempotent) |
|---|---|---|
| GET | 리소스 조회 | 예 (여러 번 호출해도 결과 동일) |
| POST | 리소스 생성 혹은 비멱등 작업 수행 | 아니요 |
| PUT | 리소스 전체 갱신(교체, upsert) | 예 |
| PATCH | 리소스 일부 갱신 | 아니요 (설계 따라 다름) |
| DELETE | 리소스 삭제 | 예 |
| OPTIONS | 지원 가능한 메서드 조회 | 예 |
| HEAD | GET과 동일하지만 응답 본문 없이 헤더만 반환 | 예 |
Statelessness(상태를 저장하지 않습니다.)
Server는 Client의 상태를 저장하지 않습니다.
각 요청(Request)는 독립적으로 처리되어야 하며, 각 요청에 필요한 모든 정보를 담아 보내야 합니다.
이는 서버 확장성과 신뢰성을 높여주는 핵심적인 원칙입니다. 각 요청이 독립적이라 서비스 구조가 단순해지고, ‘서버 확장’을 고려할때 제약사항이 많이 줄어듭니다.
언제 사용하나요?
REST는 인터뷰에서 기본적으로 사용하기에 좋습니다. 잘 알려져 있고, 확장가능한 시스템을 구축할때에 좋은 도구가 됩니다.
하지만, REST에서 데이터 형식으로 사용하는 JSON은 Serialization관련 작업이 매우 비효율적입니다. 이는 대부분의 어플리케이션에서 문제가 없지만(bottleneck현상), 관련 문제가 있다면, 다른 도구(gRPC)를 고려하는게 좋습니다.
GraphQL
- GraphQL은
- Facebook에서 개발하여 2015년에 오픈소스로 공개한 API 쿼리 언어이자 런타임으로, 비교적 최신의 패러다임(paradigm)입니다.
- Client로 하여금, 정확하게 자신이 원하는 데이터를 요청할 수 있게 합니다.
기존 RESTful API가 가진 여러 한계를 극복하고, 클라이언트 개발자·서버 개발자 모두의 생산성을 높여 주기 위해 고안된 쿼리 언어이자 런타임입니다.
REST의 Under-fetching과 Over-fetching 문제
Under-fetching
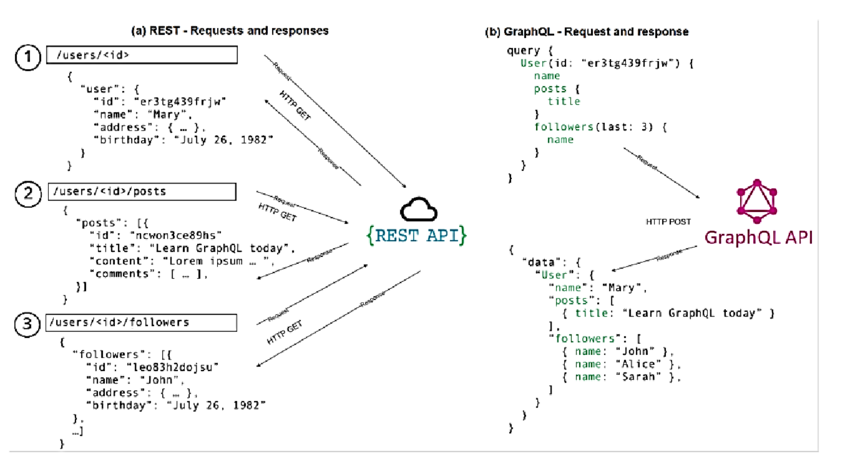 REST의 under-fetching문제와 GraphQL 비교
REST의 under-fetching문제와 GraphQL 비교
필요한 데이터가 여러 Endpoint에 흩어져 있어서, 여러 Endpoint를 호출해야하는 상황을 말합니다.
예를 들면, /users/123로 받은 응답에는 포스트 목록이 없어서, /users/123/posts를 별도로 호출해야 할 때가 많습니다.
GraphQL에서는, 하나의 요청에 여러 Entity에 대한 Query를 날릴 수 있습니다.
Over-fetching
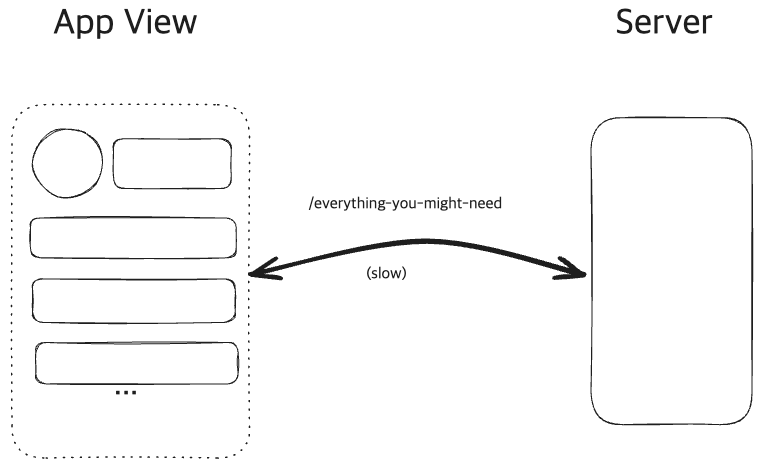 over-fetching 상황.
over-fetching 상황.
불필요한 데이터까지 포함하여, 데이터를 과다 수신하는 문제를 말합니다.
만약 Under-fetching문제를 해결하기 위해, End-point를 통합하게 된다면 불필요한 데이터 포함될 가능성이 높아집니다.
또다른 예시로, REST API에서 /users/123 같은 엔드포인트가 항상 유저의 모든 속성(이메일, 주소, 프로필 사진 URL, 가입일 등)을 반환할 때, 화면에 이름·아이디만 필요해도 불필요한 데이터를 전부 내려받아야 합니다.
GraphQL에서는, Client에서 주도적으로 Response데이터의 Filtering을 요청하여, 정확하게 필요한 데이터만 받아낼 수 있습니다.
언제 사용하나요?
Frontend팀이 빠르게 iteration할때에 적합합니다.
Frontend가 주도적으로 쿼리를 할 수 있기 때문에.클라이언트마다 서로 다른 데이터 요구사항이 있을 때
- 하지만, 이런 구조(GraphQL)는
- Backend에 Latency와 Complexity를 높이게 됩니다.
- Cache를 CDN Level에서 적극적으로 사용해야 할때는 적합하지지 않습니다.(RESTful 디자인이 Cache에 더 직관적)
gRPC(google Remote Procedure Call)
- gRPC는
- Google이 개발한 오픈소스 원격 프로시저 호출(Remote Procedure Call, RPC) 프레임워크입니다.
- 특히 마이크로서비스 환경에서 높은 성능과 명확한 인터페이스 계약을 제공합니다.
- HTTP/2와 Protobuf(Protocol Buffers)를 사용합니다.
- 특히 마이크로서비스 환경에서 높은 성능과 명확한 인터페이스 계약을 제공합니다.
](/assets/img/for-post/Networking%20Essentials/image%2017.png) gRPC를 하나의 이미지로 요약. | from bytebytego.com
gRPC를 하나의 이미지로 요약. | from bytebytego.com
Protobuf(Protocol Buffers)
Protocol Buffers(이하 protobuf)는 JSON과 같이 데이터를 Serializing(직렬화)하는 방법중에 하나입니다.
1
2
3
4
5
6
message User {
string id = 1;
string name = 2;
}
// 0A 03 31 32 33 12 08 6A 6F 68 6E 20 64 6F 65 // binary encoding된 데이터
JSON은 사람이 이해하기 쉽지만, 컴퓨터 입장에서는 연산(Serializing에 관련된)에 비효율이 있습니다.
Protobuf는 데이터를 binary로 encoding하여 외부 시스템과 교환합니다.
REST와 gRPC 작동방식 비교
](/assets/img/for-post/Networking%20Essentials/image%2018.png) REST방식과 gRPC방식의 차이 | from https://refine.dev/blog/grpc-vs-rest/#step-3-1
REST방식과 gRPC방식의 차이 | from https://refine.dev/blog/grpc-vs-rest/#step-3-1
gRPC는 REST와 달리 함수를 호출하듯 인터페이스를 설계·사용합니다.
HTTP를 기반으로하는 REST와 gRPC비교
gRPC도 HTTP/2를 기반으로 작동하는 프로토콜이기 때문에, REST와 비교하며, 내부적으로 어떤 HTTP요청을 보내는지 비교하고자 합니다.
