Components - Control Plane | Kubernetes Deep Dive - 2
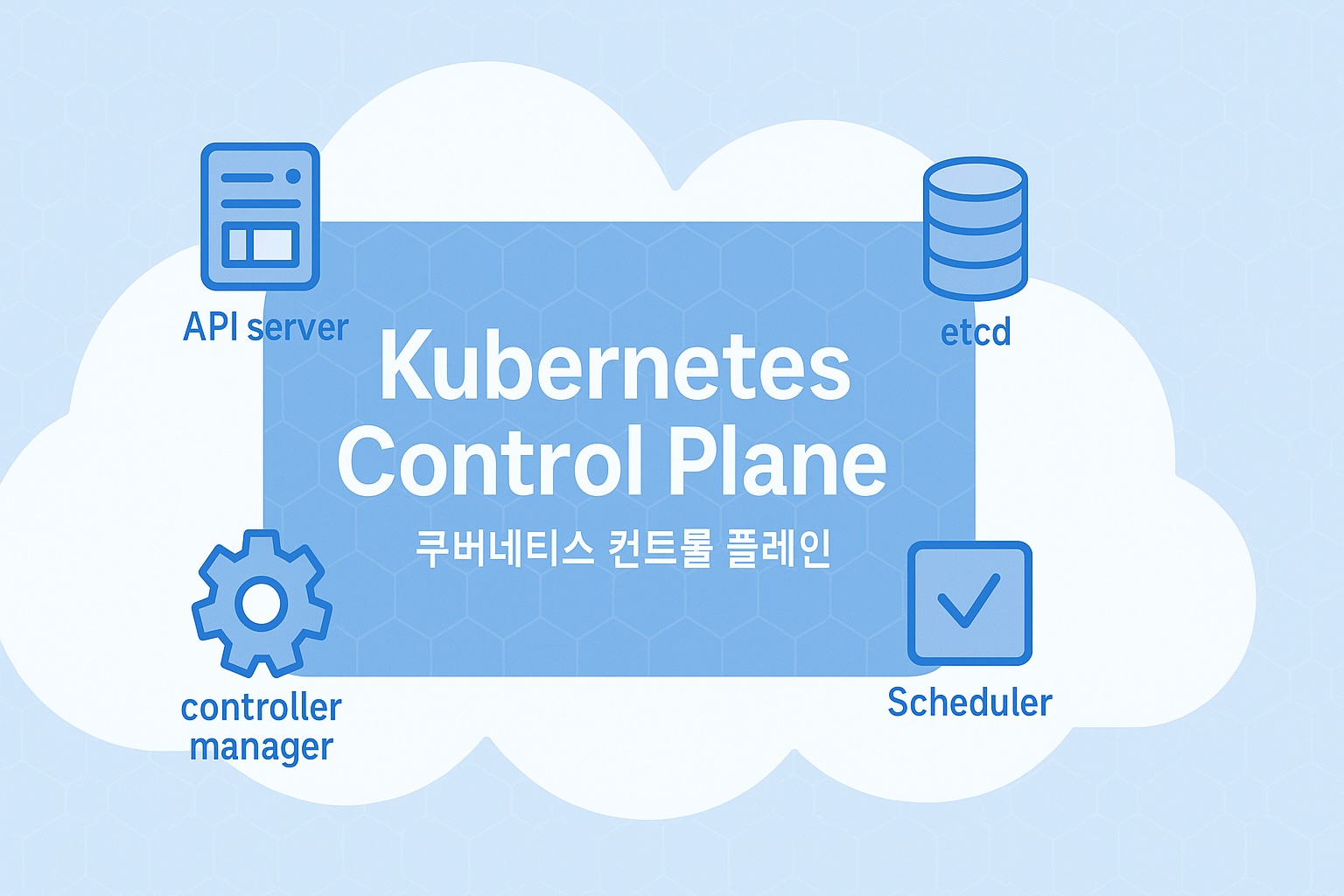
Kubernetes에서 ‘Control Plane’은 Cluster를 운영하는 Core혹은 ‘뇌’의 역할을 합니다.
Cluster를 다루기 위한 API요청을 검증하고, 상태를 저장하고, 요청을 실행시키고, Cluster를 유지하는 역할을 합니다.
