What is Kafka? | CloudNative

Kafka 소개
- Kafka는
- 대용량의 실시간 데이터 스트리밍을 처리하는 분산(Distributed) 메시징 시스템입니다.
- 원래 LinkedIn에서 개발되었고, 이후 Apache Software Foundation에서 오픈소스로 관리되고 있습니다.
탄생 배경(LinkedIn에서)
로그와 사용자 이벤트 데이터 폭증
‘LinkedIn’에서는 Web에서 사용자들의 행동을 추적(tracking)하고 있었는데, 사용자가 급격하게 늘어남에 따라, 데이터가 폭발적으로 증가하였습니다.
수천만 명의 사용자가 활동하면서 광고 클릭, 검색, 프로필 조회, 추천 요청 등의 이벤트가 초당 수십만 건씩 발생하였으며, 기존의 로그 수집 시스템(파일 로그 → 수집기 → Hadoop ETL)은 이를 감당하지 못했습니다.실시간 분석 불가능
모든 데이터는 Hadoop에 쌓인 후 배치 처리해야 했습니다.(즉, 실시간 분석이 불가능.)
실시간 분석은 거의 불가능하고, 결과를 보려면 수 시간 또는 하루 이상 지연되었습니다.AMQP(Advanced Message Queuing Protocol)의 한계
LinkedIn에서 처음에는 AMQP서비스들을 고려했다고 합니다. 하지만, AMQP로 분산처리 환경을 구현하는데에 여러 어려움이 있었습니다.
이를 극복하기 위해, 기존에 있던 Messaging System을 고려했지만, 적합한게 없어, Kafka를 만들게 되었습니다.
Kafka의 초기 설계 철학
Kafka는 단순한 메시지 큐가 아니라, 범용 로그 시스템(log-centric system)으로 설계되었습니다.
핵심 철학은 다음과 같습니다.
모든 데이터를 이벤트 로그로 저장합니다.
이벤트 중심(Event-driven) 아키텍처를 채택하였습니다.
모든 시스템 간 통신과 상태 변화를 이벤트 로그로 기록·전파하여, 비동기·분산·확장 가능한 구조를 구현했다는 의미입니다.
모든 시스템 간 통신도 로그 기반 이벤트 스트림으로 표현합니다.
고성능 & 고내구성
디스크에 바로 쓰되, 디스크 I/O를 최적화하여 메모리 버퍼처럼 빠르게 동작합니다.
메시지를 디스크에 저장하되 복제(replication)로 데이터 유실 방지합니다.
단순하고 확장 가능한 API
Producer, Consumer 모두 단순한 API로 통신합니다.
파티셔닝(partitioning)을 통해 수평 확장(Horizontal Scaling)이 쉽습니다.
리플레이 가능한 스트림 처리
데이터는 소비 후에도 삭제되지 않으며, 필요할 때 다시 읽을 수 있습니다.
이 덕분에 재처리, 재분석, 에러 복구가 쉬워집니다.
다양한 시스템 연결을 위한 허브
Kafka를 중심으로 Hadoop, HDFS, Cassandra, Storm 등과 연계하곤 합니다.
즉, Kafka는 데이터의 허브가 됩니다.
