Ensemble Learning- XGBoost
What is XGBoost?
Decision Tree의 발전 역사
- Decision Trees
Bagging(Bootstrap aggregating)
sample 데이터를 랜덤으로 선택하여 여러개의 ‘bootstrap’으로 묶고, 이 ‘bootstrap’으로 모델을 학습시키는 방법. sample 데이터의 다양성을 확보하는것.
규칙적으로 sample 데이터의 일부를 제외하는 ‘K-fold’와는 다릅니다.Random Forest
Bagging을 기초로 하지만, Bagging에서 feature를 random하게 subset으로 만들어서 활용합니다.- Adaptive Boosting
여러 모델을 만들어 내는데, 각 모델을 sequential하게 만들어집니다. 이 과정에서, 계속 틀리는(못 푸는) sample데이터에 가중치를 줘서, 뒤로 갈 수록 해당 sample에 대해 강화된 모델을 만들도록 하는 방법입니다. Gradient Boosting
모델이 만들어낸 ‘residual(잔차, $\hat{y}$과 $y$의 차이)’에 대해서 sequential하게 학습하여 여러 모델을 만들어내는 방법.
‘residual’에 대해서 학습하기 때문에, ‘overfit(과적합)’가능성이 높습니다. 때문에, 여러 ‘regularization’을 이용하게 됩니다.- XGBoost
“‘Gradient Boosting’을 좀 더 빠르게, 대용량 데이터에 대해서 대응되게 돌릴 수 있을까?”를 기본으로 만들어진 ‘Gradient Boosting’의 최적화(optimized) 모델입니다.
XGBoost는 ‘Gradient Boosting Algorithm’입니다.
기존과 다르게, Split Finding Algorithm(병렬처리에 대한 얘기)을 사용합니다.
XGBoost에서 하고자 하는것.
Decision Tree에서의 문제 개선.
Decision Tree같은 경우, ‘Basic exact greedy algorithm’로서 반드시 최적의 결과물(optimal point)를 찾아냅니다.(모든 가능성을 확인하기 때문에)
- 하지만,
- 데이터 자체가 메모리에 모두 들어가지 못하는 경우, 알고리즘을 사용하지 못하는 문제가 있으며,
- 모든 가능성을 탐색해야 하므로, 분산(distributed)환경에서 처리가 불가합니다.
그래서, ‘Approximate algorithm’을 사용합니다.
Split Finding Algorithm

‘decision tree’에선, 모든 example 사이에 ‘split point(분할 point. left node, right node로 분할하는 point)’를 두고, 어떤게 최적의 ‘split point’인지 찾아 냅니다. 즉 전수조사를 합니다.
‘XGBoost’에선 이를 개선하여, bucket(example을 특정 갯수만큼 묶은것)을 적용합니다.
bucket안에서, bucket 내부의 데이터만 가지고, ‘split point’를 찾습니다.
split point를 찾기 전에, 모든 examples을 ascending으로 정렬해야 합니다.
여기서, bucket 내부의 ‘split point’를 찾는 과정이 bucket단위로 이루어지기 때문에, bucket단위로 병렬처리가 가능합니다.
이런 bucket방식은 ‘approximation’ 접근이기 때문에(모든 경우에수에 대해서 고려하는게 아니기 때문에) 정확한 기준(split point)이 아닐 수 있습니다.
split 단위
split의 기준을 global 혹은 local로 설정할수도 있습니다.
