Workloads | Kubernetes Deep Dive - 4

Kubernetes는 Infra에 대한 추상화를 제공하는 Framework입니다. 이때, 가장 기본이 되는 추상화 단위가 ‘Pod(파드)’입니다.
이 Pod를 어떻게 다루느냐(Workload Management)에 따라, 한 단계 더 추상화된, ‘Deployments’, ‘ReplicaSet’, ‘DaemonSet’등의 Workload Object가 있습니다.
이 Post에서는 Kubernetes에서의 각 Wokrload를 살펴보고, 이해하려고 합니다.
Pod(파드)
Pods are the smallest deployable units of computing that you can create and manage in Kubernetes.
- from kubernetes.io
- Pod는
- Kubernetes의 가장 작은 단위의 배포가능한(deployable) 컴퓨팅 단위입니다.
- 하나 혹은 여러 Container를 포함하는 Group입니다.
- Pod안에서, Container들 끼리 Storage와 Network 자원을 공유합니다.
- 하나 혹은 여러 Container를 포함하는 Group입니다.
Pod 사용 방법 2가지
하나의 Container를 돌리는 Pod
Pod당 1개의 container를 포함하여 운영합니다. 이 경우, Kubernetes가 Container를 직접관리하지 못하니, Pod로 Wrapping하여 관리합니다.
1
2
3
4
5
6
7
8
9
10
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
여러개의 Container를 돌리는 Pod
Container간 서로 강하게 엮여있는(tightly coupled) 경우, Pod안에 여러 Container를 포함시켜 운영할 수 있습니다.
만약, 동일한 Container를 여러개 돌리고 싶은 경우라면, 이 방식이 아니라, 뒤에 나올 ‘ReplicaSet’을 고려해야 합니다.
Pod안에서의 자원(Resource) 공유 원리
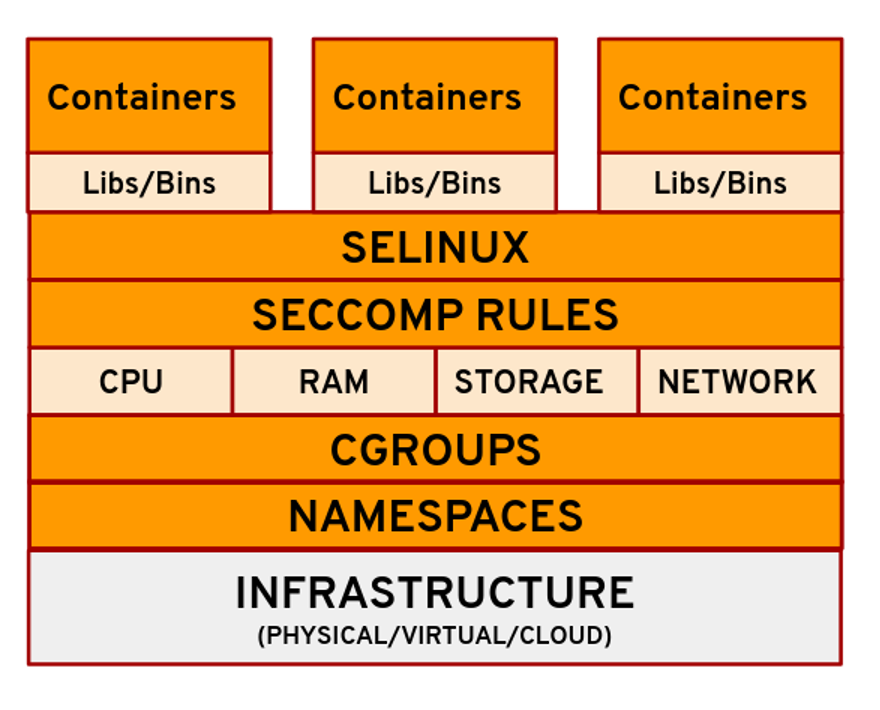 Linux technologies that contribute to containers
Linux technologies that contribute to containers
The shared context of a Pod is a set of Linux namespaces, cgroups, and potentially other facets of isolation - the same things that isolate a container.
- from kubernetes.io
Pod안의 Container들끼리는 Storage(Volume), Network, 컴퓨팅 자원을 공유합니다.
이런 Pod 내부 Container들끼리의 Context공유(Resource 공유)는, Linux의 namespaces와 cgroups(Control Groups)과 다른 격리 기술의 집합(set)으로 이루어져 있습니다.
- Namespaces로
- Pod별로 Process 격리(Isolation)를 구현하고,
- cgroups로
- Container별로(즉, Process별로) 자원(Resource)을 제어합니다.