- REST Over HTTP
1 2 3 4 5 6
POST /users HTTP/1.1 Content-Type: application/json { "name": "Alice" }
- gRPC
1 2 3 4
POST /myapp.UserService/CreateUser HTTP/2 Content-Type: application/grpc (binary payload - protobuf encoded)
gRPC의 내장기능. Client-side Load Balancing(CSLB)
](/assets/img/for-post/Networking%20Essentials/image%2019.png) Client Load Balancing 구조 | from grpc.io
Client Load Balancing 구조 | from grpc.io
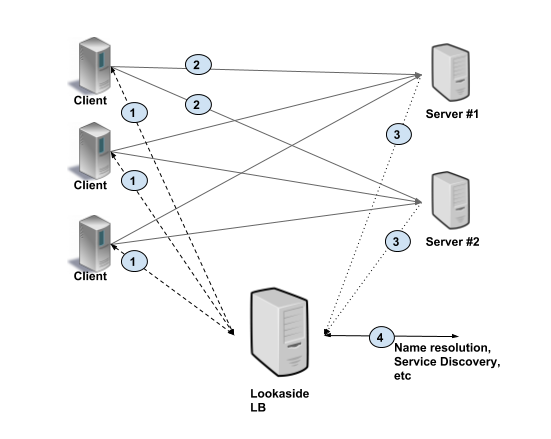 Server에 대한 정보를 미리 Discovery하고 저장하는 Loolaside LB가 있는 CSLB구조.
Server에 대한 정보를 미리 Discovery하고 저장하는 Loolaside LB가 있는 CSLB구조.
클라이언트가 호출할 서버 인스턴스를 직접 선택해 분산시키는 메커니즘입니다.
서버 풀을 중앙에서 관리하는 대신, 클라이언트가 가져온 엔드포인트 목록을 기반으로 round-robin, pick_first 같은 정책을 적용하거나, Envoy xDS·Google grpclb 같은 외부 컨트롤 플레인과 연동할 수 있습니다.
언제 사용하나요?
- gRPC는
- Strong type(강타입)특성을 통해, 에러를 사전에 검출하고
- Binary protocol을 통해 ‘JSON over HTTP’보다 훨씬 더 나은(어쩔때는 10배 이상)의 성능을 제공합니다.
- 서버와 클라이언트가 교환하는 데이터가 Binary라, 디버깅이 어렵습니다.
- Binary protocol을 통해 ‘JSON over HTTP’보다 훨씬 더 나은(어쩔때는 10배 이상)의 성능을 제공합니다.
때문에, gRPC는 MSA(Micro Service Architecture)에서 내부(internal) 서비스간 통신에서 큰 힘을 발휘합니다.
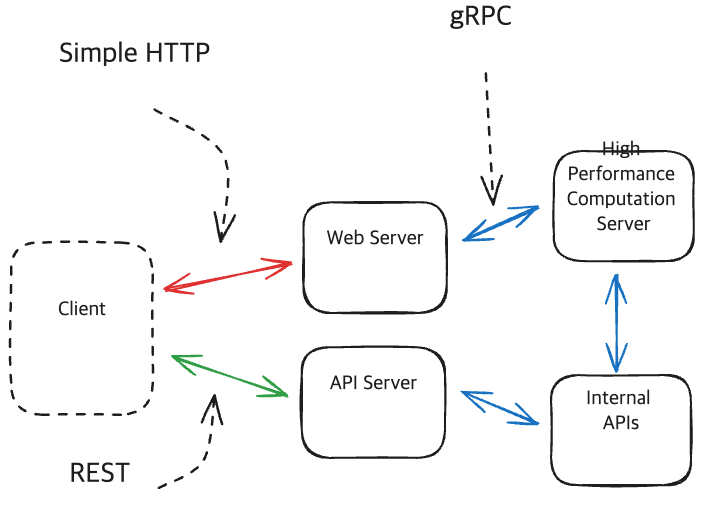 Example of Using gRPC for Internal APIs, and REST and HTTP for External
Example of Using gRPC for Internal APIs, and REST and HTTP for External
Internal Service간에는 gRPC로 구성하여 성능을 높이고, public-facing APIs(외부로 노출되는 API)는 REST를 사용해 범용성 및 호환성을 높이는 구성으로 사용합니다.
System Design Interview에서는 내·외부모두 REST로 구성해도 괜찮습니다. 다만, Interviewer나 과제 자체가 특별한 요구사항이 있다면 고려해봐야 합니다.
SSE(Server-Sents Events)
보통의 request/response 스타일의 API와는 다르게, Server가 Client에 데이터를 ‘push’하는 프로토콜 입니다.
서버가 클라이언트(브라우저)로 단방향(Stream)으로 실시간 이벤트(데이터)를 푸시하는 기술이며,
TCP연결을 전제로 하기 때문에, HTTP/1.1 혹은 HTTP/2 위에서 동작합니다.
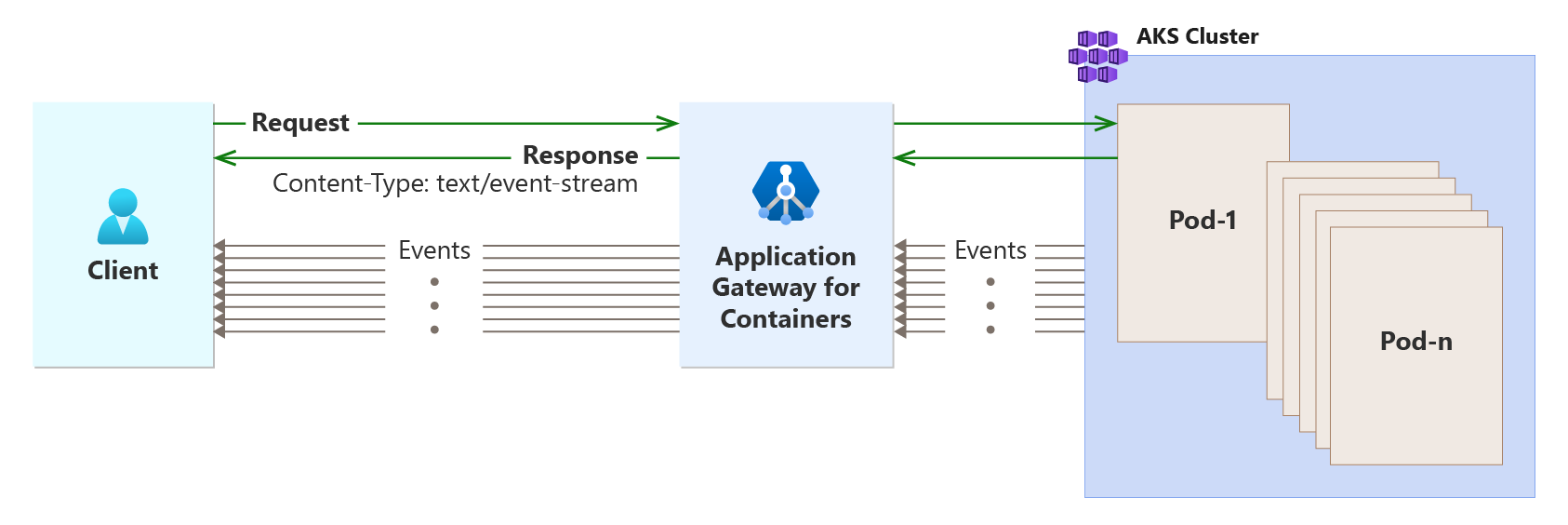 SSE Flow with Gateway
SSE Flow with Gateway
작동 방식
Client에서 ‘Event Stream’을 생성하기 위한 요청을 보내고, 서버에서는 해당 Stream을 계속 유지하여 Response를 보냅니다.
- 클라이언트 연결(EventSource 생성)
브라우져(혹은 JS환경)에서 EventSource 객체를 만듭니다.1
const es = new EventSource('/events');
내부적으로는, 아래의 과정을 거치게 됩니다.
- GET /events HTTP/1.1 요청
- 헤더에 Accept: text/event-stream 자동 추가
- TCP 3-way 핸드셰이크 → TLS(HTTPS인 경우) → HTTP 요청
- 서버 응답(스트리밍 시작)
서버는 HTTP Response를 끊임없이 유지합니다.1 2 3 4
HTTP/1.1 200 OK Content-Type: text/event-stream Cache-Control: no-cache Connection: keep-alive
이어서 텍스트 프레임을 차례로 전송합니다.
1 2 3 4 5 6
data: 첫 번째 메시지 내용\n \n data: 두 번째 메시지 내용\n id: 42\n event: customEvent\n \n
- data: 한 줄에 메시지 내용을 기록
- 빈 줄(\n\n)이 하나의 이벤트 단위(Record) 를 구분
- id: 로 이벤트 식별자 지정 → 재연결 시 Last-Event-ID 헤더로 이어받기
- event: 로 커스텀 이벤트 이름 지정(클라이언트 addEventListener(‘customEvent’,…))
- retry: 으로 재연결 대기(ms) 권고 가능
- 클라이언트에서 이벤트 처리
1 2 3 4 5 6 7 8 9 10
// 기본 Event 처리 방식 es.onmessage = e => { console.log("이벤트 데이터:", e.data); }; // 혹은 커스텀 이벤트 Lister를 통해 처리 es.addEventListener('customEvent', e => { console.log("customEvent:", e.data); });
언제 사용하나요?
Client에게 Notification이나 Event를 보내야 할때 사용합니다.