여기서는 ‘Control Plane’이 어떤 Component를 통해 이런 역할을 수행하는지 알아봅니다.
](/assets/img/for-post/k8s%20control%20plane/image.png) Kubernetes의 Cluster Architecture | https://kubernetes.io/docs/concepts/architecture/
Kubernetes의 Cluster Architecture | https://kubernetes.io/docs/concepts/architecture/
kube-apiserver
Kubernetes를 조작(control)하기 위한 API를 외부에 노출하는 서비스입니다. Kubernetes 입장에서 보면(backend로 두고 보면), ‘kube-apiserver’는 frontend에 해당합니다.
- ‘kube-apiserver’는
- 수평확장(scale horizontally, scale-out)이 가능합니다. 이는 Node가 늘어남에 따라, apiserver도 확장되는것을 의미합니다.
- 인증(Authentication), 인가(Authorization), Admission Control(승인 제어)를 수행합니다.
- 요청 Schema에 대해 검증 하고 변환합니다.
- etcd에 대한 CRUD Interface라고 말하기도 합니다.
- 인증(Authentication), 인가(Authorization), Admission Control(승인 제어)를 수행합니다.
Admission Control
Admission control mechanisms may be validating, mutating, or both.
- from Admission Control in Kubernetes
‘Admission Control’은 요청의 ‘승인(Admission)’을 ‘제어(Control)’하는 기능을 말합니다.
‘kube-apiserver’로 들어온 요청을 가로채서(intercept), ‘변경, 검증’에 대한 별도의 과정을 수행하는 기능입니다.
이 ‘Admission Control’은 요청에 대한 인증(authentication)과 인가(authorization)이 완료된 요청에 대해서 반영됩니다.
- 이는 크게 2가지 과정으로 이루어집니다.
- 요청 변경(mutating). Mutating controller를 통해 요청 내용을 수정할 수 있습니다.
- 요청 검증(validation). Validating controllers를 통해 요청을 검증하여, 더 이상 진행되지 못한게 할 수 있습니다.
위 기능중 하나만 작동하게 할 수도 있고, 모두 작동하게 할 수도 있습니다.
단 ‘Read(get, watch or list)’는 막을(block) 수 없습니다. CREATE, UPDATE, DELETE와 같은 ‘변경(mutating)’ 요청에 대해서만 적용됩니다. 혹은, 연결(connect) 같은 커스텀 동작에 대해서 적용됩니다.(ex: kubectl exec)
Admission Control Flow
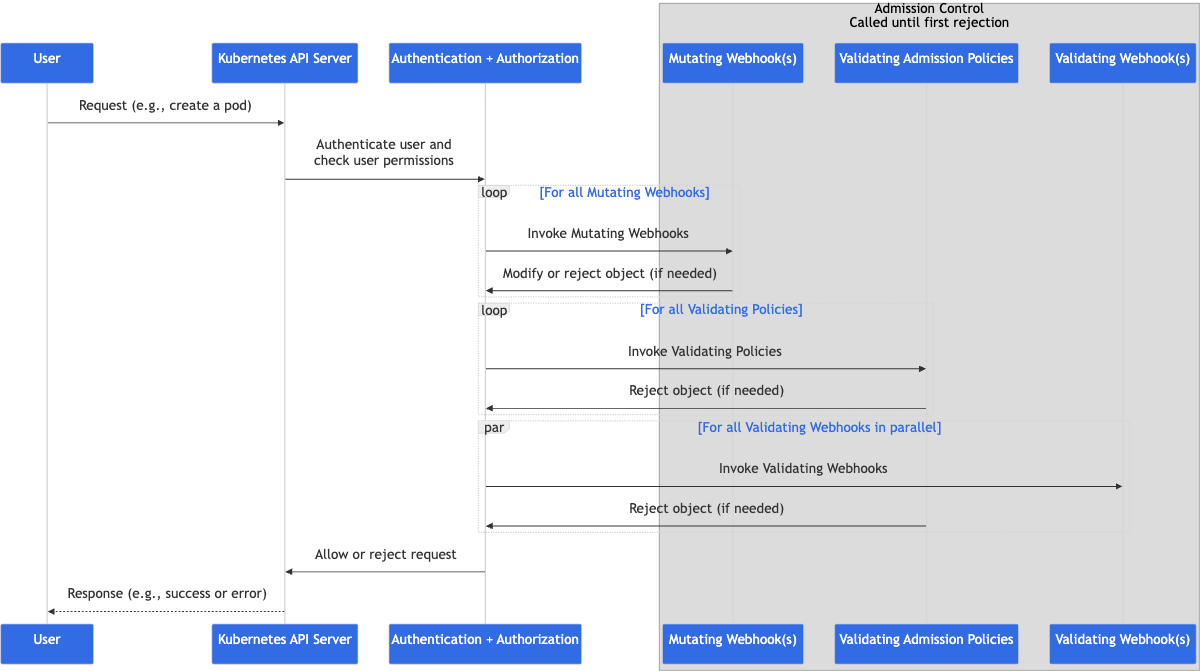 Admission Control Flow
Admission Control Flow
Request가 kube-apiserver에 도착합니다
인증(authentication)과 인가(authorization)을 수행합니다.