Kafka Architecture
Kafka는 여러 Broker를 통해 Cluster를 생성하여, 분산처리를 위한 Architecture를 갖추고 있습니다.
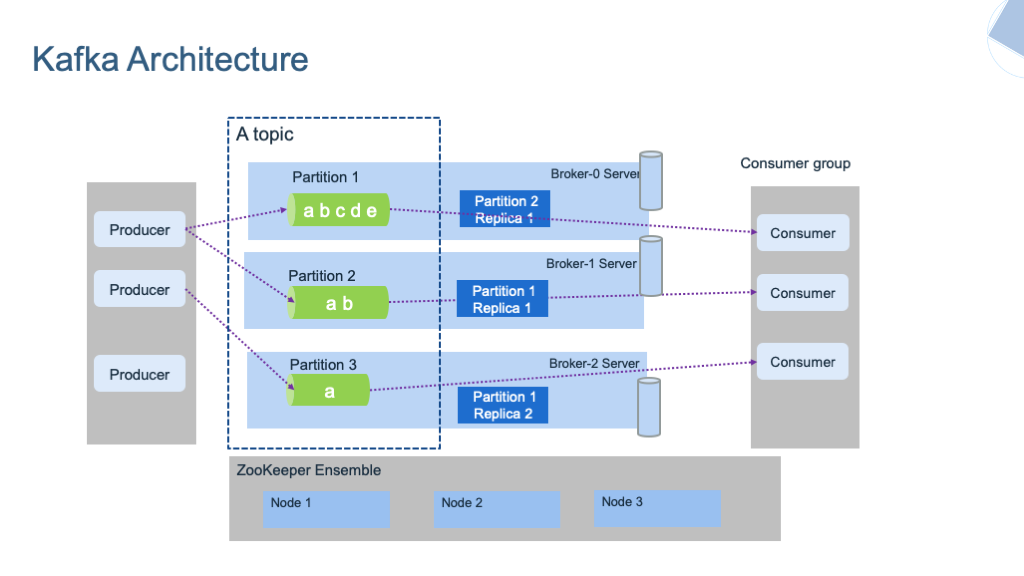 Kafka Cluster Architecture | from ibm-cloud-architecture.github.io
Kafka Cluster Architecture | from ibm-cloud-architecture.github.io
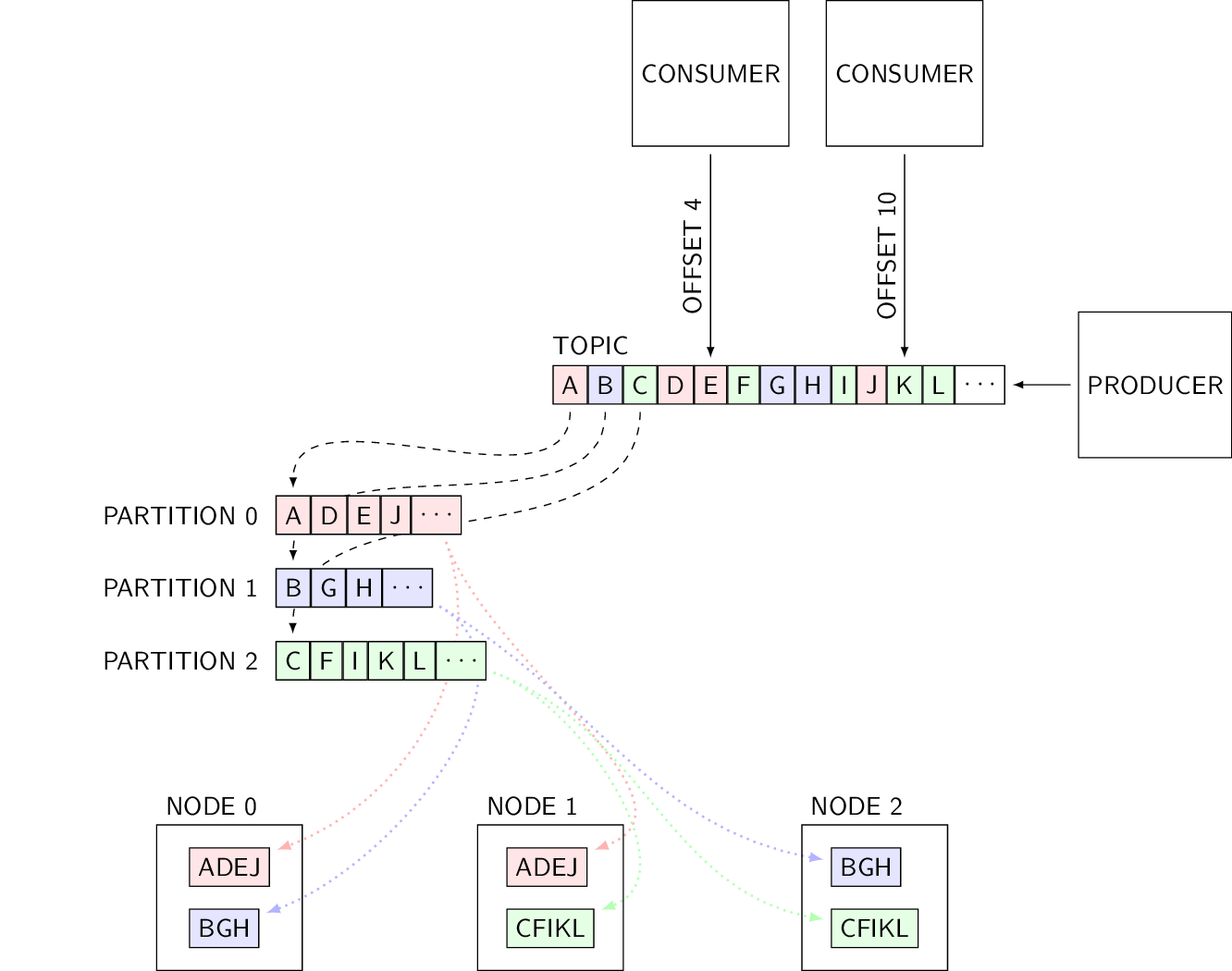 Kafka Architecture with Offset | from d3s.mff.cuni.cz
Kafka Architecture with Offset | from d3s.mff.cuni.cz
Components
Brokers
Kafka는 여러 Broker로 이루어진 Cluster로 운영됩니다. 즉, Broker는 Kafka 서버 인스턴스 하나하나를 의미합니다.
- 이 Broker들은
- 데이터의 Replication을 관리하고,
- Topic/partition을 관리하고,
- Broker안에 있는 Partition의 Offset을 관리합니다.
- Topic/partition을 관리하고,
Broker에는 Topic(실제로 Record Stream이 저장되는 곳)의 Partition이 저장됩니다.
만약, 여러 데이터센터를 걸쳐서 Kafka를 구성한다면, 센터간 15ms이하의 network latency를 요구합니다.
이는 Kafka Broker와 zookeeper사이에 많은 통신이 있기때문입니다.
Production level에선, 최소한 5개의 노드(Broker)를 구성하는게 좋다고 합니다.
Zookeeper(최신버전에서는 KRaft Controller 사용)
- ‘Zookeeper’는
- Component나 Kafka의 상태를 유지하는데 사용됩니다.
- HA(High Availability)를 위해, Cluster형태로 실행됩니다.
- 클러스터의 메타데이터(파티션 배치, ISR, 브로커 생·사 등) 관리합니다.
- HA(High Availability)를 위해, Cluster형태로 실행됩니다.
Kafka Version에 따라, zookeeper에서 offset을 관리합니다.
최신 버젼에서는 Kafka내부에서 ‘consumer offset’이라는 이름으로 관리합니다.
Zookeeper는 Kafka 3.5부터 deprecated처리 되며, 4.0부터는 완전히 제거됩니다.
KRaft Controller(4.0이상부터 default)
- KRaft Controller는
- Zookeeper의 역할을 대체하면서도, Kafka 외부(Zookeeper)의 도움 없이 Kafka 스스로 클러스터가 운영될 수 있도록 합니다.