Linux의 namespaces
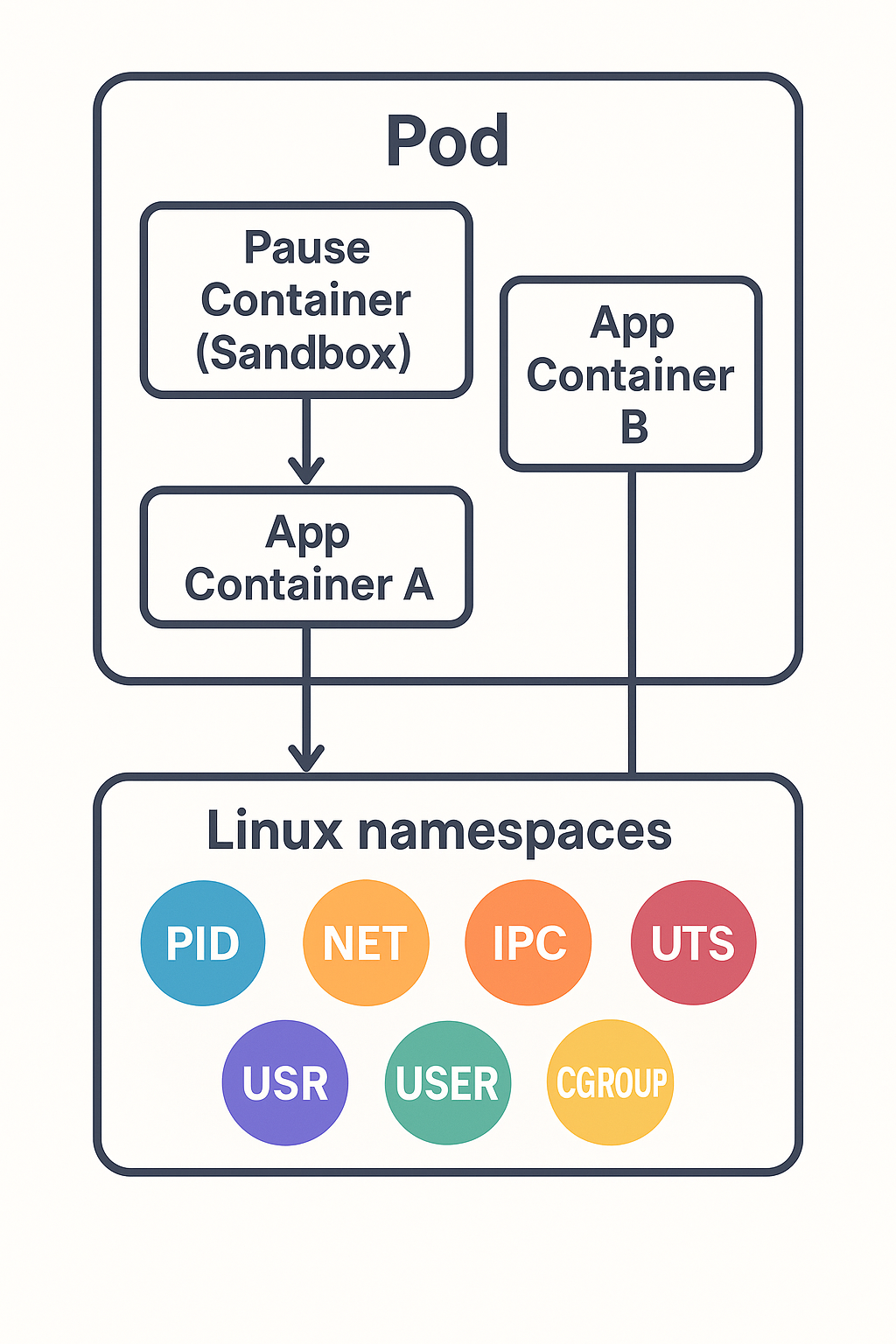 Pod와 linux namespace의 관계
Pod와 linux namespace의 관계
‘Namespaces’는 Linux kernel 기능중 하나입니다.
프로세스별로 ‘가상화된’ 시스템 리소스를 제공하기 위해 도입한 기능입니다. 네임스페이스 덕분에 서로 격리된 프로세스 그룹이 각자 독립적인 환경(파일 시스템, 네트워크, 프로세스 ID 등)을 갖고 동작할 수 있습니다.
여기서, ‘시스템 리소스’는 ‘파일 시스템 마운트 정보’, ‘프로세스 식별자(PID) 공간’, ‘네트워크 스택’, ‘cgroup 계층 구조’등이 해당됩니다.
Kubernetes에서, 하나의 Pod는 실제로 “네임스페이스 집합(namespace bundle, process나 network namespace의 집합을 얘기함)” 위에서 돌아갑니다.