- 주식·환율 시세 업데이트
- 라이브 스포츠 스코어보드
- 로그 스트리밍 및 모니터링
- 실시간 피드(뉴스·소셜 피드)
- 실시간 알림(Notifications)
WS(WebSockets), WSS(WebSockets Secure)
- WS는
- 웹 환경에서 양방향(full-duplex) 실시간 통신을 가능하게 해 주는 프로토콜로, HTTP의 한계를 넘어 클라이언트와 서버가 자유롭게 메시지를 주고받을 수 있도록 설계되었습니다.
- TCP 기반으로 동작합니다.
- 연결을 계속 유지(Keep-alive)하여 실시간 이벤트를 전달할 때에 적합합니다.
- TCP 기반으로 동작합니다.
연결 과정
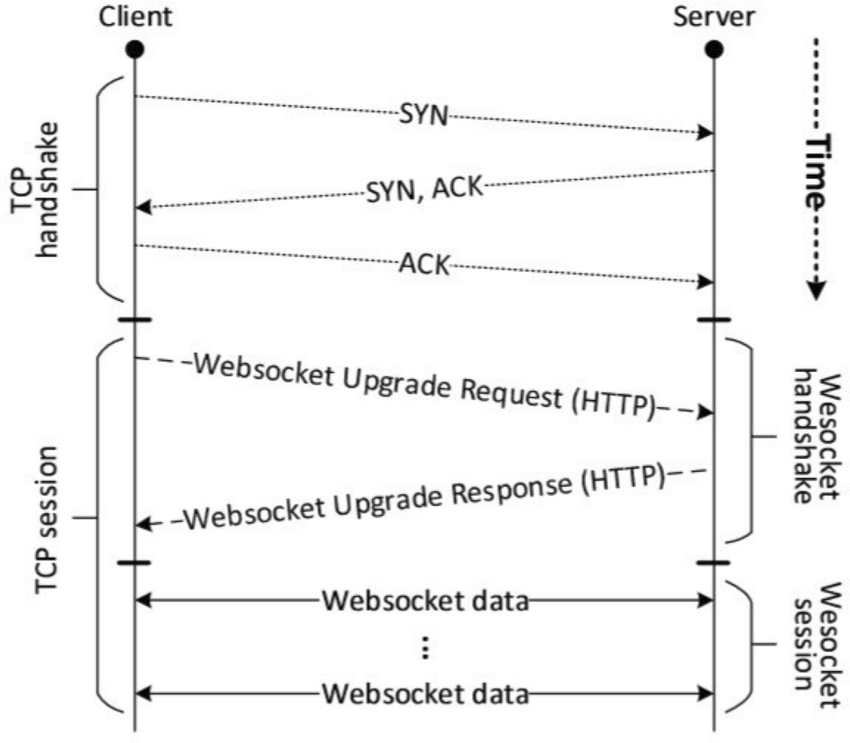 WebSocket over TCP Sequence diagram | from researchgate.net
WebSocket over TCP Sequence diagram | from researchgate.net
- Client 요청
Client에서 TCP연결을 생성하고, HTTP요청을 통해, HTTP연결을 Websocket으로 전환하는 요청을 보냅니다.1 2 3 4 5 6
GET /chat HTTP/1.1 Host: example.com Upgrade: websocket Connection: Upgrade Sec-WebSocket-Key: <base64-encoded nonce> Sec-WebSocket-Version: 13
- Server 응답
HTTP를 WebSocket으로 전환하는 것을 승인합니다.1 2 3 4
HTTP/1.1 101 Switching Protocols Upgrade: websocket Connection: Upgrade Sec-WebSocket-Accept: <SHA1&base64 of nonce>
언제 사용하나요?
high-frequency, persistent, bi-directional communication이 필요할 때 사용합니다.
- 채팅 어플리케이션
- 실시간 협업 툴
- 온라인 멀티플레이 게임
- 라이브 대시보드
- 경매(옥션), 스포츠 베팅 등 실시간 입찰/배팅
System Design Interview에서는, WebSocket을 사용하기 전에 반드시 “왜 필요한지”설명해야 합니다.
WebSocket은 강력한 기능을 제공하지만, 이를 지원하고 유지하는 인프라 비용이 많이 들고, 특히 대규모 연결 시 상태 저장(stateful) 연결의 오버헤드로 인해 설계에 상당한 조정이 필요할 수 있습니다.
WebRTC(Web Real-Time Communication)
- WebRTC는
- 브라우저나 애플리케이션 간에 네이티브 P2P(peer-to-peer) 오디오·비디오·데이터 스트림을 전달하기 위한 오픈 웹 표준입니다.
- 별도의 플러그인 없이, 자바스크립트 API와 브라우저 내장 기능만으로 실시간 통신 기능을 구현할 수 있습니다.
- 다른 프로토콜과 다르게 UDP기반입니다.
- 별도의 플러그인 없이, 자바스크립트 API와 브라우저 내장 기능만으로 실시간 통신 기능을 구현할 수 있습니다.
WebRTC의 구조 및 컴포넌트
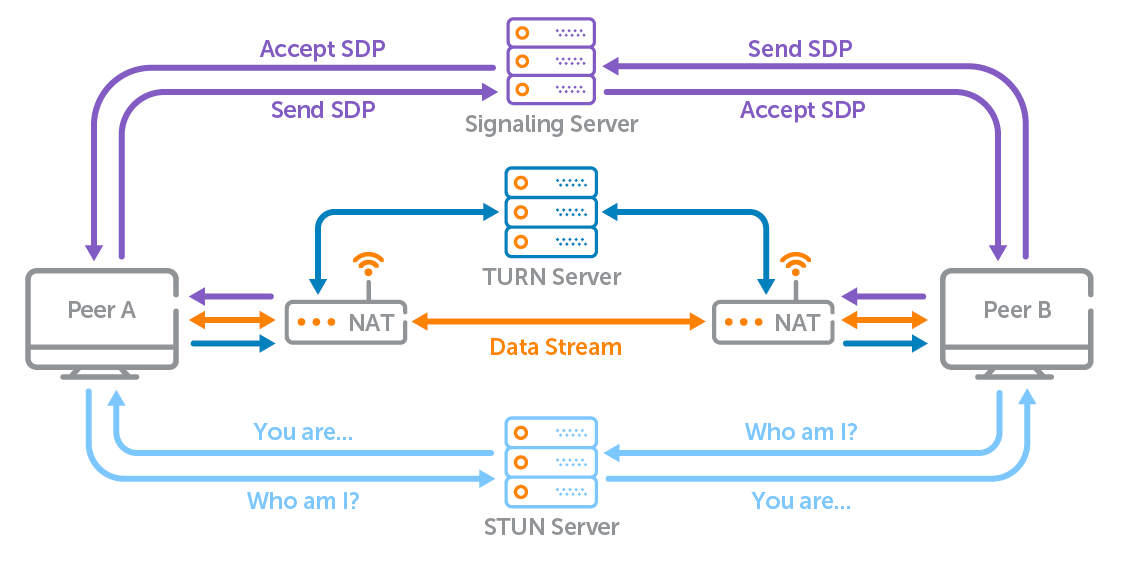 WebRTC 구조
WebRTC 구조
대부분의 Client는 inbound connection을 허용하지 않고(보안 문제로), NAT뒤에 있기 때문에, Client끼리 직접 연결하는것은 어려운 과제입니다.
WebRTC는 여러 컴포넌트를 통해 이를 극복합니다.
Signaling Server (신호 중계 서버)
피어 간에 SDP(Session Description Protocol) 와 ICE 후보(candidate) 를 교환하기 위한 임시 채널입니다. 즉, 두 Client사이의 연결을 만드는 초기 협상단계에 사용합니다.
단, 미디어·데이터 자체는 여기서 통과하지 않습니다.STUN(Session Traversal Utilities for NAT)
“내가 밖에서 어떻게 보이는지”(public IP, NAT 매핑)를 알려줍니다.
이를 통해, Peer-to-peer 연결을 가능하게 합니다.TURN(Traversal Using Relays around NAT)
피어 간 직접 연결(hole punching) 실패 시, 중계(relay)로 동작합니다.
WebRTC Connection 수립 4단계
- Client는 Signaling Server에 연결하여 peer에 대한 정보를 얻습니다.
- Client는 STUN 서버에 접속하여 공용 IP 주소와 포트를 얻습니다.
- Client는 Signaling Server를 통해 이 정보를 서로 공유합니다.
- Client는 직접 P2P 연결을 설정하고 데이터 전송을 시작합니다.
WebRTC의 기반이 되는 UDP Hole Punching
UDP 홀 펀칭(UDP Hole Punching)은 양쪽이 NAT 뒤에 있어도 서로 직접 UDP 패킷을 주고받을 수 있게 해 주는 대표적인 NAT 트래버설(Traversal) 기법입니다.
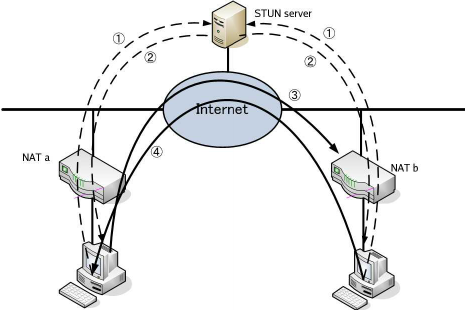 UDP Multi Hole Punching
UDP Multi Hole Punching
Q: 필요한 이유?