- Kafka의 아키텍처를 단순화하고, 운영 부담을 감소시켜 줍니다.(ZooKeeper에 대한 관리가 불필요)
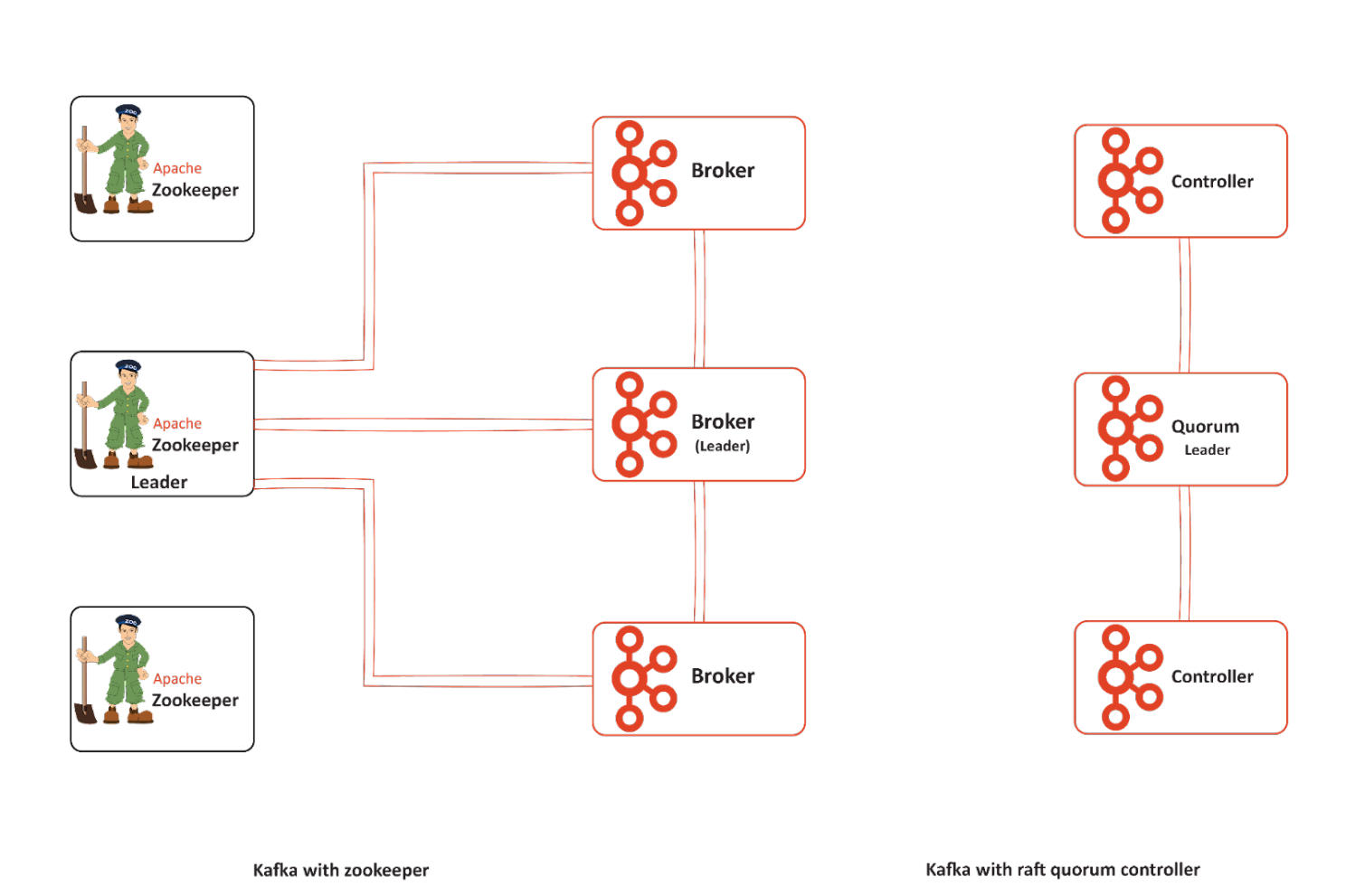 ZooKeeper mode vs. KRaft mode
ZooKeeper mode vs. KRaft mode
Kafka 3.3부터 KRaft가 새 클러스터에 “프로덕션 레디”로 승인되고, 3.5에서 Zookeeper 모드가 deprecated, 4.0에서 제거될 예정입니다.(현재시점 4.0.0 출시)
‘Raft’는 뗏목을 의미하며, Cluster에서 Leader를 선출하는 합의 알고리즘중 하나입니다.
Topics과 Partitions, Replication
- ‘Topic’은
- 메시지 논리 채널입니다.
- Record를 Publish하고, Consume하는 엔드포인트를 제공합니다.
- 하나의 Topic을 N개의 Partition으로 나누어, 각 Partition은 독립적인 append-only(추가만 되는) 로그로 관리합니다.
- Record를 Publish하고, Consume하는 엔드포인트를 제공합니다.
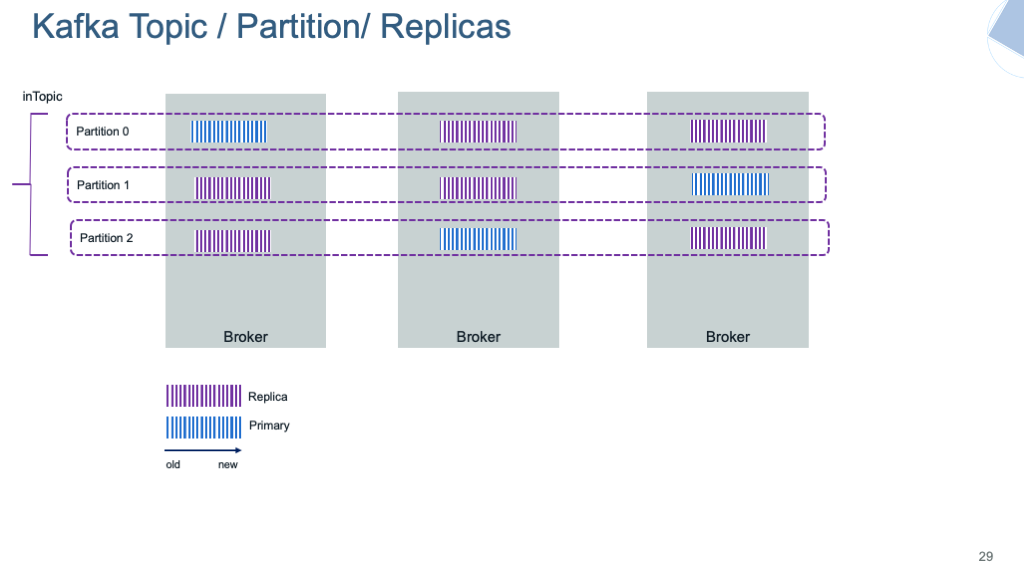 하나의 Topic은 여러개의 Partition과 Replicas로 구성되어 있습니다.
하나의 Topic은 여러개의 Partition과 Replicas로 구성되어 있습니다.
- Partition은
- 단일 서버가 모든 이벤트를 처리할 수 없을 때, Broker Clustering을 사용하여 이벤트 처리를 병렬화하는 데에 사용됩니다.