Pod에 사용하는 namespace의 컨셉을 이해하기 위해, 그 일부를 함께 정리하고자 합니다.
Process isolation(PID namespace)
OS의 ‘Process’단위의 격리(isolation)를 위한 namespace입니다.
Pod는 각각의 PID namespace를 가지며, 같은 Host머신에서도 Process가 격리(isolation)되어 작동합니다.Network interfaces(net namespace) ‘net namespace’는 ‘Process’에 새로운 IP(Virtual IP)를 부여하여, 독립적인 Port운영을 가능하게 해줍니다.
예를 들면, 메일서버를 운영한다고 했을때, 해당 메일 서버가 25 Port를 요구하기 때문에, Host당 하나만 띄울 수 있습니다(PID 격리가 되어있다 하더라도).
‘net namespace’는 IP레벨의 격리를 제공하여, 같은 Host에서도 Network interface를 Pod단위로 분리시켜 줍니다.Cgroups
Linux안에서 시스템의 리소스를 조정하는 메커니즘(mechanism) 입니다.
밑에서 더 자세히 다룹니다.등등…
Linux의 cgroups(Control Groups)
‘cgroups’은 Process단위로 Resource(CPU, memory, disk I/O 등)을 격리(isolate)하고, 계산하고(accounts), 제한(limit)하는 Kernel 기능입니다.
cgroups의 기능은 다음과 같습니다.
리소스 제한(Resource limiting)
메모리 사용량(파일 시스템 캐시 포함), 디스크 I/O 대역폭, CPU quota, CPU set, 프로세스당 최대 열린 파일 수 등 그룹 전체에 대한 상한선을 설정할 수 있습니다.우선순위 조절(Prioritization)
CPU 스케줄링 비중(cpu.shares)이나 블록 디바이스 I/O 우선순위(blkio.weight)를 조절해, 특정 그룹이 더 많은 리소스를 확보하도록 할 수 있습니다 .리소스 사용량 측정 및 계산(Accounting)
그룹 단위로 CPU 사용량, 메모리 사용량, I/O 활동 등을 계측하여, 과금(billing)·모니터링·로그 수집 등에 활용할 수 있습니다.프로세스 제어(Control)
프로세스 그룹 전체를 freeze/unfreeze(일시 중단/재개)하거나, checkpoint & restore(검사점 생성 후 재시작) 기능을 통해 상태를 보존·복원할 수 있습니다
‘cgroups v1’에서는 다중 계층을 사용하여, 각각의 cgroup 정책에 따라 별도의 Controller를 사용할 수 있지만, 복잡성이 높아지는 원인이 되었습니다.
최신버전인 ‘cgroups v2’에서는 변경되어, 단일 계층에서 Controller(리소스 관리를 위한)를 관리합니다.
아래는 Kubenetes에서 Pod를 정의하는 부분에서, cgroup과 관련이 있는 부분을 표시하고 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
apiVersion: v1
kind: Pod
metadata:
name: cgroup-demo-pod
spec:
containers:
- name: web-server
image: nginx:latest
# ───────────────────────────────────────────────────────────────
# 이 부분이 cgroup으로 구현되는, 리소스 격리 설정입니다.
resources:
# 최소 보장(request)와 최대 제한(limit)을 지정합니다.
requests:
cpu: "250m" # 이 컨테이너에 최소 0.25 CPU 코어를 보장.
memory: "128Mi" # 최소 128MiB 메모리를 보장.
limits:
cpu: "500m" # 최대 0.5 CPU 코어까지만 사용 가능.
memory: "256Mi" # 최대 256MiB 메모리까지만 사용 가능.
# ───────────────────────────────────────────────────────────────
ports:
- containerPort: 80
Pod Lifecycle
Like individual application containers, Pods are considered to be relatively ephemeral (rather than durable) entities.
- from kubernetes.io
Pod는 영속적(durable)이라기 보다, 일시적인(ephemeral) entity로 여겨집니다.
Kubernetes에서는 Pod의 Lifecycle를 통해, 일시적으로 사용되는 Pod의 상태를 추상화하였습니다.
반복적이고 빠르게, 제거되고 생성되기 때문에, Lifecycle이 필요하다는 뜻
Pod와 Fault Recovery(Self-Healing)
Pod는 포함하고 있는 Container중 하나가 ‘fail’상태에 빠지면, 해당 Container를 재시작하려고 시도합니다.
하지만, Pod을 복구할 수 없는 상태에 빠진 경우, Kubernetes는 더 이상 Pod자체를 복구하려고 하지 않습니다.
문제가 있는 Pod을 제거하고, 다른 구성요소(Control plane의 Control Manager)를 통해 Pod을 재생성하여 복구 합니다.