변경(mutating)에 대해 등록된 모든 Webhook을 실행합니다.
‘Mutating Admission controllers’가 수행합니다.검증(validation)에 대한 정책(policy)에 대해서 validation을 수행합니다.
‘Mutating’단계가지 마치고, 만들어진 최종 객체에 대해서, Cluster 내부에서 정의된 정책(policy)를 기반으로 평가하는 단계 입니다.- 검증(validation)에 대해 등록된 모든 Webhook을 실행합니다.
이전 단계인 정책(policy) validation과는 다르게, 외부의 HTTP endpoint에 요청을 보냅니다.
- etcd에 저장합니다.
MutatingAdmissionWebhook Controller
요청(request) 객체를 변경(patch)합니다.
이때, 기본값을 주입하거나, 사이드카(sidecar)가 삽입됩니다.
여기서 ‘사이드카(sidecar)’는 패턴으로 자리잡아, Kubernetes에서 핵심적인 역할을 하게 됩니다.
ValidatingAdmissionWebhook Controller
요청(request) 객체가 정책에 부합하는지 검사하고, 허용하거나 거부합니다.
모든 Mutating이 끝나고 나서 실행됩니다.
성능 혹은 스케일링 시에 튜닝할 수 있는 부분
- API Server의 QPS(Queries Per Second)나 Burst를 조정할 수 있습니다
1 2 3 4 5 6 7
# QPS 조정 # default값이 20 $ kube-controller-manager --kube-api-qps 20 # Burst 조정 # default값이 30 $ kube-controller-manager --kube-api-burst 30
Source code
https://github.com/kubernetes/apiserver
etcd
etcd is a strongly consistent, distributed key-value store that provides a reliable way to store data that needs to be accessed by a distributed system or cluster of machines.
- from etcd homepage
‘etcd’는 key-value 데이터 저장소입니다. 강한 일관성(strongly consistent), 분산형(distributed) 특징을 통해 매우 안정적인 저장소 역할을 합니다.
- Kubernetes에서 etcd는
- 클러스터에 대한 상태 저장소 역할을합니다. 모든 k8s객체(Deployment, Service, ConfigMap등등)의 Desired State를 저장합니다.
- 컨트롤 loop와 연동되어, 컨트롤러 매니저와 스케줄러 같은 제어 컴포턴트가 변경을 감지하여, 행동을 시작하도록 합니다.
- TLS를 통한 암호화 통신, 클라이언트 인증(Cert-based), Role-Based Access Control(RBAC) 설정으로 데이터를 보호합니다.
- 컨트롤 loop와 연동되어, 컨트롤러 매니저와 스케줄러 같은 제어 컴포턴트가 변경을 감지하여, 행동을 시작하도록 합니다.
etcd는 다음과 같은 기능을 제공합니다.
강한 일관성(strongly consistent)
모든 읽기(read)/쓰기(write) 요청에 대해 최신상태를 보장하며, ‘읽기 후 쓰기(Write after read, WAR)’ 시점에 stale 데이터(구버젼 데이터)가 반환될 위험이 없습니다.
‘읽기 후 쓰기(Write After Read, WAR)’: CPU레벨에서 명령어를 병렬처리 할때, 처리 순서에 따라 반환값이 달라질 수 있는 문제를 말합니다.
즉, 여기서는 ‘데이터를 읽을때 마다 값이 다를 가능성’에 대한 얘기를 하고 있습니다.