- Topic을 병렬 처리 단위로 분할하는 개념이며, Broker에 분산 배치되어 쓰기·읽기 부하 분산 구현합니다.
- Consumer나 ‘Traffic pattern’에 따라 파티션의 갯수를 조절할 수 있으며, 각 Broker는 2000개의 파티션을 가질 수 있습니다.
- append-only Log파일로 구현되어 있으며(Disk에 저장), 오래된 Record는 정해진 시간이나, 파일 limit에 도달하면 지워집니다.
- Topic을 병렬 처리 단위로 분할하는 개념이며, Broker에 분산 배치되어 쓰기·읽기 부하 분산 구현합니다.
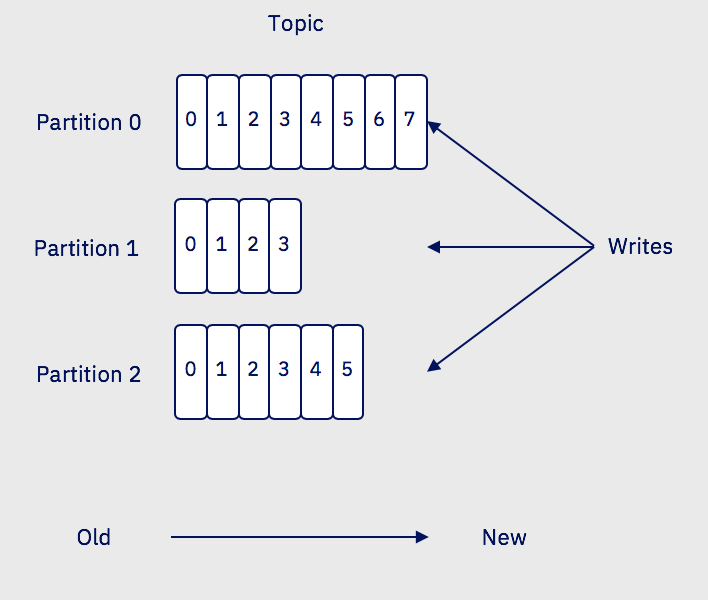 Kafka의 Topic은 여러 Partition으로 이루어져 있습니다.
Kafka의 Topic은 여러 Partition으로 이루어져 있습니다.
- Replication은
- Partition이 여러 Broker(서버)에 걸쳐 복제된 ‘복제본’을 말합니다.
- 각 Partition은 Leader와 하나 이상의 Follower Replica를 갖고 있어, 장애 시에도 데이터 가용성·내구성 유지합니다.
- Leader가 모든 Read/Write 요청을 다루고, Follower는 Leader의 컨텐츠를 복제합니다.
- 각 Partition은 Leader와 하나 이상의 Follower Replica를 갖고 있어, 장애 시에도 데이터 가용성·내구성 유지합니다.
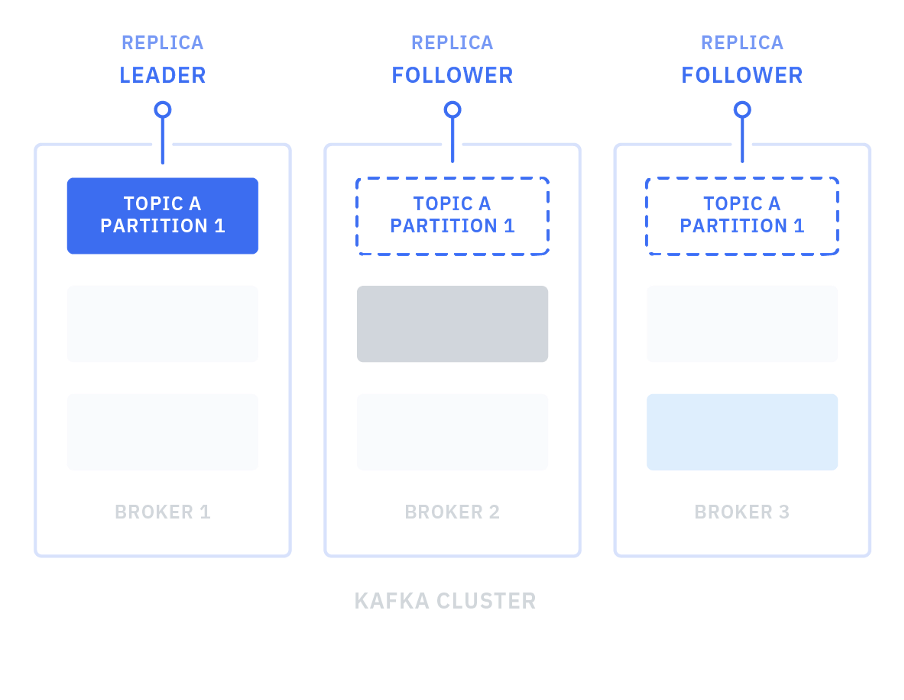 Topic의 Partition과 Replication
Topic의 Partition과 Replication
Producer
A producer is a thread safe kafka client API that publishes records to the cluster.
- from ibm-cloud-architecture.github.io
- ‘Producer’는
- Kafka에 메세지를 등록(publish)하는 Client입니다.
- 초기 연결(initial bootstrap connection)후에, 토픽(파티션)과 연결할 Leader Broker에 대한 메타데이터를 얻습니다.
- 메세지를 파티션에 할당할때,
- Key가 지정되지 않은경우, Round-robin을 사용합니다.
- Key가 정해져 있다면, Key의 Hash값으로 partition이 정해집니다.
- 혹은 이 과정을 Custom할 수 있습니다.
- Key가 정해져 있다면, Key의 Hash값으로 partition이 정해집니다.
Consumer와 Consumer Group
- Consumer는
- 특정 Topic의 Partition에서 Record를 Pull방식으로 가져와서 처리하는 컴포넌트입니다.
- 일반적으로 poll() 루프를 돌며 일정량씩 읽고(fetch), 처리 후 offset을 커밋(commit)합니다.