A given Pod (as defined by a UID) is never “rescheduled” to a different node; instead, that Pod can be replaced by a new, near-identical Pod. - from kubernetes.io
이미 생성된 Pod는 절대로 다른 노드에 재배치 되지 않습니다. 대신에, 새로운 Pod으로 대체됩니다.(Pod의 .metadata.uid 가 바뀝니다. 즉, 새로 생성됩니다.)
이 경우, 새롭게 생성된 Pod이 같은 Node에 배치되는것을 보장하지 않습니다. (Pod를 새로 생성하는거기 때문에, 당연한 얘기일 수도.. filtering을 통해 같은 Node로 배치되게 유도할 수는 있습니다.)
Pod phase
Pod의 status는 여러 정보를 포함한 Object Field로 구성되어 있습니다.
여기에는 phase 라는 field가 있는데, 이는 추상화된 lifecycle의 ‘high-level summary’입니다.
Pod의 phase는 아래의 List로 제한되어 있으며, 이외의 다른 어떤 값도 존재해선 안됩니다.
Pending
클러스터가 Pod ‘정의’를 수용했으나, 아직 스케줄링이 완료되지 않았거나 컨테이너 이미지 다운로드·생성 과정이 진행 중인 상태입니다.Running
최소 하나의 “주요(main)” 컨테이너가 정상적으로 시작된 상태. 모든 컨테이너가 생성되어 Running 상태가 되면 이 Phase로 진입.Succeeded
모든 컨테이너가 정상 종료(Exit 0)하고, 재시작 정책에 따라 재시작되지 않을 때. 주로 일회성 작업(Job/CronJob이 생성한 Pod)에서 볼 수 있습니다.Failed
적어도 하나의 컨테이너가 비정상 종료(Non-zero Exit)하거나, 시스템(OOM 등)에 의해 강제 종료된 상태.이 Phase로 들어가면 다시 다른 Phase로 전환되지 않습니다.Unknown
kube-apiserver가 해당 Pod의 상태를 확인할 수 없을 때. 네트워크 단절이나 kubelet 오류 등으로 인해 노드와의 통신이 끊긴 경우에 주로 발생합니다.
CrashLoopBackOff이 phase라고 혼동하지 마세요
Pod가 반복적으로 ‘시작 실패’를 겪을 때, CrashLoopBackOff 값이 kubectl명령어로 나오는 status field에 노출 될 수 있습니다.(아래 예시 참고)
1
2
3
4
$ kubectl get pods --namespace=alessandras-namespace
NAMESPACE NAME READY STATUS RESTARTS AGE
alessandras-namespace alessandras-pod 0/1 CrashLoopBackOff 200 2d9h
마찬가지로, Terminating 값이 Status에 표시될 때도 있습니다.
이때, 이 CrashLoopBackoff 와 Terminating 값이 Pod의 Phase값은 아닙니다.
kubectl에서 표시되는 Status는 유저 친화적인(직관적인) 값일 뿐이고, 반드시 Pod의 Phase값이 위치하는건 아닙니다.
Init Containers
- ‘Init Containers’는
- Pod initialization 과정에서, Main App container가 실행되기전에 실행되어, initialization작업을 하는 Container입니다.
- 항상 Container 작업이 성공적으로 완료(complete successfully)되어야 합니다.
- 작업이 실패하게 되면, 성공할때까지 재실행 합니다.(
restartPolicy가 있다면, 해당 정책에 따라 ‘Pod fail’로 다루게 됩니다.) - 항상 Container 작업이 성공적으로 완료(complete successfully)되어야 합니다.
일반 Container와의 차이점
- ‘lifecycle’, ‘livenessProbe’, ‘readinessProbe’, or ‘startupProbe’ fields를 지원하지 않습니다.
- Pod이 ‘Ready’상태에 들어가기전에 모든 작업을 완료하고, 종료되어야 합니다.
- 만약, 여러개의 init Container를 정의하였다면, 정의한 순서대로 실행되며, 반드시 이전의 container 작업이 성공적으로 완료되어야 합니다.
- Main App Container와 같은 시스템 Resource를 사용하지만, 상호작용하지 않습니다.
Init containers share the same resources (CPU, memory, network) with the main application containers but do not interact directly with them. They can, however, use shared volumes for data exchange.
- from kubernetes.io
아래는 Init Container의 예시입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app.kubernetes.io/name: MyApp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
- name: init-mydb
image: busybox:1.28
command: ['sh', '-c', "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done"]
Sidecar Containers
- ‘Sidecar Containers’는
- Pod 안에서, Main Container와 함께 계속 실행되는 Container입니다.
- Main Application Container가 시작되기 전에, 먼저 시작합니다.