분산형(distributed) 시스템의 리더, 팔로워 구조
- etcd는
- 리더(Leader)와 다수의 팔로워(Follower) 노드로 분산처리 시스템을 구성합니다.
- 쓰기(write) 요청은 리더가 처리한 후에, 팔로워에 복제합니다.
- 커밋이 완료되면, 해당 데이터를 클라이언트에게 노출합니다.(강력한 일관성 보장)
- 쓰기(write) 요청은 리더가 처리한 후에, 팔로워에 복제합니다.
etcd의 분산 시스템은, Raft 알고리즘을 사용합니다.
Raft 합의 알고리즘
분산 환경에서 데이터의 일관성과 가용성을 보장하기 위해 사용하는 알고리즘입니다.
‘리더 선출’, ‘로그 복제(Log Replication)’, ‘안정성 보장’이 특징입니다.
- 리더 선출
- 팔로워가 리더의 신호를 못 받으면, 팔로워들이 후보상태로 전환되어 새로운 리더를 선출합니다.
이런 이유로, etcd의 인스턴스는 홀수개로 이루어져야 합니다. 짝수개인 경우, 리더가 실패시 후보로 나온 인스턴스를 빼면, 다시 짝수개가되어 선출과정에서 동수가 나올 수 있습니다.
- 로그 복제
- 클라이언트의 key-value 변경 요청을 받으면, 이를 리더에게 보냅니다. 리더는 이를 받아서 Log에 추가하며, 이를 팔로워들에게 전파시킵니다. 과반의 팔로워가 저장했다고 하면, 이를 commit합니다.
- 안정성 보장
- commit된 로그는 반드시 과반의 노드에 복제되어 있습니다.
데이터 모델
etcd는 key-value 쌍(pair)를 B+ tree (BoltDB)형태로 저장합니다.
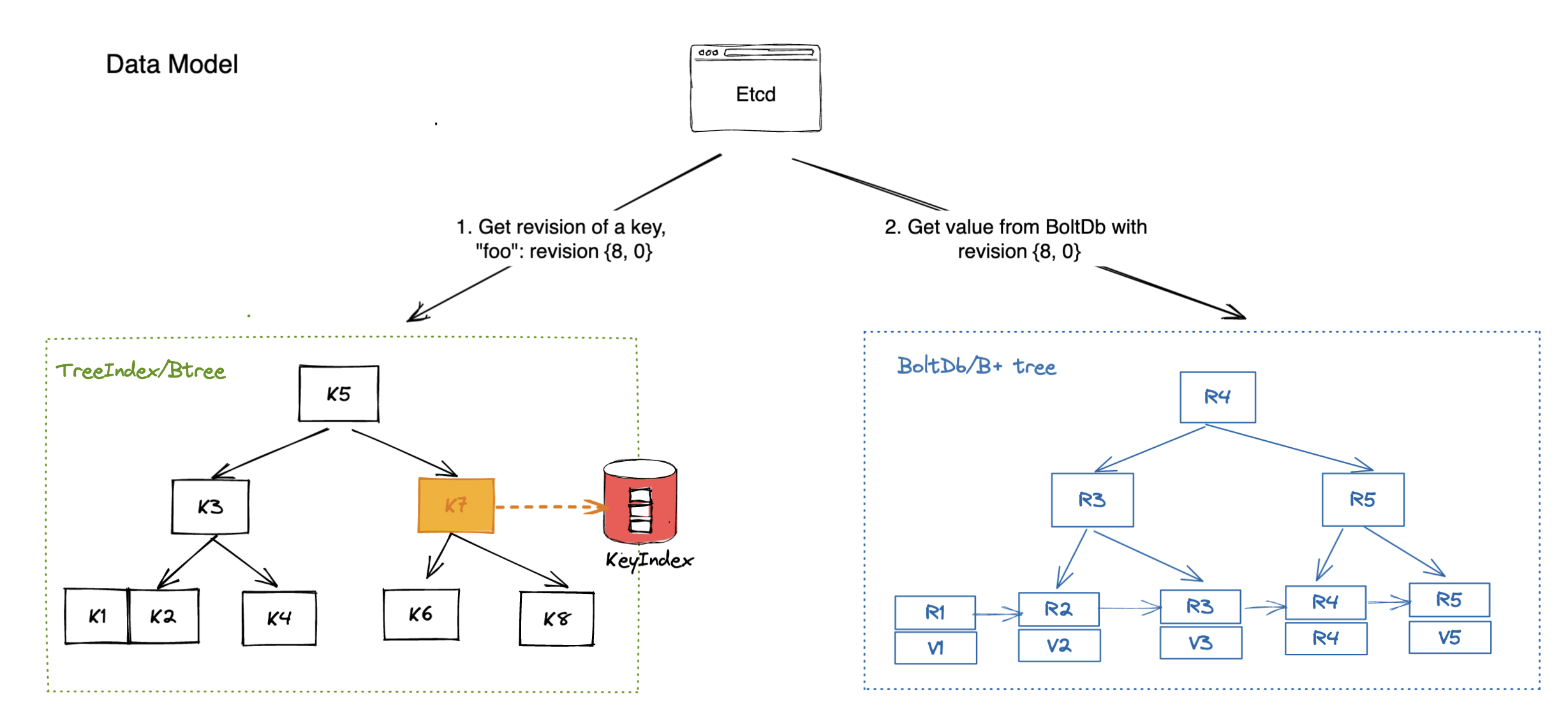 etcd의 데이터 모델
etcd의 데이터 모델
- etcd는
- 별도의 In-memory btree도 함께 운영하는데, 이는 key에 대한 query속도를 높여주는 역할을 합니다.
- in-memory btree를 통해 revision정보를 얻고, 이를 기반으로(b+ tree의 key로 사용해서) b+ tree에서 value값을 가져옵니다.
Tuning
kube-scheduler
‘kube-scheduler’는 Pod을 Node에 배치(binding)하는 역할을 합니다.