- Consumer Group은
- 동일한
group.id를 가진, Consumer들의 집합을 ‘Consumer Group’이라고 합니다.- 하나의 Topic 파티션을 그룹 내에서 단 1개의 Consumer만 소비하도록 해서 작업을 분산 합니다(Queue semantics).
- 각 partition마다 최소 1개의 Consumer가 있어야 하며, Consumer가 Group에 하나만 있다면, 모든 partition의 데이터를 다룹니다.
- 하나의 Topic 파티션을 그룹 내에서 단 1개의 Consumer만 소비하도록 해서 작업을 분산 합니다(Queue semantics).
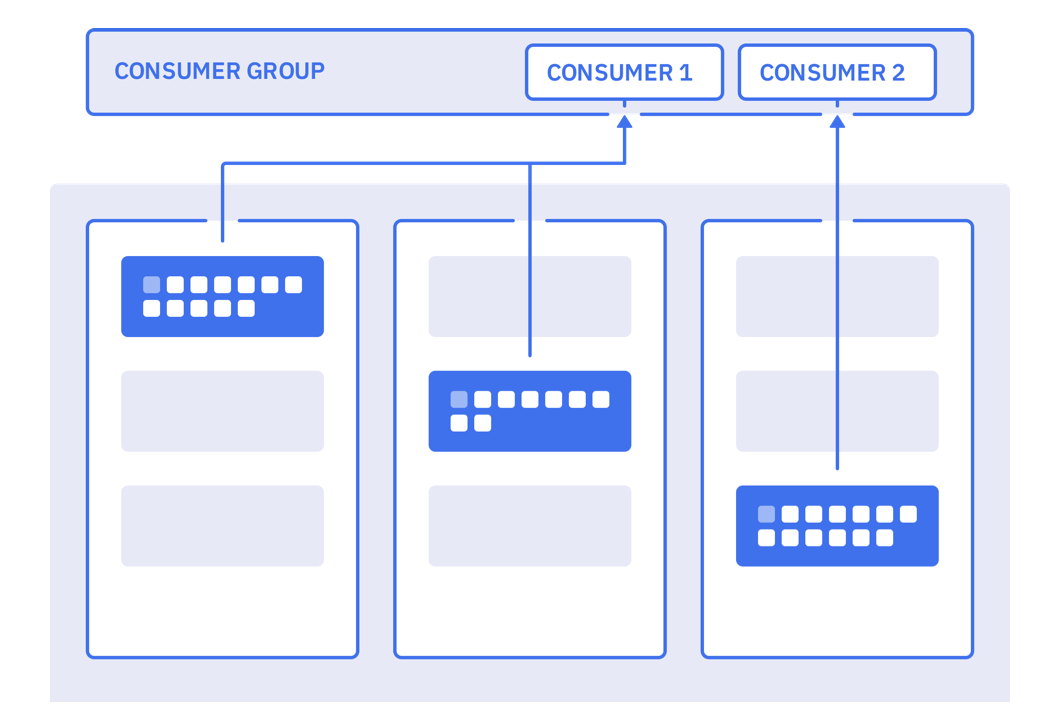 Consumer와 Consumer Group의 관계
Consumer와 Consumer Group의 관계
Message 구조
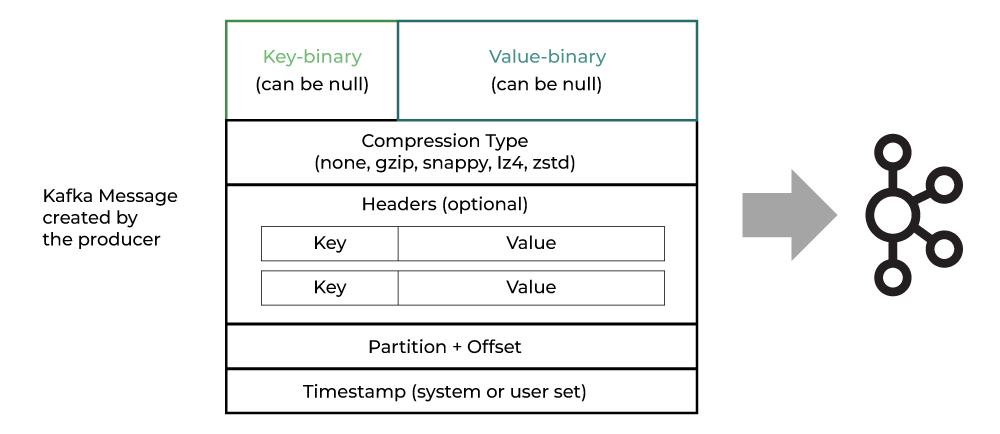 Kafka Message Anatomy | geeksforgeeks.org
Kafka Message Anatomy | geeksforgeeks.org
Message의 Key는 nullable입니다.
key가 null이라면, Round-robin을 통해 random하게 Partition에 할당됩니다.- Compression Type을 통해, Message의 합축을 표현할 수 있습니다.
- Header는 key/value 형식의 Metadata를 저장합니다.
- Partition은 전송 대상을 의미합니다.(어떤 partition에 저장될 지)
- Offset은 Broker가 메세지를 partition에 저장할때 부여되며, Consumer가 읽을 때 확인합니다.
- Timestamp는 이벤트의 생성시간 혹은 Log에 추가된 시간을 의미합니다.
Avro
Avro는 메시지를 직렬화(serialize)할 때 쓰는 포맷/스키마 언어입니다.(Protobuf와 유사)
1
2
3
4
5
6
7
8
9
10
11
// user_event.avsc
{
"type": "record",
"name": "UserEvent",
"namespace": "com.example",
"fields": [
{ "name": "id", "type": "string" },
{ "name": "email", "type": "string" },
{ "name": "age", "type": ["null", "int"], "default": null }
]
}
데이터의 Schema를 JSON형식으로 입력하여 사용합니다. 이를 기반으로 데이터를 Binary로 변환하여 전송합니다.
Schema Registry(Confluent, Apicurio)를 통해, Schema를 등록해서 재사용 하곤 합니다.