- App Container의 기능을 확장하거나 강화하기 위해 사용됩니다(App code변경 없이).
- 예를 들면, 로깅, 모니터링, 보안, 데이터 동기화 같은것이 있습니다.
- Main Application Container가 시작되기 전에, 먼저 시작합니다.
Kubernetes에서의 Sidecar containers
‘init container’의 special case 입니다.(즉, init container의 한 종류입니다.)
Kubernetes에서, ‘Sidecar container’는 ‘init container’의 special case 입니다.
‘Sidecar container’는 Pod의 부팅(startup)이후에도 계속 실행된 상태로 있습니다. (보통의 ‘init container’는 Pod의 부팅이후에는 종료됩니다.)
‘init container’와 다르게, sidecar container가 ‘running’상태라면, 종료되지 않고 다음 container가 실행됩니다.동일 Pod의 네임스페이스(namespaces)와 볼륨(volumes), 네트워크를 공유합니다.
- Cluster단위에서 feature를 enable해줘야 합니다.
1
--feature-gates=..,SidecarContainers=true
위와 같이 Sidecar를 사용하도록 설정하면,
initContainers.restartPolicy를 설정할 수 있게 됩니다.(재실행 가능하도록 설정) - 종료시엔, Main Container가 완전히 종료되고, Sidecar의 shutdown이 실행됩니다.(Pod에 정의된 순서의 역순으로 실행)
이는 종료시에도, Sidecar가 다른 Container를 보조하는 역할이 빈틈없이 수행되도록 합니다.
아래는 Sidecar 정의 예시입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
labels:
app: myapp
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: alpine:latest
command: ['sh', '-c', 'while true; do echo "logging" >> /opt/logs.txt; sleep 1; done']
volumeMounts:
- name: data
mountPath: /opt
initContainers:
- name: logshipper
image: alpine:latest
restartPolicy: Always
command: ['sh', '-c', 'tail -F /opt/logs.txt']
volumeMounts:
- name: data
mountPath: /opt
volumes:
- name: data
emptyDir: {}
Pod의 리소스 요청 기준
Pod에는 여러 Container가 포함될 수 있습니다. 이때, Container의 리소스(CPU같은) 정의는 어떻게 처리되어 Pod로서 스케쥴링 되는지 알아봅니다.
컨테이너들은 Pod 단위로 네임스페이스(namespaces)와 볼륨을 공유하지만, 리소스(CPU·메모리·I/O) 관리는 컨테이너별 cgroup을 통해 개별적으로 격리・제어됩니다.
- requests 합산
스케줄러는 Pod 스펙의 각 컨테이너resources.requests값을 모두 더한 만큼의 CPU/메모리 리소스가 노드에 남아 있는지 보고, Pod를 배치합니다.
예: 컨테이너 A가 cpu: 200m, memory: 100Mi, 컨테이너 B가 cpu: 100m, memory: 50Mi 라면, 스케줄러는 “이 Pod는 최소 300m CPU와 150Mi 메모리를 필요로 한다”고 판단합니다.
만약 Pod으로만 Application을 운영한다면, Pod자체로는 HA(High Availability) 관련 기능을 제공하지 않기때문에, 관리하는데에 많은 노력이 필요합니다.
때문에 별도의 ‘Workload Management(Deployment, Daemonset 등)’를 통해 Pod을 관리합니다.
Deployment와 ReplicaSet
Deployment
Kubernetes에서, ‘Deployment’는 선언적(Declarative)으로 애플리케이션의 Pod 복제본Set(ReplicaSet)을 관리하고, 롤링 업데이트·롤백 같은 배포 전략을 자동화해 주는 상위 리소스입니다.
아래는 ‘Deployment’의 예시입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
주요 기능
ReplicaSet 관리
Deployment는 내부적으로 ReplicaSet을 생성·관리하여, 지정한 수(spec.replicas)만큼 Pod이 항상 가동되어 있도록 보장합니다.롤링 업데이트(RollingUpdate)
새로운 버전의 컨테이너 이미지로 점진 교체하면서 가용성(Availability)을 유지합니다.
기본값은 최대 25% 오버프로비저닝, 최대 25% 미달 허용(maxSurge: 25%, maxUnavailable: 25%).롤백(Rollback)
문제가 생기면 이전 버전의 ReplicaSet으로 자동 혹은 수동 복귀가 가능합니다.버전 관리(Revision)
각 변경은 Revision 번호를 부여받아,kubectl rollout history로 추적할 수 있습니다.1 2 3 4 5 6 7 8
# deployment의 history를 확인합니다 $ kubectl rollout history deployment/nginx-deployment deployments "nginx-deployment" REVISION CHANGE-CAUSE 1 kubectl apply --filename=https://k8s.io/examples/controllers/nginx-deployment.yaml 2 kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 3 kubectl set image deployment/nginx-deployment nginx=nginx:1.161
배포전략(Strategy)들
.spec.strategy 를 통해, Deployment의 배포 전략을 선택할 수 있습니다.