Cluster의 리소스 요청, 정책(affinity/taint, toleration 등), 사용자 정의를 모두 종합하여 최적의 Node를 선택합니다. 이 과정에서 Pod이 스케쥴링 될 수 있는 Node를 ‘feasible Node’라고 합니다.
만약, 적합한 Node가 없다면, Pod은 스케쥴 되지 못한 채로 있습니다. 이는 조건에 부합한 Node가 나타날때가지 계속됩니다.
Pod이 스케쥴링 되는 과정
‘kube-scheduler’를 통해서 Pod이 배치되는 과정은 2개의 step으로 이루어져 있습니다.
Filtering
특정 조건에 따라 ‘feasible Node’를 찾습니다. 이 과정이 완료되면, 적합한 Node List가 반환됩니다.Scoring
‘Filtering’에서 만들어진 Node List를 기반으로, 순위를 매깁니다(rank). 이를 기반으로 가장 적합한 Node를 선택하여 Pod을 배치합니다.
만약 동점인 Node가 있다면, 이 Node들 사이에서 random하게 배치됩니다.
‘kube-scheduler’는 이 결과를 API서버에 알려줍니다(notify).
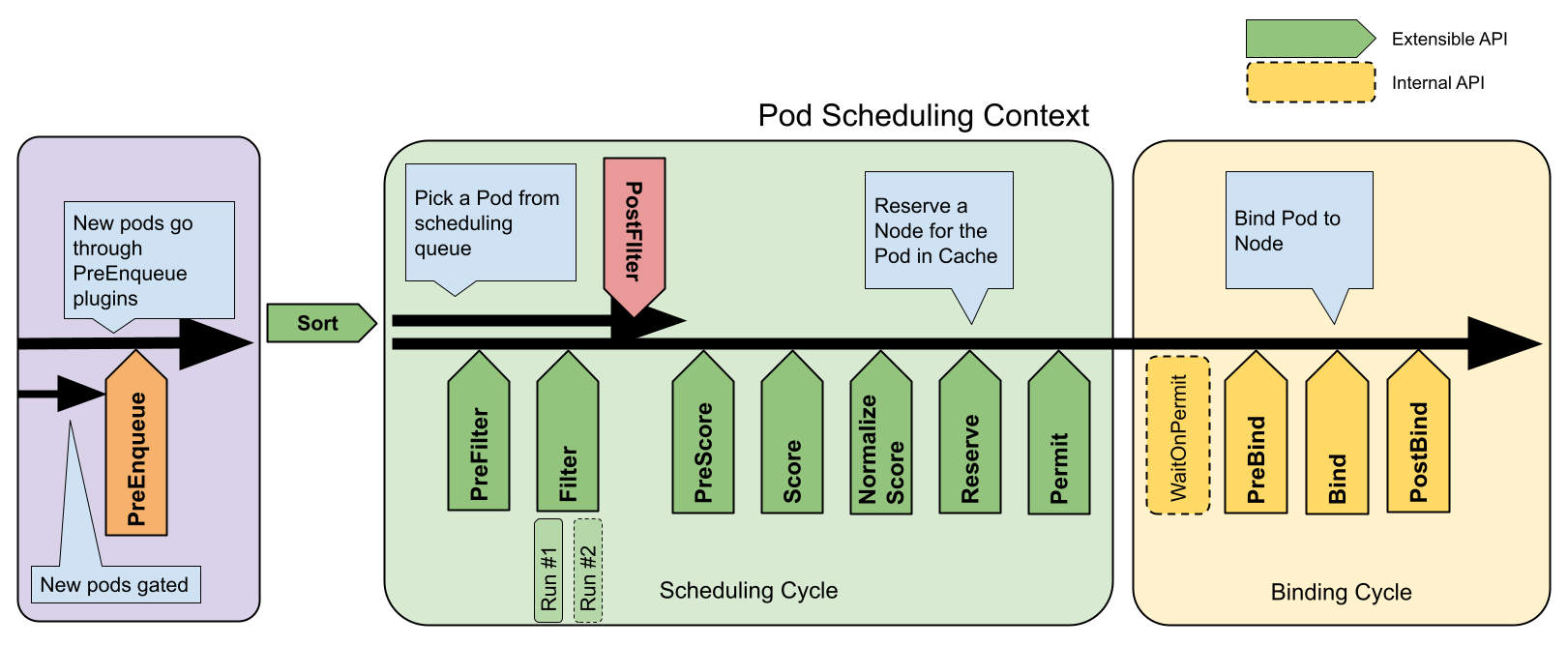 Pod이 스케쥴링 되는 과정
Pod이 스케쥴링 되는 과정
 Scheduler와 다른 Component의 상호작용
Scheduler와 다른 Component의 상호작용
스케쥴링 정책(Scheduling Policies)를 통해 스케쥴링을 조정할 수 있습니다. (v1.23이전 한정)
1
2
3
4
5
$ kube-scheduler --policy-config-file <filename>
# or
$ kube-scheduler --policy-configmap <ConfigMap>
스케쥴러 설정(Scheduler Configuration)을 통해 위와 동일한 설정을 할 수 있습니다.(v1.23 이상)
1
$ kube-scheduler --config <filename>
1
2
3
4
5
# configuration 파일 예시
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
clientConnection:
kubeconfig: /etc/srv/kubernetes/kube-scheduler/kubeconfig