A: 대부분의 홈 라우터나 기업 방화벽은 사설 IP → 인터넷 방향(아웃바운드) 패킷만 허용하고,
인터넷 → 사설 IP(인바운드)는 기본적으로 차단합니다.
따라서 NAT 뒤에 있는 두 호스트 A, B가 서로 통신하려면, NAT 장비의 “구멍(hole)”을 동시에 뚫어줘야 합니다.
언제 사용하나요?
WebRTC는 브라우저나 애플리케이션 간에 플러그인 없이 직접 P2P(피어투피어)로 오디오·비디오·데이터를 주고받아야 할 때 사용합니다.
- 실시간 화상·음성 통화(Voice/Video Chat)
- 라이브 스트리밍 & 브로드캐스트
- 파일 전송 & 데이터 교환
- 스크린 공유 & 원격 제어
- 실시간 협업 도구
실시간 협업 도구의 결과물을 저장하기 위해, CRDT(Conflict-free replicated data type)을 함께 사용하기도 합니다.
- 실시간 게임 & IoT 제어
Load Balancing
서비스가 성장하고 트래픽이 기하급수적으로 늘어나면서, System을 설계할때, ‘Scalability를 고려한 설계’가 중요한 부분중 하나가 되었습니다.
여기서는 Scaling의 종류와 동적으로 생성된 서버와 연결하기 위한 ‘Load Balancer’에 대해서 알아봅니다.
Scaling
Scaling에는 2가지 옵션이 있습니다.
- 더 성능이 좋은 서버(Vertical Scaling)
- 더 많은 서버(Horizontal Scaling)
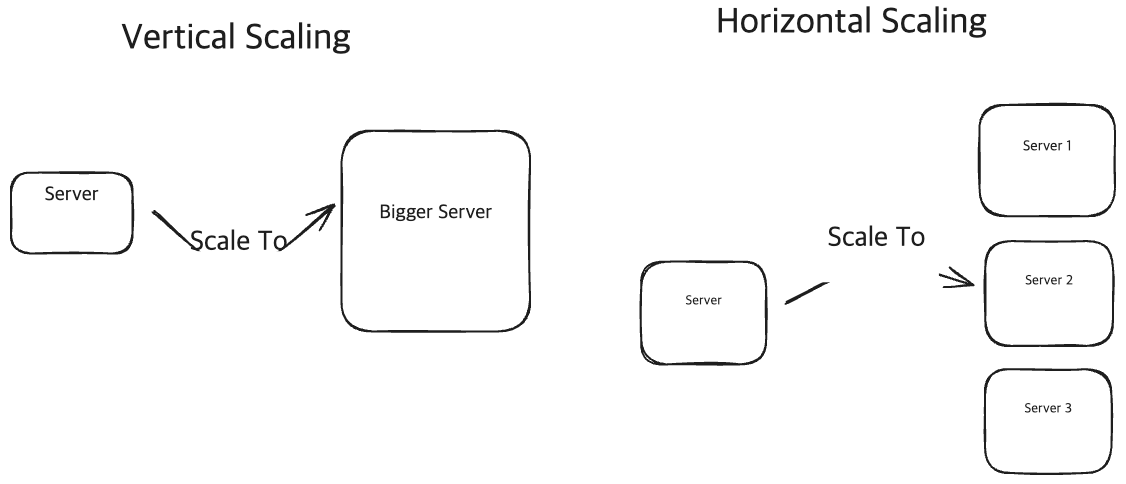 Vertical vs Horizontal Scaling
Vertical vs Horizontal Scaling
항상 ‘Horizontal Scaling’만이 답이 아니며, 상황에 따라 적절하게 예측하여 Scaling하는게 중요합니다.
실제 Interview에서는 ‘Horizontal Scaling’에 대한 시나리오가 더 자주 나옵니다.
Client-Side Load Balancing(CSLB)
Server에 대한 정보를 미리 Discovery하고 저장하는 Loolaside LB가 있는 CSLB구조.
- CSLB에서 Client는
- 스스로 어떤 서버에 연결할지 선택하게 됩니다.
- 보통, 서버 목록을 요청해서 Client에서 들고 있다가, 목록의 서버중 하나에 요청을 보냅니다.
- Server에 변화가 있는경우를 대비해, 주기적으로 polling하거나 update를 Push 받아야 합니다.
- 보통, 서버 목록을 요청해서 Client에서 들고 있다가, 목록의 서버중 하나에 요청을 보냅니다.
- CSLB는
- Client입장에서 가장 빠른 서버를 선택할 수 있습니다.
- 중간에 요청 자체를 라우팅해주는 역할이 없다보니, 매우 효율적이고 빠릅니다.
CSLB의 Examples
Redis Cluster
](/assets/img/for-post/Networking%20Essentials/image%2025.png) Redis Cluster에서 Key에 따른 Client Load Balancing | from aeraki.net
Redis Cluster에서 Key에 따른 Client Load Balancing | from aeraki.net
Redis Cluster에서는 Key를 Hash한 결과를 통해, 어떤 shard(여러 Node에 분산되어 있는 데이터)에 데이터가 포함되어 있는지 구분하고, 해당 노드로 요청을 보냅니다.DNS
Domain을 Resolve하는 과정에서, ‘DNS Resolver’가 CSLB를 수행합니다.
만약 아래와 같이service.example.com에 대한 A/AAAA 다중 레코드를 구성한다면,1 2 3
service.example.com. 300 IN A 10.0.0.1 service.example.com. 300 IN A 10.0.0.2 service.example.com. 300 IN A 10.0.0.3
아래와 같이. 요청마다 Record List의 순서가 바뀌어서 응답하게 됩니다.
1 2 3 4 5 6 7 8 9
$ dig +short service.example.com 10.0.0.2 10.0.0.3 10.0.0.1 $ dig +short service.example.com 10.0.0.1 10.0.0.2 10.0.0.3
이렇게 IP 목록의 순서가 변하면서, CSLB가 작동하게 됩니다.
언제 사용하나요?
- 우리가 통제해야하는 Client가 적을때.
- 많은 수의 Client가 있어도, ‘slow update(e.g. DNS)’를 견딜 수 있을때.
- 주로 internal service간의 통신에서 사용됩니다.
Dedicated Load Balancers
- Dedicated Load Balancer는
- 애플리케이션 서버가 아니라 오직 트래픽 분산(로드 밸런싱) 목적으로 배포되는 전용 장치나 서비스입니다.
- 크게 하드웨어 어플라이언스와 소프트웨어(HAProxy, nginx, Apache)/클라우드 서비스 형태가 있습니다.
Layer 4 Load Balancer (이하 NLB, Network Load Balancer)
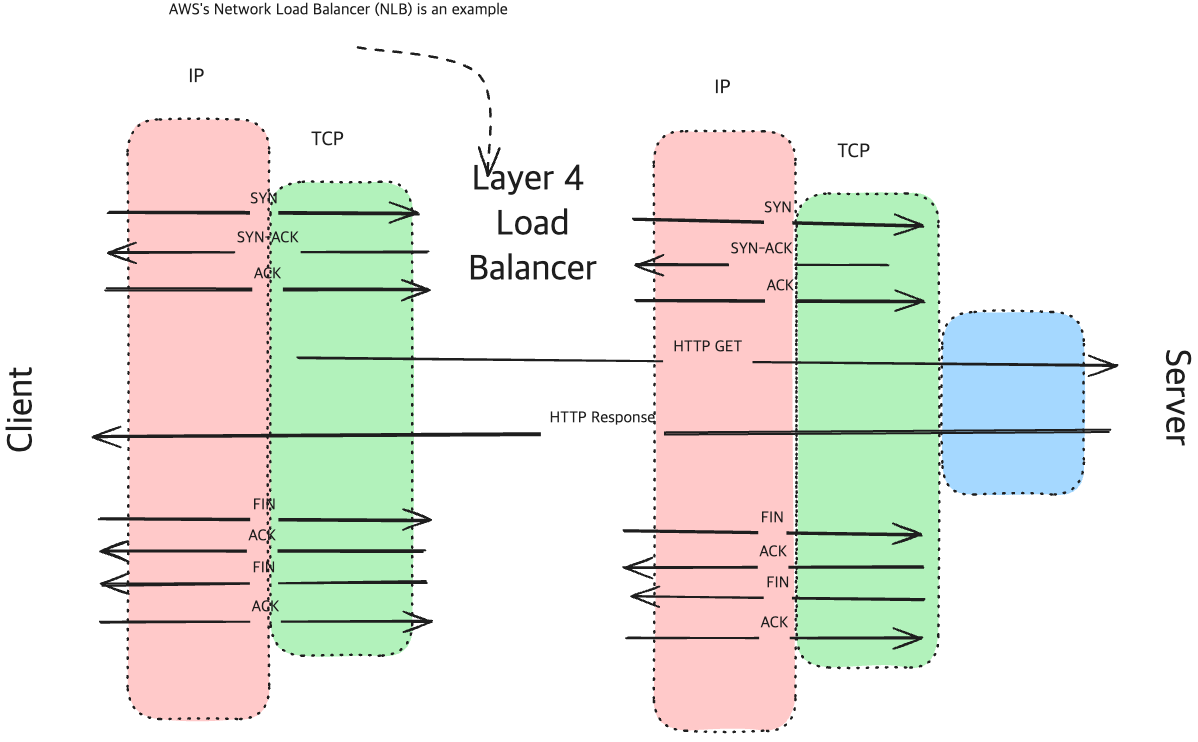 Simple HTTP Request with L4 Load Balancer
Simple HTTP Request with L4 Load Balancer
- NLB는
- Transport Layer(TCP/UDP, Layer 4)에서 작동하는 Load Balancer입니다.