RollingUpdate(기본값)
점진적으로 새로운 ReplicaSet의 Pod를 늘리고, 구 버전 Pod를 줄이며 교체합니다.
maxSurge·maxUnavailable로 스피드·가용성 균형 조정할 수 있습니다.Recreate
먼저 모든 기존 Pod를 삭제한 뒤(Zero-downtime 없이) 새 버전 Pod를 생성하는 방식입니다.
Stateless 애플리케이션에서 단순하게 사용할때만 사용합니다.This will only guarantee Pod termination previous to creation for upgrades. ‘Recreate’은 새로운 버젼이 생성되기 전에, 반드시 그 이전버전이 제거되는것만 보장합니다. 즉, zero downtime을 보장하지 않습니다.
운영관련 팁(Tip)들
- 컨테이너 이미지 벡터 태그 대신 SHA digest(my-app@sha256:…)를 쓰면, 동일 버전 재배포 시에도 불필요한 롤아웃을 방지할 수 있습니다.
- Blue–Green 혹은 Canary 배포: Deployment를 여러 개 만들고, Deployment사이에서 서비스(Service) 라우팅을 전환하거나, ‘Argo Rollouts, Flagger’ 같은 툴을 활용하여 구현합니다.
ReplicaSet
A ReplicaSet’s purpose is to maintain a stable set of replica Pods running at any given time. Usually, you define a Deployment and let that Deployment manage ReplicaSets automatically.
- from kubernetes.io
‘ReplicaSet’은 Pod의 복제본이 어느때든(즉, 항상) 지정한 수 만큼 가동되어 있도록 보장하는 역할을 합니다.
ReplicaSet의 작동 방식
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
# modify replicas according to your case
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
tier: frontend
spec:
containers:
- name: php-redis
image: us-docker.pkg.dev/google-samples/containers/gke/gb-frontend:v5
- 여러 필드를 통해, 특정 ReplicaSet으로 관리되고 있는 Pod을 구분합니다.
spec.selector(Label Selector)
ReplicaSet 컨트롤러가 ‘지금 클러스터에 매칭되는 Pod이 몇 개인지’ 세고, 부족하면 생성, 초과면 삭제하기 위해 사용하는 핵심 필터입니다.
스케줄러가 ‘이 ReplicaSet의 Pod’를 노드에 스케줄링하거나, Service가 ‘어떤 Pod로 트래픽을 보낼지’ 결정할 때도 이 Selector를 활용합니다.
처음부터.spec.template.metadata.labels(Pod의 Template에 있는 label정보)와 일치하도록 정의해야 하며, 라벨 구조를 바꾸면 스케일링 대상이 달라집니다.metadata.ownerReferences(Owner Reference)
‘이 Pod는 이 ReplicaSet의 자식’이라는 관계 정보로, ReplicaSet이 삭제될 때 자동으로 Pod를 정리(garbage collect)하도록 Kubernetes에 알려 줍니다.
- ReplicaSet이 유지해야 하는 상태를 정의하고, 이 상태를 유지합니다.
spec.selector
여러 Pod들 사이에서, ReplicaSet에 포함된 Pod을 식별하는데 사용하는 field입니다. 이를 통해 현재 개수와 Desired 개수를 확인하여, 일치하도록 조정합니다.spec.replicas
유지되어야할 Pod의 수(a number of replicas)를 표현합니다.spec.template
Pod를 생성할때 사용하는 Template입니다.
Deployments와 ReplicaSet의 관계
- ReplicaSet은
- ‘원하는 개수의 Pod가 항상 구동되도록 보장’하는 역할에 집중한 리소스인 반면,
- Deployment는
- ReplicaSet 위에 ‘업데이트 관리’, ‘버전 관리’, ‘롤백’ 같은 추가 기능을 제공하는 상위 추상화입니다.
때문에, ReplicaSet을 직접 쓰는것보다, Deployment를 사용하는것을 추천합니다.
StatefulSet
A StatefulSet runs a group of Pods, and maintains a sticky identity for each of those Pods. This is useful for managing applications that need persistent storage or a stable, unique network identity.
- from kubernetes.io
‘StatefulSet’은 쿠버네티스에서 상태(stateful)를 갖는 애플리케이션을 안정적으로 배포·확장·업데이트하기 위해 설계된 Workload 객체입니다. Deployment와 달리 각 Pod에 고정된 네트워크 ID와 영속 스토리지(Persistent Volume)를 보장하며, 생성·삭제·업데이트 시에도 순서(order)와 안정성(stability) 을 제공합니다.