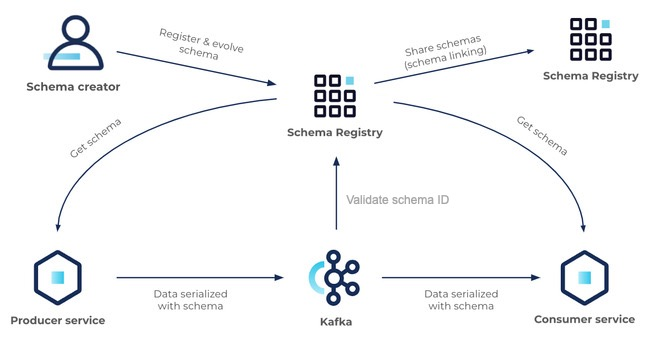 Schema Registry의 사용 Flow | docs.confluent.io
Schema Registry의 사용 Flow | docs.confluent.io
Kafka의 기능과 구현
Producer의 Exactly-Once Delivery(= Exactly-Once Semantics, EOS)
- ‘Exactly-Once Delivery’는
- “재시도·네트워크 오류가 있어도 Kafka 로그에 동일 레코드가 단 한 번만 쓰이고, 다운스트림(다른 토픽/컨슈머)에도 중복 없이 한 번만 보이게 하는 것”을 목표로 합니다.
분산 시스템에서 정확히 한 번만 Delivery하는 것이, 가장 해결하기 어려운 문제 중 하나입니다.
이를 위해 2가지 기능이 결합되어 있습니다.
멱등성(Idempotent)을 제공하는 Producer
Producer에서 메세지의 멱등성(Idempotent)을 위한 기능을 제공합니다.
Producer가 ProducerId(PID) 와 시퀀스 번호를 붙여 전송합니다. → 브로커가 중복 쓰기 감지 후 무시하도록 처리합니다.
같은 파티션에 대한 중복 기록 방지(“딱 한 번 쓰기”)는 보장할 수 있습니다
트랜잭셔널(Transactional) Producer
여러 파티션·토픽에 걸친 쓰기와 Consumer 오프셋 커밋까지 하나의 트랜잭션으로 묶어 정확히 한 번 처리를 보장합니다.
Broker의 Offset Management
“브로커가 오프셋을 관리한다”는 말은 보통 두 가지 Layer를 포함합니다.
- 메시지 자체의 오프셋(Log Offset)을 브로커가 붙입니다.
- “Consumer가 어디까지 읽었는지”를 브로커가 저장해 줍니다(Committed Offset)
Log Offset
메시지 자체의 오프셋(Log Offset)을 브로커가 붙입니다.
각 파티션은 append-only 로그 파일이고, 브로커가 새 레코드가 들어올 때마다 0,1,2…처럼 증가하는 번호(Offset)를 붙여 저장합니다.
그래서 파티션 안에서만 순서가 보장되고, Consumer는 “나는 offset=123부터 읽을래”처럼 요청할 수 있습니다.
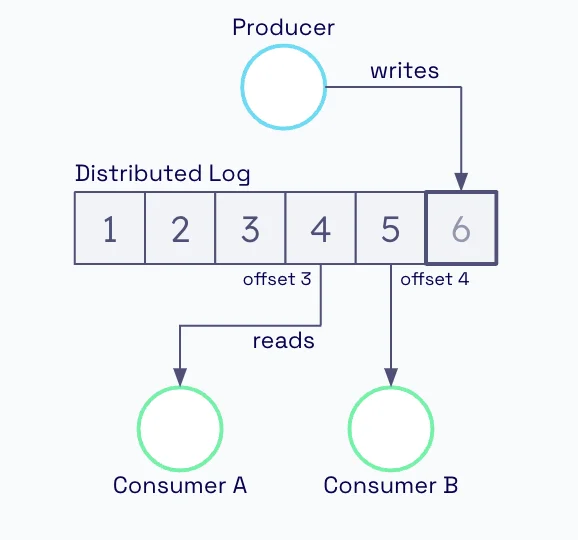 Distributed Log와 Offset | oso.sh
Distributed Log와 Offset | oso.sh
Consumer group과 Committed Offset
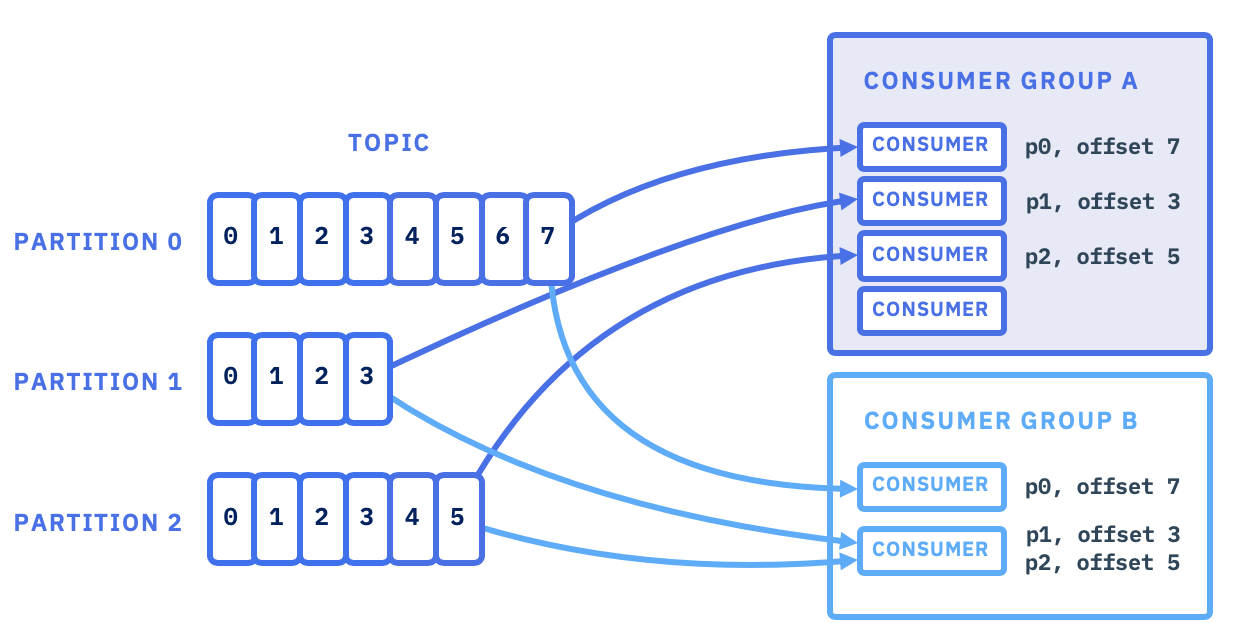 Consumer Group과 Offset의 관계
Consumer Group과 Offset의 관계
“Consumer가 어디까지 읽었는지”를 브로커가 저장해 줍니다. (Committed Offset)
Consumer Group은 처리 완료한 위치(offset)를 커밋(commit)합니다.