Per Tree(Global variant)

root node에서부터 leaf node에 이르기까지, bucket의 size가 동일합니다.(어쩔 수 없이 잘려야 하는경우는 제외)Per Split(Local variant)
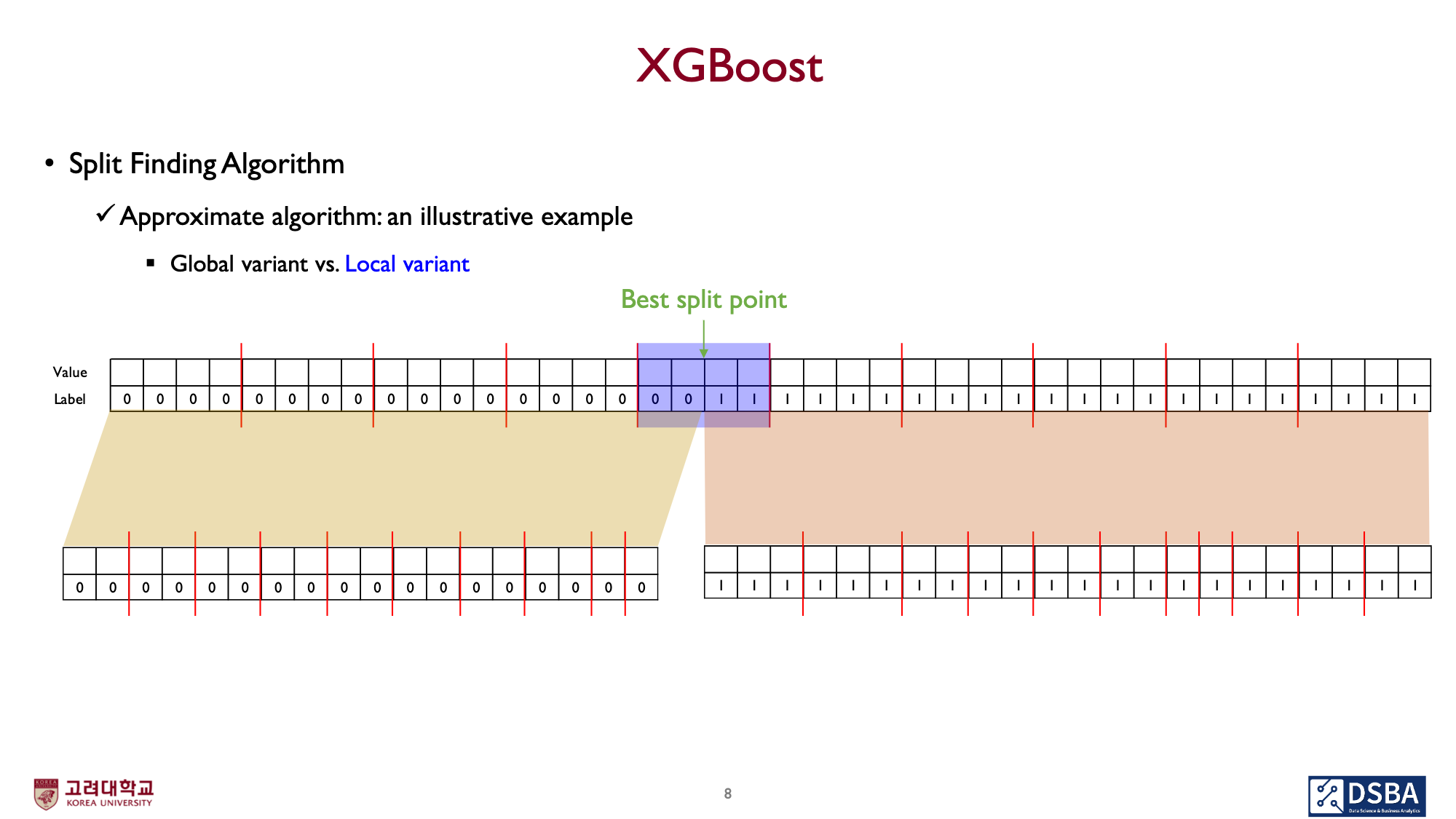
root의 bucket 갯수를 leaf node에 이르기까지 유지합니다.
root node에서 depth가 증가하면서, ‘percentile’에 따라 다시 bucket을 구분합니다.
depth가 깊어질수록, 하나의 bucket에 들어가는 example의 수가 줄어듭니다.
epsilon과 local, global variant의 비교

local와 global중 어느게 더 좋은지는 판단하기 어렵다.
다만, global을 사용하는 경우, epsilon을 작게 가져가야 한다.
Sparsity-Aware Split Finding
현실세계의 데이터에는 변수가 많습니다.
- 특정 데이터(feature value)가 비어 있는 경우.(이런 데이터를 ‘missing data’라고 합니다.)
- 혹은, 0이 너무 자주 출현하는 data인 경우.(one-hot vector 같은)
이와 같은 경우, decision tree에서 어느 방향으로 가야할지 모호합니다.
이를 해결하기 위해, tree를 정의할때 기본 방향(default direction)을 설정하고 이 방향으로 보내도록 합니다.

- 위 이미지의
- 파랑색: ‘missing value’를 모두 오른쪽으로 몰고 정렬합니다. 이를 기준으로 ‘best split point’를 찾습니다.
- 붉은색: ‘missing value’를 모두 왼쪽으로 몰고 정렬합니다. 이를 기준으로 ‘best split point’를 찾습니다.
이 결과, 우측의 특정 feature에 대한 예시같은 경우, 왼쪽 정렬이 가장 나은 결과임을 알 수 있고, 이 ‘왼쪽’이 default direction이 됩니다.