사용 사례
- 데이터베이스 클러스터 **(예: Cassandra, MongoDB, MySQL Replication)
- 분산 캐시 (예: Redis Sentinel, ZooKeeper)
- 메시지 브로커 (예: Kafka, RabbitMQ)
- 상태 저장 애플리케이션 (예: Elasticsearch, Etcd)
반드시 Stateful이 필요한 APP이 아니라면, 되도록 Deployment를 사용하길 추천합니다.
Scalable을 고려해야하는 시스템에서, Stateful 시스템으로 App을 만든다면, Pod이 영속적인 개념이 아니기 때문에, Stateful을 위해 많은 작업이 추가로 필요해집니다.
StatefulSet과 Headless Service
](/assets/img/for-post/k8s%20workloads/image%202.png) StatefulSet과 Headless Service의 관계. mysql CQRS패턴을 예시로 사용. | alibabacloud.com
StatefulSet과 Headless Service의 관계. mysql CQRS패턴을 예시로 사용. | alibabacloud.com
StatefulSet에 ‘Service’가 아닌, 별도의 ‘Headless Service’가 필요한 이유?
StatefulSet이 ‘상태 저장(stateful)’ 애플리케이션을 다루기 위해 제공하는 핵심 기능 중 하나가 각 Pod에 고정된 네트워크 ID를 부여하는 것입니다.
그런데 쿠버네티스의 기본 ‘Service’는 클러스터 IP와 로드밸런싱(LB)을 전제로 동작하기 때문에, StatefulSet이 원하는 ‘Pod별로 고정된 DNS 이름’을 제공해 주지 않습니다.
- 정리하면,
- Kubernetes에서는 보통, Pod가 아닌 ‘Service’를 통해 Pod에 접속합니다. 이 ‘Service’를 이용하면, LB를 통해 Pod에 random하게 접속하게 됩니다.
- 하지만, DB와 같은 App들은 구분을 위해, Pod에 대한 고정된 DNS주소가 필요할 수 있습니다.
- StatefulSet은 이를 위해, 고정된 네크워크 ID(대표적으로 IP)를 제공하고,
- 이를 Headless Service를 통해, Pod에 접속하기 위한 개별 IP를 조회할 수 있게 합니다.(DNS에 개별 Pod에 접속하기 위한 Domain을 등록하는 방식.)
- 하지만, DB와 같은 App들은 구분을 위해, Pod에 대한 고정된 DNS주소가 필요할 수 있습니다.
Headless Service의 역할
- Service에 속한 Pod별로 A 레코드를 생성합니다
일반 Service(clusterIP가 할당됩니다)
동일한 Service 이름에 대해 하나의 VIP(가상 IP)만 DNS에 등록되는 방식입니다. 이후, LB와 kube-proxy를 통해 Pod로 연결됩니다.Headless Service(clusterIP가 부여되지 않습니다.)
selector에 걸리는 각 Pod의 IP를 개별 A 레코드로 DNS에 등록하여, Service Discovery가 되도록 합니다.
Stable Network Identity 보장
statefulSet이 생성하는 Pod 이름(mysql-0, mysql-1…)과 Headless Service 이름(headless-mysql-svc)을 조합해
mysql-0.headless-mysql-svc,mysql-1.headless-svc와 같은 영구적인 DNS 이름을 제공합니다.
Pod IP가 변경되더라도 DNS 이름은 그대로 유지되어, 애플리케이션은 항상 같은 호스트명으로 자신(또는 다른 노드)을 참조할 수 있습니다.Service Discover(서비스 디스커버리) 지원
ZooKeeper, Cassandra 같은 분산 시스템은 클러스터 토폴로지를 구성할 때 피어(peer) 노드의 정확한 주소가 필요합니다.
Headless Service를 통해 “내 토폴로지 멤버 리스트”를 DNS 기반으로 조회할 수 있게 해 줍니다.- 로드밸런싱이 아니라 직접 연결
Headless Service는 프록시나 로드밸런싱 기능을 제공하지 않습니다. DNS 조회 결과로 얻은 Pod IP 리스트를 클라이언트가 직접 사용하게 됩니다.
이 방식이 StatefulSet이 요구하는 ‘개별 Pod에 대한 직접 연결’하는 시나리오에 딱 맞습니다.
DaemonSet
A DaemonSet defines Pods that provide node-local facilities. These might be fundamental to the operation of your cluster, such as a networking helper tool, or be part of an add-on. - from kubernetes.io
DaemonSet은 클러스터의 모든(또는 지정한) 노드에 ‘하나씩’ Pod를 배포·유지하도록 보장하는 컨트롤러입니다. 주로 노드별 에이전트(로그 수집기, 모니터링 에이전트, 네트워크 플러그인 등)를 배포할 때 사용합니다.