이 커밋 정보는 브로커 내부의 __consumer_offsets라는 내부(compacted) 토픽에 저장됩니다.
- 키: (group, topic, partition)
- 값: committed offset + 메타데이터
이렇게 해두면 Consumer가 재시작하거나 다른 인스턴스로 넘어가도 “마지막으로 읽은 지점”을 브로커에서 다시 가져올 수 있습니다.
메세지 순서 보장
같은 Partition 내에서는 메시지 순서(order)가 보장되지만, Partition 간 순서는 보장되지 않습니다.
Consumer Rebalancing
- ‘Consumer Rebalancing’은
- 같은 Consumer Group 안에서 어떤 Consumer가 어떤 파티션을 읽을지 다시 배분하는 과정을 말합니다.
- 새 Consumer가 추가/제거되거나, 파티션 수가 변할 때, “공평하게 나눠 읽도록” 그룹 전체가 잠깐 멈추고 재조정(Rebalancing)합니다.
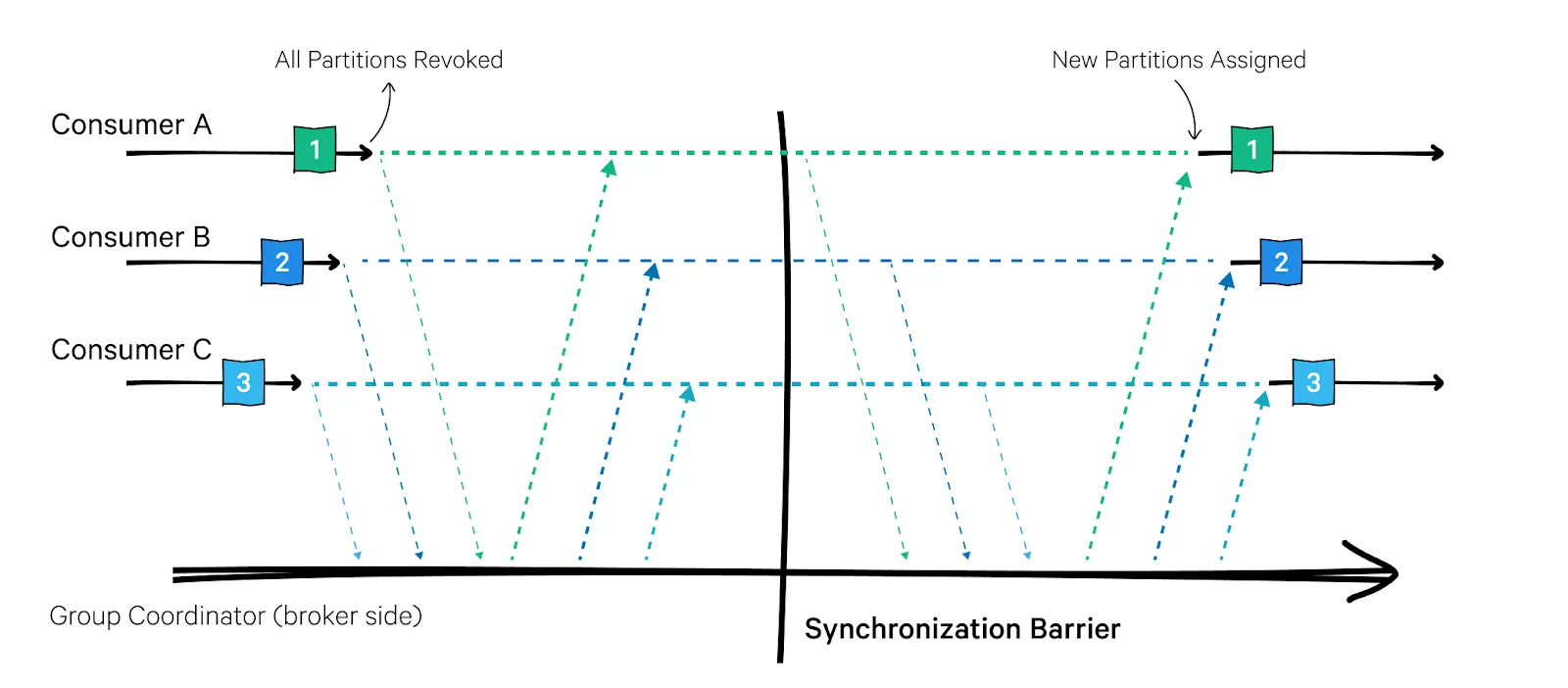 Stop-the-world rebalancing | redpanda.com
Stop-the-world rebalancing | redpanda.com
Rebalancing 발생 환경
그룹 구성에 변화가 있을때.
새 Consumer 추가되거나, 기존 Consumer가 leave 또는 죽음(heartbeat 끊김) 상태일때.- 토픽 파티션 수가 변경될때.
- Group Coordinator가 교체되거나 장애가 발생했을때.
Rebalancing 과정(Eager 방식)
JoinGroup 요청
모든 Consumer가 Coordinator(그룹을 관리하는 브로커)에게 “나 여기 있어요”라고 알립니다.리더 선출 & 파티션 할당 계산
Coordinator가 그룹 내 리더 Consumer를 하나 선출합니다.
리더가 partition.assignment.strategy(Range, RoundRobin, Sticky 등)에 따라 ‘파티션 분배’ 세부 내용을 계산합니다.SyncGroup
리더가 계산 결과를 Coordinator에 전달합니다.