Source Code
https://github.com/kubernetes/kube-scheduler
kube-controller-manager
‘kube-controller-manager’는 ‘control loops’를 운영하는 컴포넌트입니다.
여기서 ‘loop’는 ‘종료되지 않음’을 의미합니다.
‘kube-controller-manager’는 계속해서 시스템의 현재 상태(the state of system)를 관찰하고, 현재상태와 목표 상태(Desired State)가 다르다면, 이에 도달하기 위해 변화(changes)를 시도합니다.
Control Loop Flow
 Control loop의 flow
Control loop의 flow
‘kube-controller-manager’는 ‘Control Loop’를 통해 Cluster의 현재상태와 목표 상태(Desired State)를 계속 비교하며, 동일하게 맞춥니다.
이 Loop안에서, 각각의 Kubernetes Object에 맞는 ‘Controller’를 사용합니다.
controller 종류
Node Controller
노드의 상태 변화를 감시(Ready/NotReady), 노드 삭제 감지 시 인그레스/서비스 정리Replication controller / Replicaset controller
replicas 수를 보장하기 위해 Pod을 증감을 관장Endpoints controller
Service와 Pod IP 매핑 정보 유지Namespace controller
Namespace 리소스 생성·삭제 후, 네임스페이스 내부 리소스 정리Service controller
클라우드 로드밸런서 생성·삭제, EndpointSlice 동기화Deployment Controller
롤링 업데이트, 롤백, 배포전략(Blue/Green, Canary) 관리- Horizontal Pod Autoscaler(HPA)
- …등
Horizontal Pod Autoscaler(HPA)
Kubernetes에서 워크로드의 부하(CPU 사용률, 메모리 사용량, 커스텀 메트릭 등)에 따라 자동으로 Pod 개수를 수평(horizontal) 으로 늘리거나 줄여 주는 컨트롤러입니다.