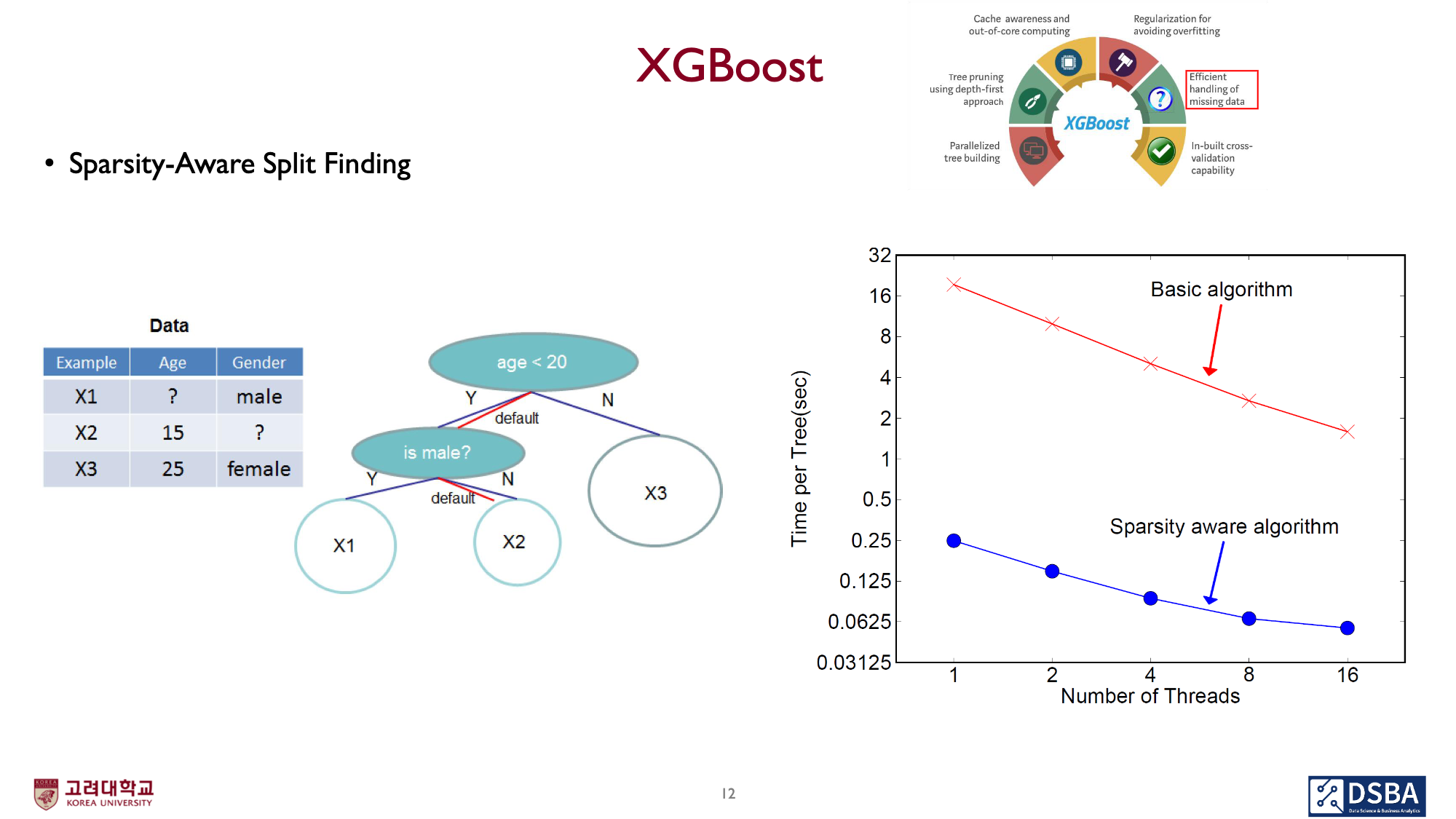
- 이렇게,
- X1 example은 age feature에 대해서는 default direction에 따라 ‘왼쪽’으로
- X2 example은 gender feature에 대해서 missing value 상태이므로, default direction에 따라 ‘오른쪽’으로 이동합니다.
우측의 그래프는 ‘Sparsity aware algorithm’을 적용하는것이 상당한 성능 개선이 있음을 보여줍니다.
System Design for Efficient Computing

이 Decision Tree Learning을 하는데 가장 time-consuming한것이 뭘까?
각 feature의 데이터들을 정렬하는것입니다.
이는 최적의 알고리즘(Quick sort)을 사용하더라도, $O(n\log{n})$의 비용이 들며, example의 size에 비례합니다.