- Packet의 컨텐츠에 해당하는 부분을 보지 않고, Transport Layer의 도구(IP Addr, Port Num)으로만 Routing을 수행합니다.
특징
- Client와 Server사이에서 ‘Persistent TCP Connection(KeepAlive으로 알려진 connection)’을 유지합니다.(WebSocket같은)
- 빠르고 효율적입니다.(Packet을 최소한으로만 살펴보기 때문에)
- Application Data를 기준으로 Routing 하지 못합니다.
- 빠른 성능이 목적일때 사용합니다.
- TCP를 사용하기 때문에, 이를 사용하여 상위 계층에서 통신할 수 있습니다.
NLB를 통해, TCP연결이 생성된다면, 해당 연결을 재사용한다면, balancing이 발생하지 않습니다.
즉, Connection을 생성하는 시점에만 Balancing이 발생합니다.생성된 Connection을 통해, 요청을 보내면 Connection과 연결된 Server에서만 처리합니다.
언제 사용하나요?
- WebSocket Connection을 사용할때.
- ‘persistent connection’이 필요할때.
- Layer 7 LB보다 너 높은 성능이 필요할때.
Interview에서는 WebSocket을 써야하는 경우가 아니라면, L7 LB가 대부분 더 적합합니다.
Layer 7 Load Balancer (이하 ALB, Application Load Balancer)
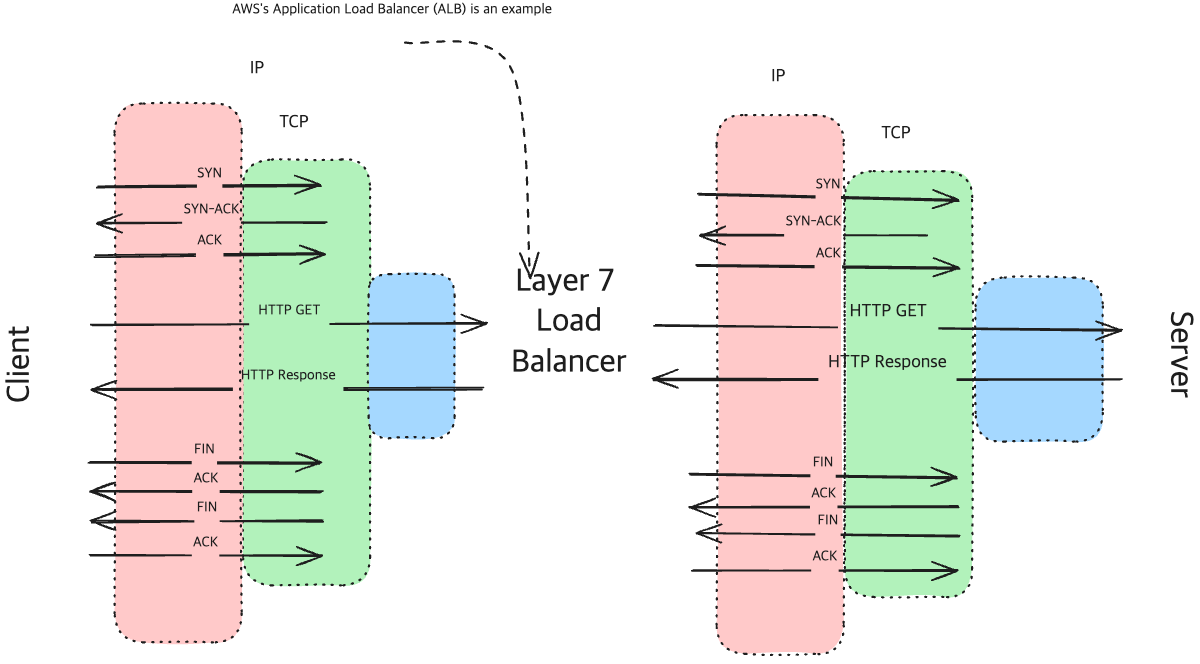 Simple HTTP Request with L7 Load Balancer
Simple HTTP Request with L7 Load Balancer
- ALB는
- Application Layer에서 작동하는 load balancer입니다.
- Layer 7의 컨텐츠를 직접 들여다 보고, Routing할 수 있습니다.
특징
‘incoming(들어오는) connection’을 끊고, Backend Server와 새로운 connection을 생성합니다.
(Client와의 Connection과 Server의 Connection을 끊어서 작동한다는 뜻)
이를 기반으로 ALB를 통해 통합된 TLS설정을 할 수 있습니다.- request의 내부 컨텐츠(URL, headers, cookies, etcd)를 기반으로 라우팅할 수 있습니다.
- NLB보다 더 CPU Intensive합니다. (Packet에 대해 더 많이 들여다 보기 때문에)
- 더 많은 기능과 유연성(라우팅 방법에 대한)을 제공합니다.
cookie데이터를 기반으로 특정유저가 같은 서버에만 연결되도록 할 수 있습니다.
- HTTP기반의 traffic에 적합합니다.
언제 사용하나요?
HTTP 기반의 traffic을 다룰때, 대부분의 경우에 적합합니다.(WebSocket은 제외)
Health Checks and Fault Tolerance
Load Balancer(이하 LB)가 traffic을 분배할때, 이를 완벽하게 수행하기 위해, Backend Server에 대한 모니터링 책임을 갖고 있습니다.
LB는 ‘Health Check‘를 통해, 자동화된 failover를 구현합니다.(High availability 제공)
‘Health Check’는 다양한 프로토콜(Protocol)을 사용하여 구성할 수 있으며, 일반적으로는 TCP나 HTTP요청을 사용합니다.
TCP보다는 HTTP가 Application수준의 Availability를 측정하기에 적합하기 때문에, HTTP를 더 많이 사용합니다.
아래는, AWS ALB Health Check Configuration 예시입니다.
1
2
3
4
5
6
7
8
Protocol: HTTP
Path: /healthz
Port: traffic port
Interval: 10 seconds
Timeout: 5 seconds
Healthy Threshold: 3
Unhealthy Threshold: 2
Matcher: 200–399
Load Balancing Algorithms
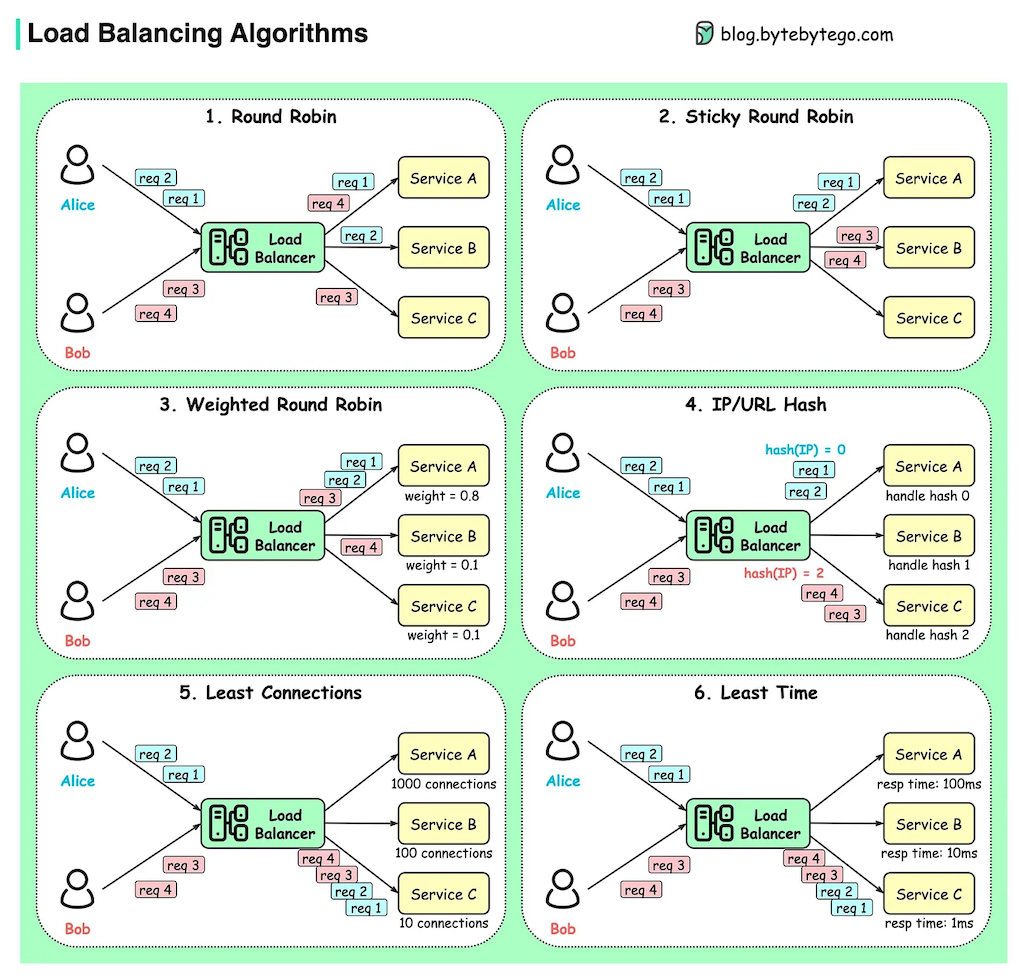 Load Balancing 알고리즘 종류 | from blog.bytebytego.com
Load Balancing 알고리즘 종류 | from blog.bytebytego.com
적용
실제로 적용할때는, 다음과 같은 LB들을 사용합니다.