작동 Flow
- 특정 주기(기본 15초)마다 Metrics API(보통 metrics-server 또는 Prometheus Adapter 등)를 호출해 대상 리소스의 현재 메트릭을 가져옵니다.
현재 값과 목표(target)값을 비교합니다.
\[\text{desiredReplicas} = \left\lceil \frac{\text{currentMetricValue}}{\text{targetMetricValue}} \times \text{currentReplicas} \right\rceil\]
이때, 아래 알고리즘을 사용하여, 필요한 Pod의 개수를 계산합니다.스케일 결정
2에서 산출된 ‘desiredReplicas’를 minReplicas ~ maxReplicase 범위의 값으로 클램프(clamp)하여 최종 스케일 개수를 확정합니다.- Scale API를 호출합니다.
Deployment/ReplicaSet/StatefulSet 등 대상 리소스에 대한 scale 서브리소스를 업데이트하여, 실제 Pod 수를 조정합니다.
Config파일 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization # 평균(cpu) 사용률 비율 (%)
averageUtilization: 50
- type: Resource
resource:
name: memory
target:
type: Value # 절대 메모리 사용량(bytes)
averageValue: 200Mi
- type: Pods # Pod당 커스텀 메트릭
pods:
metric:
name: transactions_per_second
target:
type: AverageValue
averageValue: "100"
cloud-controller-manager(optional)
AWS와 같은 특정 Cloud에 대응하는 Control Logic을 담고 있는 component입니다.
처음에는 Core Controller manager(kube-controller-manager)에 포함되어 있었지만, 현재는 Cloud Provider(AWS와 같은, 이하 클라우드)의 Control logic과 Kubernetes logic이 분리되어 있습니다.
- 이런 ‘분리 설계’를 통해,
- Kubernetes와 각 Cloud Provider사이에 분리된 Feature release가 가능해졌습니다.
- 클라우드별 기능(로드밸런서 생성, 볼륨 프로비저닝, Route 설정 등등)을 외부 플러그인 형태로 관리하게 되었습니다.(클라우드 플러그인만 바꾸면, 다양한 환경에서 사용가능)
‘cloud-controller-manager’에 포함된 Controller들
Node Controller
클라우드 서비스에서 제공하는 Node(VM환경)에 대한 controller입니다.
VM들이 Kubernetes의 Node로 역할하도록 합니다.Route Controller
클라우드에서 제공하는 Routing설정을 통해 Pod간 통신이 가능하게 합니다.Service Controller
클라우드의 LB(Load Balancer)나 IP, networking packet filtering, health checking등을 Kubernetes에 적용하는 controller입니다.Volume Controller
Kubernetes의 Persistent Volume을 클라우드 서비스에서 제공하는 볼륨과 연결시켜 줍니다.(NAS와 같은 것들)
Pod배치를 위한 kube-scheduler과 kube-controller-manager의 상호작용
‘kube-scheduler’는 Pod을 Node에 배치하는 역할을 하고, ‘kube-controller-manager’는 Desired State를 달성하는 역할(Pod을 늘리는 역할)을 하는데, 이 과정은 어떻게 이루어 질까?