하지만, 이 ‘정렬’은 데이터 전처리(pre-processing)과정의 문제이기 때문에, 최초 1회 시행되면 되고, 실제 learning에는 영향을 미치지 않습니다.
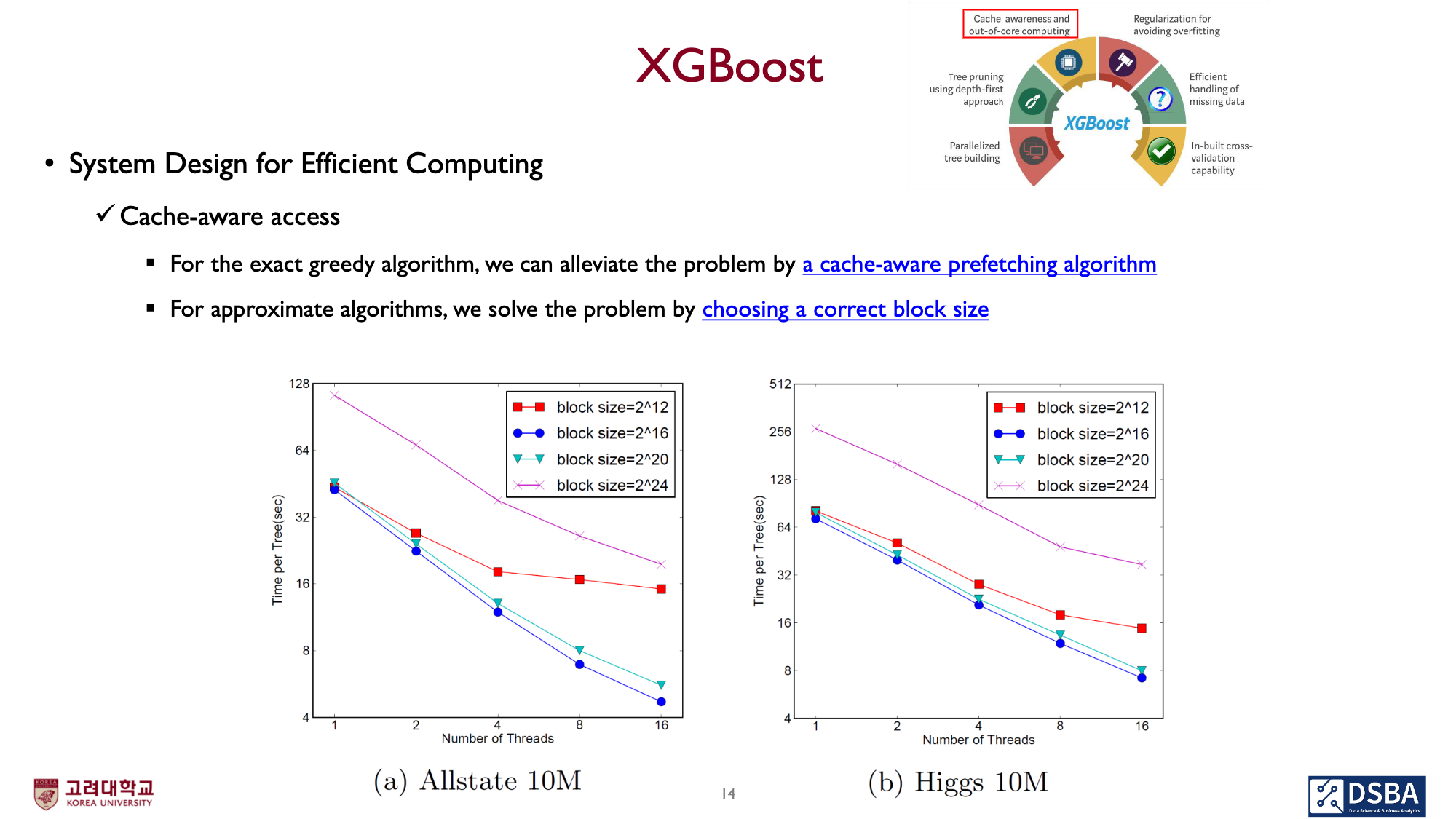
CPU의 hardware cache사이즈에 따라, block사이즈를 조절하여 성능개선 효과를 얻을 수 있습니다.

References
- 고려대학교 일반대학원 산업경영공학과 강의
- 04-7: Ensemble Learning - XGBoost (앙상블 기법 - XGBoost)
- 강의 자료
- origin paper
- XGBoost: A Scalable Tree Boosting System