- Hardware Load Balancers: Physical devices like F5 Networks BIG-IP
- Software Load Balancers: HAProxy, NGINX, Envoy
- Cloud Load Balancers: AWS ELB/ALB/NLB, Google Cloud Load Balancing, Azure Load Balancer
Interview에서, 만약 LB의 처리량(throughput)이 매우 크다면, Hardware LB를 사용하는걸 언급하는게 좋습니다.
Regionalization and Latency
글로벌 서비스에서, 서버는 전 세계에 걸쳐 분포되어 있습니다.
이때 필연적으로 발생하는 ‘물리적 거리’ 때문에, 많은 Latency가 만들어집니다.
빛은 진공 상태에서 광속의 약 2/3인 약 200,000km/s로 광섬유 케이블을 통해 이동합니다. 즉, 뉴욕과 런던(약 5,600km)을 왕복하는 데는 신호 전파의 물리적 특성만으로 이론적으로 약 56ms의 지연 시간이 발생합니다. 이러한 물리적 제약 때문에 저지연 애플리케이션에는 지리적 분포가 필수적입니다.
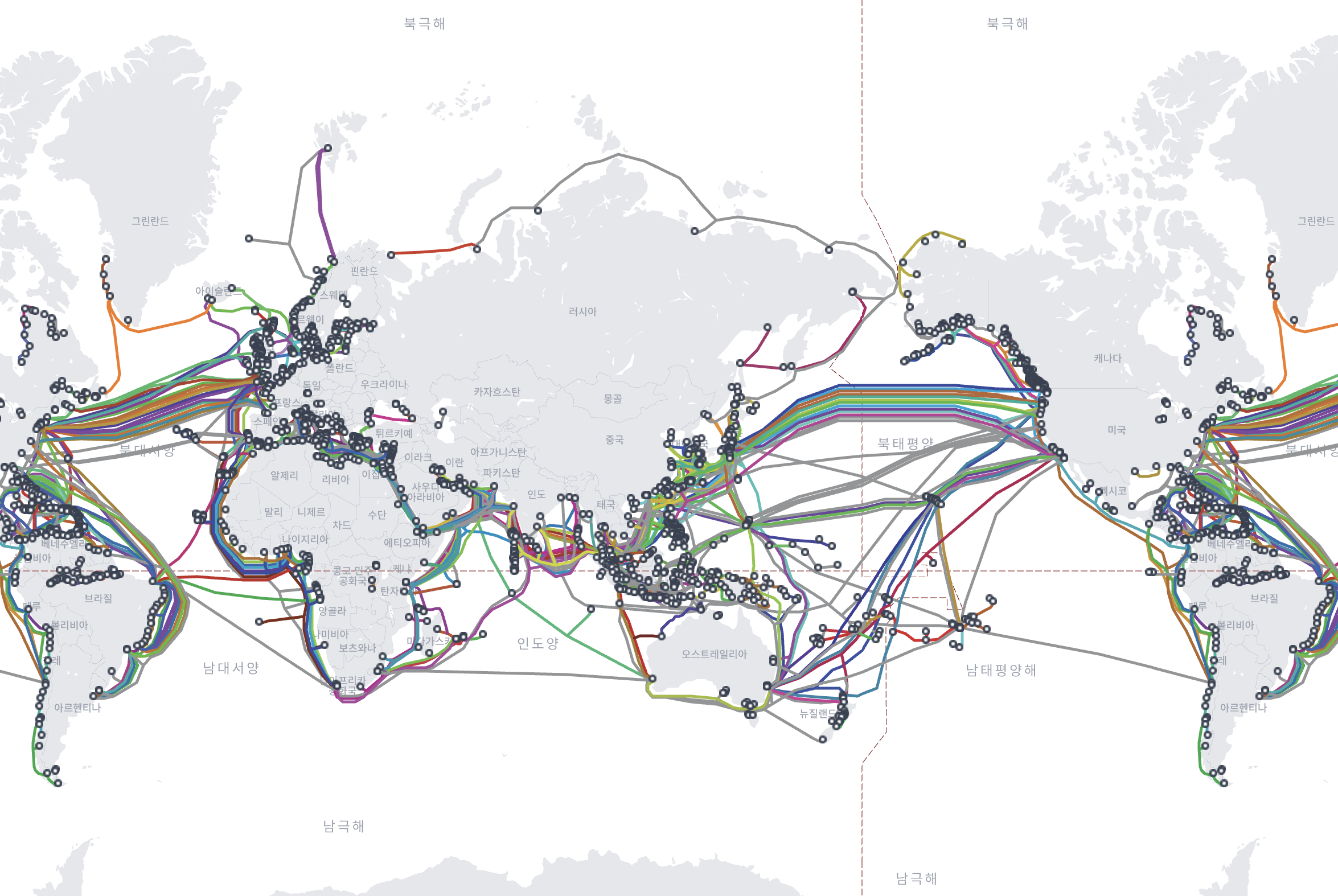 전세계 해저케이블 분포 | from submarinecablemap.com
전세계 해저케이블 분포 | from submarinecablemap.com
이런 물리적인 한계 때문에, 어느정도의 Latency를 피할 수 없는 부분이 있습니다.
하지만, 이를 개선하기 위한, 몇가지 최적화(optimization) 전략을 소개합니다.
CDNs(Content Delivery Networks)
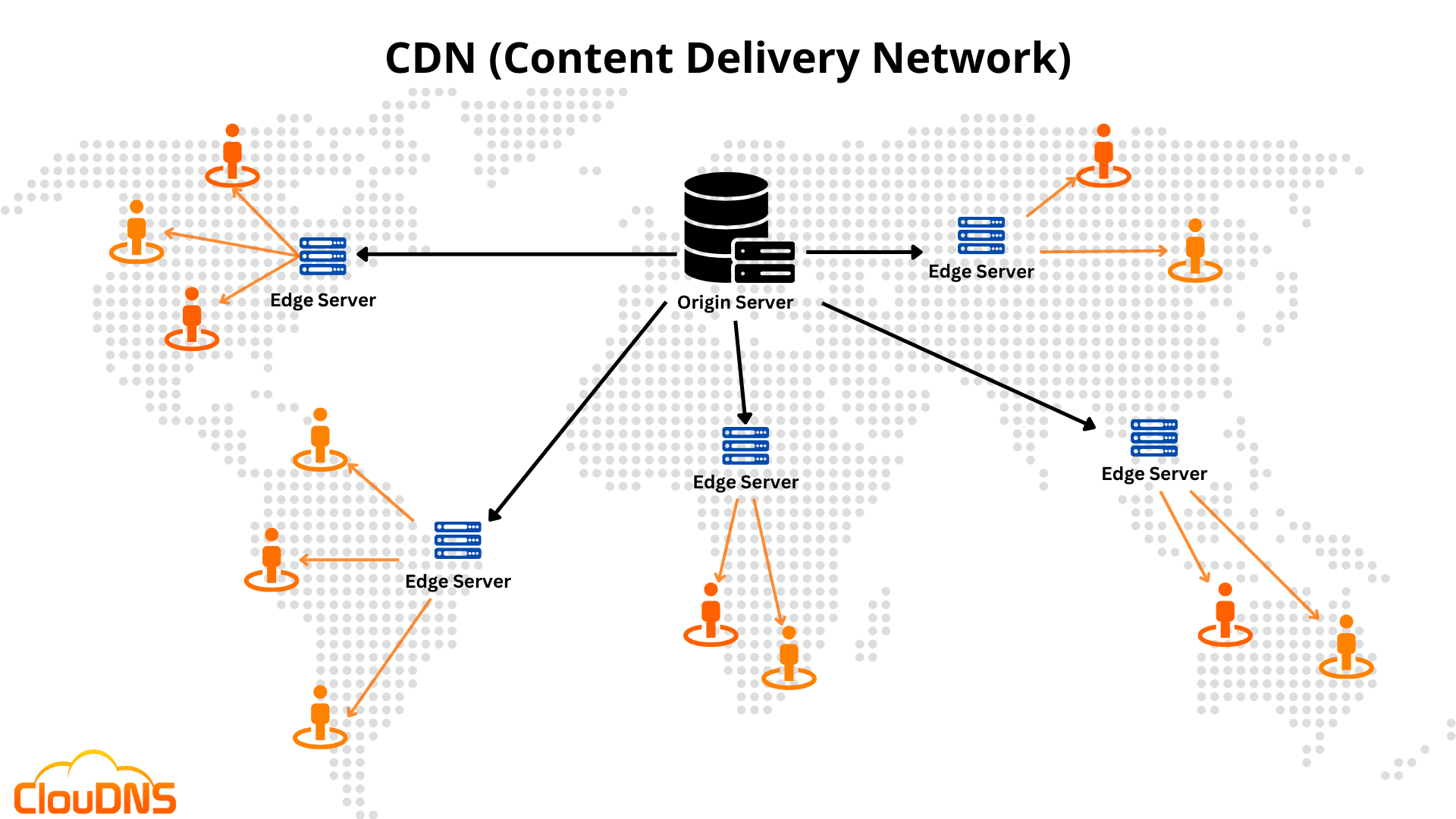 CDN Description | from cloudns.net
CDN Description | from cloudns.net
전 세계에 분산된 캐시 서버(Edge 서버)를 이용해 사용자에게 가장 가까운 위치에서 정적·동적 콘텐츠를 빠르게 전달하는 서비스입니다.