노드가 추가되면, 해당 노드에 대한 Pod이 추가로 생성됩니다.
사용 사례
- 로그 수집 & 모니터링 에이전트: Fluentd, Filebeat, Telegraf, Datadog Agent
- 네트워크 플러그인: Calico, Cilium, Weave Net
- 스토리지 드라이버: CSI 플러그인 데몬
- 보안 에이전트: Falco, Istio 데몬 서비스
DaemonSet Spec 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# these tolerations are to have the daemonset runnable on control plane nodes
# remove them if your control plane nodes should not run pods
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
# it may be desirable to set a high priority class to ensure that a DaemonSet Pod
# preempts running Pods
# priorityClassName: important
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
Jobs
Jobs represent one-off tasks that run to completion and then stop. - from kubernetes.io
‘Jobs’는 1회성 작업(실행을 완료하고 멈추는)을 안전하게 실행하기 위해 사용합니다.
‘Job’은 작업의 완료를 위해, Pod를 1개이상 생성할 수 있습니다. 이때, ‘작업의 완료’기준은, 성공적으로 종료된(successfully terminate) Pod의 갯수입니다.
이를 정리하면, ‘Jobs’는 지정한 개수의 완료된 Pod을 보장해주는 컨트롤러 입니다.
반복적이거나 장기 실행 서비스인 ‘Deployment’와 달리, 특정 작업이 한 번만 또는 정해진 횟수만큼 실행되어야 할 때 사용합니다.
Jobs Spec 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
apiVersion: batch/v1
kind: Job
metadata:
name: example-job
spec:
completions: 3 # 총 3개 Pod가 성공 종료되어야 Job이 완료됩니다.
parallelism: 2 # 동시에 최대 2개의 Pod을 실행합니다.
backoffLimit: 4 # 실패 시, 최대 4회 재시도합니다.
template:
spec:
restartPolicy: OnFailure
containers:
- name: task
image: busybox
args: ["sh", "-c", "echo Hello; exit 0"]
응용하기
Indexed Jobs (.spec.completionMode: “Indexed”)
각 Pod에 JOB_COMPLETION_INDEX 환경 변수를 주어, 인덱스별 작업(partition으로 )을 분리하여 처리할 수 있습니다.Work Queue 패턴
메시지 큐(RabbitMQ, Kafka)와 연동해, parallelism 을 높여 대량 데이터를 분산 처리합니다.TTL(Time-to-Live) Controller
Job 완료 후 일정 시간(.spec.ttlSecondsAfterFinished)이 지나면 자동 삭제되게 할 수 있습니다.
사용 사례
- 데이터 마이그레이션: 데이터를 일괄로 로드하거나 변환할때 사용합니다.
- 백업/정리 스크립트: 주기적인 백업작업이나 로그 아카이빙 작업에 사용합니다.
- 머신러닝 학습: 단일 배치(1회 실행) 훈련 작업용으로 사용합니다.
- 크론작업 대체: CronJob과 조합해 주기적 Batch 실행할 때 사용합니다.
References
- Pods | kubernetes.io
- Pods
- Workload Management | kubernetes.io
- Workload Management
- Deployments | kubernetes.io
- Deployments
- ReplicaSet | kubernetes.io
- ReplicaSet
- StatefulSet | kubernetes.io
- StatefulSets
- Headless Service | kubernetes.io
- Service
- DaemonSet | kubernetes.io
- DaemonSet
- Linux namespaces | en.wikipedia.org
- Linux namespaces
- The 7 most used Linux namespaces | redhat.com
- The 7 most used Linux namespaces
- Linux cgroups(Control Groups) | docs.redhat.com
- Chapter1.Introduction to Control Groups (Cgroups) | Resource Management Guide | Red Hat Enterprise Linux | 6 | Red Hat Documentation
- A Linux sysadmin’s introduction to cgroups | redhat.com
- A Linux sysadmin’s introduction to cgroups
- 4 Linux technologies fundamental to containers | opensource.com
- 4 Linux technologies fundamental to containers
- Evolution of Docker from Linux Containers | baeldung.com
- Evolution of Docker from Linux Containers | Baeldung on Linux
- Building a Linux container by hand using namespaces | redhat.com
- Building a Linux container by hand using namespaces
- Indexed Jobs | kubernetes.io
- Introducing Indexed Jobs
- Work Queue pattern with Jobs | kubernetes.io
- Coarse Parallel Processing Using a Work Queue
- Fine Parallel Processing Using a Work Queue