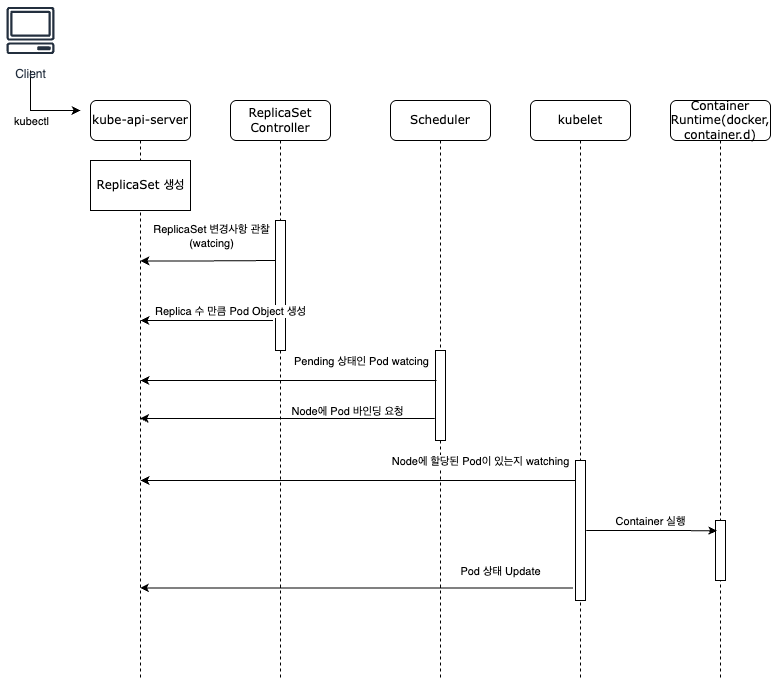 Deployment반영을 위한 component간 상호작용 Flow
Deployment반영을 위한 component간 상호작용 Flow
만약, Deployment를 통해 Pod을 생성하고 있다면,
Controller manager에서 Pod Object 생성
Deployment → ReplicaSet → Pod 오브젝트를 생성합니다.
이때 Pod은 spec.nodeName이 비어 있는 “Pending” 상태입니다scheduler에서 Pod을 Node에 배치
Pending Pod를 발견 → 노드 리스트 중 필터(Filter)·스코어(Score) → Binding 호출 (spec.nodeName 설정)Controller manager에서 후속작업 수행(optional)
예: DaemonSet 컨트롤러로 데몬 배포, HPA 컨트롤러로 Replica 수 조정 등kubelet에서 바인딩(Binding) 실행
kubelet이, 바인딩된 Node에서 Pod을 실제로 실행합니다.
- kube-controller-manager가
- “무엇을 몇 개”를 만들 것인지(Pod 등 리소스 생성·삭제)를 결정하고 API 호출을 수행하면,
- kube-scheduler는
- “어디에” 배치할지(어떤 노드에 놓을지) 결정하여 Binding을 수행합니다.
실습
AWS EKS환경에서 Control Plane은 고객이 직접 접근할 수 없는 완전 관리형(Managed) 서비스로 운영됩니다. 때문에, kubectl로 직접 Control Plane을 접속하진 못하고, AWS CLI도구를 통해 Cluster의 상태를 조회합니다.
kubectl와 Cluster 연결
kubectl은 한번에 하나의 Cluster를 연결하여 명령어를 실행합니다.
이때, ‘Context’라는 개념으로 Cluster와의 연결을 생성합니다.
kubectl과 EKS Cluster 연결
AWS CLI 명령어를 통해, EKS Cluster에 대한 Context를 쉽게 생성할 수 있습니다.
1
2
$ AWS_PROFILE=**** aws eks update-kubeconfig --region ap-northeast-2 --name workshopdapne2-yeov
Added new context arn:aws:eks:ap-northeast-2:0000000:cluster/workshopdapne2-yeov to /Users/****/.kube/config
Local환경에 있는 Cluster목록(Context) 조회
1
2
$ kubectl ctx
arn:aws:eks:ap-northeast-2:0000000:cluster/workshopdapne2-yeov
Cluster 상태 조회
1
2
$ AWS_PROFILE=**** aws eks describe-cluster --name workshopdapne2-yeov --query "cluster.status"
"ACTIVE"
References
- Componentes | kubernetes.io
- Kubernetes Components
- Cluster Architecture | kubernetes.io
- Cluster Architecture
- Admission control | kubernetes.io
- Admission Control in Kubernetes
- etcd Learning | etcd.io
- Learning
- Etcd란? | IBM
- etcd란 무엇인가요? | IBM
- Raft 알고리즘
- Raft (algorithm)
- kube-scheduler | kubernetes.io
- Kubernetes Scheduler
- Scheduling Framework | kubernetes.io
- Scheduling Framework
- kube-controller-manager, Controllers | kubernetes.io
- Controllers
- Horizontal Pod Autoscaling | kubernetes.io
- Horizontal Pod Autoscaling
- Understanding Kubernetes Architecture | devopscube.com
- Understanding Kubernetes Architecture: A Comprehensive Guide