이는 캐싱(Caching) 덕분에 가능합니다.
데이터가 많이 변경되지 않거나 자주 업데이트될 필요가 없다면, 엣지 서버에 캐싱하여 반환할 수 있습니다. 이는 이미지, 비디오 및 기타 자산과 같은 정적(static) 콘텐츠에 특히 효과적입니다.
Interview에서, CDNs을 자주 보게 될것입니다. 데이터가 Cacheable하고 글로벌 환경에서 빠르게 응답해야 한다면, CDN은 좋은 전략이 될겁니다.
Regional Partitioning
서비스에 따라, 모든 데이터가 Global단위로 공유될 필요가 없을 수 있습니다. 즉, Regional하게 사용될 수 있습니다.
이를 이용하여, 지역(Region, 인접 도시들을 묶은 개념)별로 데이터센터를 분리하여 운영하면, Latency를 줄이면서 데이터 유지비용도 줄일 수 있습니다.
Handling Failures and Fault Modes
우리는 종종 ‘server crash’, ‘solar flares(태양 표면 폭발의 전자기파로 인해 디지털 장비가 쟁이를 일으키곤 합니다.)’로 인해, 시스템 장애를 겪곤 합니다.
여기서는, 우리는 이런 ‘시스템의 실패(Failures)를 어떻게 다뤄야 하는지’를 다룹니다.
“네트워크는 안정적이다”라는 생각은, 분산 시스템에서 가장 위험한 가정입니다.
네트워크는 언제든 실패할 수 있으며, 이를 염두해두어야 합니다.
Timeouts and Retries with Backoff
실패를 처리하는 가장 기본적인 방법은, Timeout과 Retry를 사용하는 것입니다.
만약, 요청을 처리하는데에 너무 오래 걸린다면, Timeout처리 이후에 Retry로 다시 시도하면, 이 요청은 성공할 수 있습니다.(특히, 분산처리 환경이라면 더욱)
이 과정에서 API의 Idempotency(멱등성)이 필요합니다.
Idempotency(멱등성)
같은 요청을 여러 번 처리해도 “결과가 처음 한번 처리한 것과 동일” 하도록 보장하는 특성을 말합니다.
즉, Retry를 수행해도, 처음 요청한것과 동일하다는 것이 보장된다는 얘기입니다.
장애가 발생해도, 이 요청을 다시 보냄으로서 처음 요청과 동일한 결과를 얻을 수 있습니다.
읽기 요청(GET)의 Idempotency
GET 요청은 서버 상태를 변경하지 않으므로, 몇 번 호출해도 문제가 없습니다. 이 경우, ‘Idempotency’를 구현하기 쉽습니다.쓰기 요청(POST 등)에서의 Idempotency 보장
‘쓰기 요청’의 Idempotency를 보장하는 것은 더 어렵고 복잡합니다.Idempotency Key를 도입합니다.
클라이언트가 요청에 고유 키(예: 사용자ID+날짜)를 함께 전송하여, Server가 요청을 구분할 수 있게 합니다. 이를 통해, 서버가 중복 요청을 인식할 수 있습니다.서버 처리 로직
같은 키의 요청이 이미 처리(혹은 처리 중)된 경우 재실행 없이 결과만 반환합니다.
Backoff Strategy
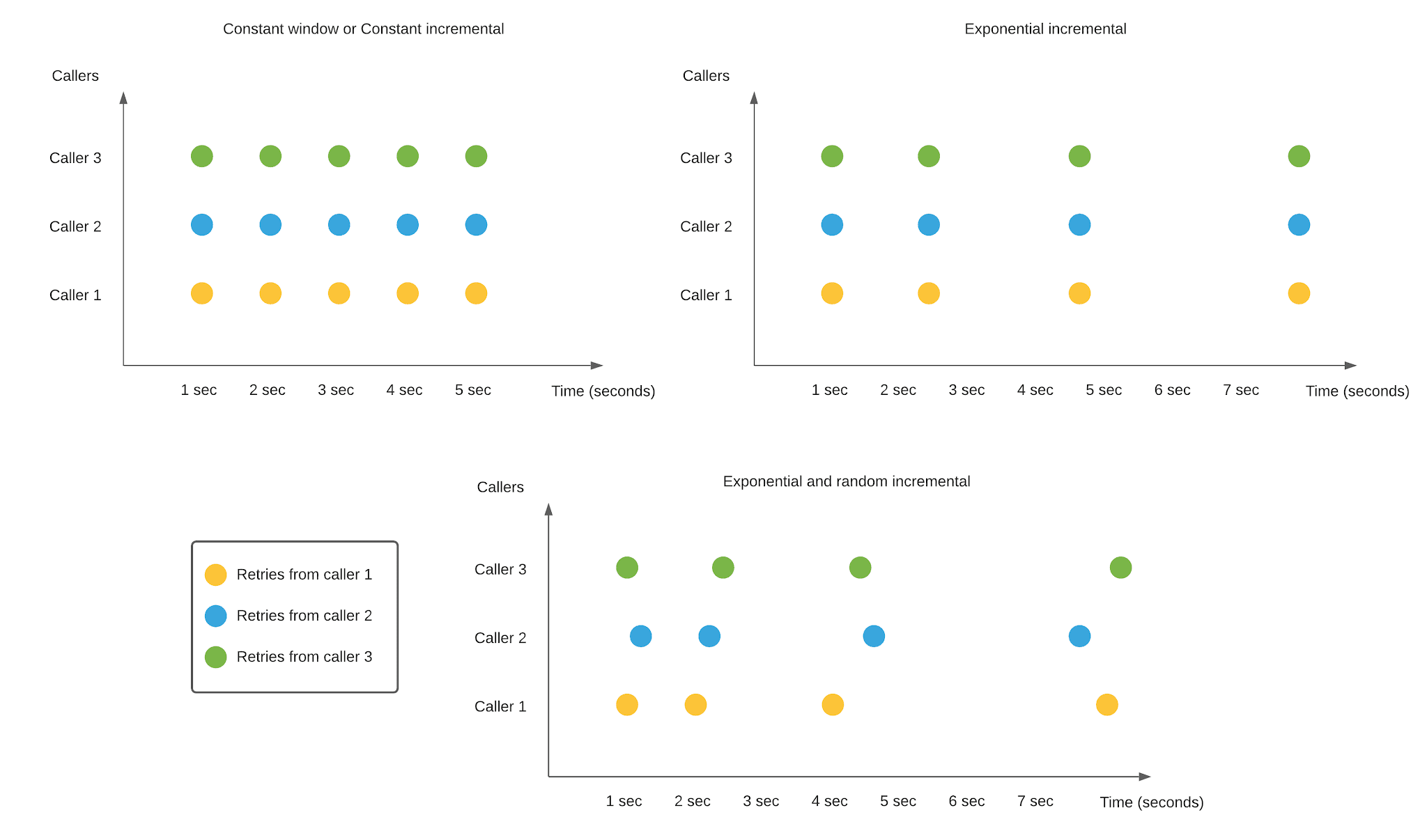 ‘Exponential’과 ‘Exponential and random incremental(Jitter의 한 종류)’비교.
‘Exponential’과 ‘Exponential and random incremental(Jitter의 한 종류)’비교.
‘Backoff’는 재시도(Retry)시 “실패 후 다음 시도를 언제 할지”를 결정하기 위한 전략입니다.
주로 네트워크 요청, 메시지 전송, 분산 잠금(Lock) 획득 등에서 일시적 오류를 처리할 때 사용합니다.
‘Backoff’ 전략중에, 대표적으로 ‘Exponential’과 ‘Jitter’가 있습니다.
- Exponential
재시도(retry) 간의 지연 시간을 지수 함수적으로 늘려가는 전략입니다.
주로 네트워크 요청, 분산 락 획득, 메시지 큐 소비 등 일시적 실패를 견디기 위해 사용됩니다.만약 동시 요청수가 많아서 Fail이 발생하고 있다면, Exponential 방식은 여전히 문제가 있을 수 있습니다.
- Jitter
백오프(backoff) 전략에서 여러 클라이언트가 동시에 재시도하면서 발생하는 “동시 재시도 폭주(thundering herd)”를 막기 위해, 지연 시간(delay)에 임의성(randomness)을 섞는 기법입니다.
System Design Interview에서, Backoff전략으로 ‘Exponential’만 얘기하곤 하지만, 시니어 인터뷰인 경우, Jitter를 알아두는게 좋습니다.
Circuit Breakers
여기서는, ‘cascading failures in a system(시스템 장애가 전파되는것)’에 대해서 다루며, 이를 해결하기 위한 ‘Circuit Breakers’를 다룹니다.
이 ‘cascading failures’에 대한 질문은 Interview에서 많이 나오는 좋은 질문중 하나입니다.
가장 치명적인 문제들을 예방하는 방법을 아는 지원자를 찾는 데 도움이 될 뿐만 아니라, 많은 면접관이 원하는 경험을 평가하는 좋은 기준이기도 합니다.
면접 준비의 핵심은 하나의 실패가 새로운 실패로 이어질 수 있는 시나리오, 즉 연쇄적인 실패에 익숙해지는 것입니다.이러한 패턴을 파악하고 이를 완화하는 방법을 아는 것은 면접에서 돋보일 수 있는 좋은 방법입니다.
‘cascading failures’사례
데이터베이스가 갑자기 다운되어 한 번에 한 인스턴스씩 부팅해야 하는 경우, 수많은 Retry와 사용자들의 과격한 반응으로 인해 인스턴스가 시작조차 되지 않을 수 있습니다(“thundering herd”라고 불리는 현상).
첫 번째 인스턴스를 다시 시작할 수 없으니 전체 데이터베이스를 다시 온라인 상태로 만들 수 없습니다.
이대로, 교착상태에 빠져버리게 됩니다.
- ‘Circuit Breakers’는
- 분산 시스템이나 마이크로서비스 환경에서, 하나의 서비스 실패가 시스템 전체로 전파되는 것을 방지하기 위해 고안된 안정화 기법입니다.
- 네트워크 호출(원격 API, DB, 캐시 등)에 적용해, 일정 수준 이상의 오류가 감지되면 빠르게 실패 응답을 반환하고, 이후 정상 복구 여부를 검사해 다시 호출을 허용합니다.
- 네트워크 통신에 직접적인 영향을 미치는, 견고한 시스템 설계를 위한 중요한 패턴입니다.
- 네트워크 호출(원격 API, DB, 캐시 등)에 적용해, 일정 수준 이상의 오류가 감지되면 빠르게 실패 응답을 반환하고, 이후 정상 복구 여부를 검사해 다시 호출을 허용합니다.
동작 흐름
Closed 상태
기본 상태로, 모든 요청을 정상적으로 외부 서비스(또는 리소스)로 전달하는 상태입니다.
오류가 연속해서 일정 개수(failureThreshold) 이상 발생하면 → Open 상태로 전환합니다.Open 상태
외부 호출을 즉시 차단(Short-circuit) 하고, 사전에 정의된 실패 응답(예: 503, fallback 데이터)을 바로 반환합니다.
일정 시간(resetTimeout)이 지나면 → Half-Open 상태로 전환합니다.Half-Open 상태
외부 호출을 “시험 삼아” 소수(maxTrialRequests)만큼 허용하는 상태입니다.
이 중 성공이 연속 successThreshold 개수만큼 발생하면 → Closed로 복귀합니다.
실패 발생 시 다시 Open으로 돌아가고, resetTimeout 카운트 재시작합니다.
Circuite Breakers가 주는 이점(advantages)
빠른 실패(fail fast)
이미 불안정한 리소스에 대량 요청을 보내지 않아 시스템 부하가 감소합니다.장애 격리
특정 서비스 문제를 빠르게 감지해, caller(상위 서비스)로 에러가 전파되는것을 제어합니다.회복 탄력성
Half-Open 상태로 복귀 검사를 통해, 외부 서비스가 정상화되면 자동 복귀할 수 있습니다.
언제 사용하나요?
HTTP 클라이언트
외부 API 호출 라이브러리에 회로 차단기가 내장되어 있습니다. (Netflix Hystrix, Resilience4j 등)데이터베이스 연결
DB 커넥션 풀에서 일정 실패율 초과 시 새 연결 시도를 차단합니다.마이크로서비스 간 RPC
gRPC나 REST 호출 시 Circuit Breaker 미들웨어를 삽입하여 사용합니다.
Wrapping Up
매우 많은 내용을 다루었지만, 아래의 Key Area를 기반으로 ‘System Design Interview’를 준비하는게 좋습니다.
- Understand the basics: IP addressing, DNS, and the TCP/IP model
- Know your protocols: TCP vs. UDP, HTTP/HTTPS, WebSockets, and gRPC
- Master load balancing: Client-side load balancing and dedicated load balancers
- Plan for practical realities: Regionalization and patterns for handling failures
네트워킹 관련 결정은, 지연 시간, 처리량, 안정성, 보안 등 시스템의 모든 측면에 영향을 미친다는 점을 기억해야 합니다.
네트워킹 구성 요소와 ‘패턴에 대한 정보’에 기반한 선택을 통해, 기능적(functional)일 뿐만 아니라 견고하고(robust) 확장 가능한(scalable) 시스템을 설계할 수 있습니다.
References
- Networking Essentials | hellointerview.com
- Hello Interview | System Design in a Hurry
- OSI 7 Layers | aws.amazon.com
- OSI 모델이란 무엇인가요?- OSI 7계층 설명 - AWS
- OSI Model Tutorial | 9tut.com
- CCNA Training » OSI Model Tutorial
- What is the OSI Model? | cloudflare.com
- What is the OSI Model? | Cloudflare
- OSI Model Explained | bytebytego.com
- ByteByteGo | OSI Model Explained
- The Network Layer I | Addressing | utsa.pressbooks.pub
- 6. The Network Layer I | Addressing – Telecommunications and Networking
- ICMP | cloudflare.com
- ICMP란?| 네트워크레이어 프로토콜 | Cloudflare
- IPsec | cloudflare.com
- IPsec이란? | VPN 작동 방식 | Cloudflare
- IPSec이란 무엇인가요? | aws.amazon.com
- IPSec란 무엇인가요? - IPSec 프로토콜 설명 - AWS
- Transmission Control Protocol | ibm.com
- Transmission Control Protocol/Internet Protocol
- TCP Segment Format | tcpcc.systemapproach.org
- Chapter 2: Background — TCP Congestion Control: A Systems Approach Version 1.1-dev documentation
- TCP KeepAlive | tldp.org
- TCP keepalive overview
- Implementing long-running TCP Connections within VPC networking | aws.amazon.com
- Implementing long-running TCP Connections within VPC networking | Amazon Web Services
- What is UDP? | cloudflare.com
- What is the User Datagram Protocol (UDP)? | Cloudflare
- UDP | systemsapproach.org
- 5.1 Simple Demultiplexor (UDP) — Computer Networks: A Systems Approach Version 6.2-dev documentation
- HTTP Content negotiation | developer.mozilla.org
- Content negotiation - HTTP | MDN
- RFC 2295: Transparent Content Negotiation in HTTP | datatracker.ietf.org
- RFC 2295: Transparent Content Negotiation in HTTP
- HTTP Content negotiation | http.dev
- HTTP Content Negotiation
- GraphQL | graphql.org
- GraphQL | A query language for your API
- RESTful API | aws.amazon.com
- RESTful API란 무엇인가요? - RESTful API 설명 - AWS
- Best practices for RESTful web API design | learn.microsoft.com
- Web API Design Best Practices - Azure Architecture Center
- gRPC load balancing | grpc.io
- gRPC Load Balancing
- Server-sent events(SSE) | learn.microsoft.com
- Server-sent events and Application Gateway for Containers
- WebRTC Hompage | webrtc.org
- WebRTC
- What is WebRTC and how does it work? | antmedia.io
- WebRTC Tutorial: What Is WebRTC and How It Works? - Ant Media
- UDP hole punching | en.wikipedia.org
- UDP hole punching
- What is Load balancing? | aws.amazon.com
- What is Load Balancing? - Load Balancing Algorithm Explained - AWS
- What’s the difference between application, network, and gateway load balancing? | aws.amazon.com
- Application, Network, and Gateway Load Balancing - Difference Between Load Balancing Types - AWS
- Conflict-free replicated data type(CRDT) | en.wikipedia.org
- Conflict-free replicated data type
- What is DNS-based load balancing? | cloudflare.com
- What is DNS-based load balancing? | DNS load balancing | Cloudflare
- CDN이란 무엇인가요? | aws.amazon.com
- CDN이란 무엇인가요? - 콘텐츠 전송 네트워크 설명 - AWS
- Exponential Backoff And Jitter | aws.amazon.com
- Exponential Backoff And Jitter | Amazon Web Services