Coordinator가 모든 Consumer에게 “너는 이 파티션들 담당” 통보합니다.재시작
각 Consumer는 자신에게 배정된 파티션을 다시 poll()하기 시작합니다.
Eager방식에서는, 모든 Consumer가 한 번에 파티션을 반납했다가 다시 받기 때문에, ‘Stop-the-world’ 구간이 크다는 단점이 있습니다.
Side effects of Kafka rebalancing
Kafka Rebalancing과정으로 인해, 예기지 않은 side effect가 발생할 수 있습니다.
Latency 증가(Increased latency)
대량 이벤트를 처리하고 있다면, 잦은 리밸런스로 처리가 지연될 수 있습니다.처리량 감소(Reduced Throughput)
poll()이 멈춰 Consumer Lag 증가할 수 있습니다.- 컴퓨팅 리소스 사용량 증가(Increased resource usage)
- 중복 처리 가능성
재시작 전에 커밋 못한 레코드는 재처리될 수 있음 (At-least-once)
Cooperative(Incremental) Rebalancing
- ‘Cooperative(Incremental) Rebalancing’은
- Kafka Consumer Group에서 필요한 파티션만 “부분적으로” 재할당해, 기존의 “모든 파티션을 일단 반납(Eager)” 방식이 만들던 Stop-the-world(중단 시간) 문제를 줄이려는 메커니즘입니다.
- Kafka 2.4+ 클라이언트부터 도입되었습니다.
Consumer Group과 Partition 구성 Best Practice
파티션 수 ≥ Consumer 수로 구성해야 합니다
Consumer가 파티션보다 많으면 일부는 놀게되는 상황이 만들어집니다.수동 커밋 + 에러 처리 전략 수립합니다.
처리가 끝난 후 커밋(At-least-once, 최소한 1회)하도록 설계하고,
재처리를 허용하도록 설계하는게 좋습니다(Idempotency, 멱등성 확보).리밸런스 상황을 최소화 합니다.
긴 처리 작업은 별도 쓰레드/큐로 넘기고 poll 주기를 짧게 유지합니다.
최신 클라이언트를 통해, Cooperative rebalancing 사용하여, Balancing자체를 효율화 합니다.Lag를 모니터링합니다
Latency가 커지면 스케일 아웃 또는 처리 로직 최적화가 필요합니다.여러 Consumer Group으로 팬아웃(fanout, 입력 확장)합니다.
서로 다른 용도(실시간 분석, ETL, 알림 등)는 각기 다른 Consumer Group(다른 group.id)로 독립 소비하도록 구성합니다.
Producer partition strategies
Producer가 Partition에 메세지를 할당하는 Strategy(전략)에 대해서 알아봅니다.
키 기반 해싱 (Keyed Partitioning)(default strategy)
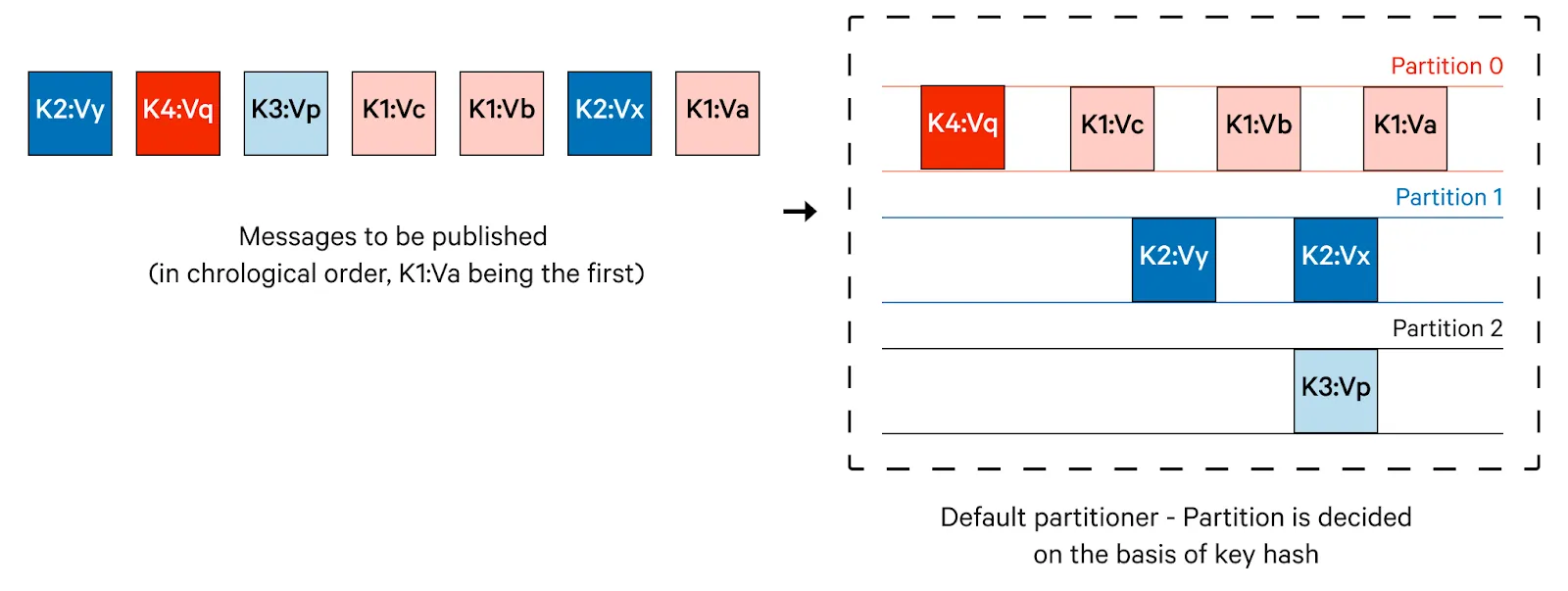 Hash로 작동하는 Default Strategy.
Hash로 작동하는 Default Strategy.
키가 null이 아닐 때의 기본 전략입니다.
같은 키는 항상 같은 파티션에 할당됩니다. → 키 단위 순서 보장해서, 로컬 캐시/상태 활용에 유리합니다.
Round-Robin Partition Strategy
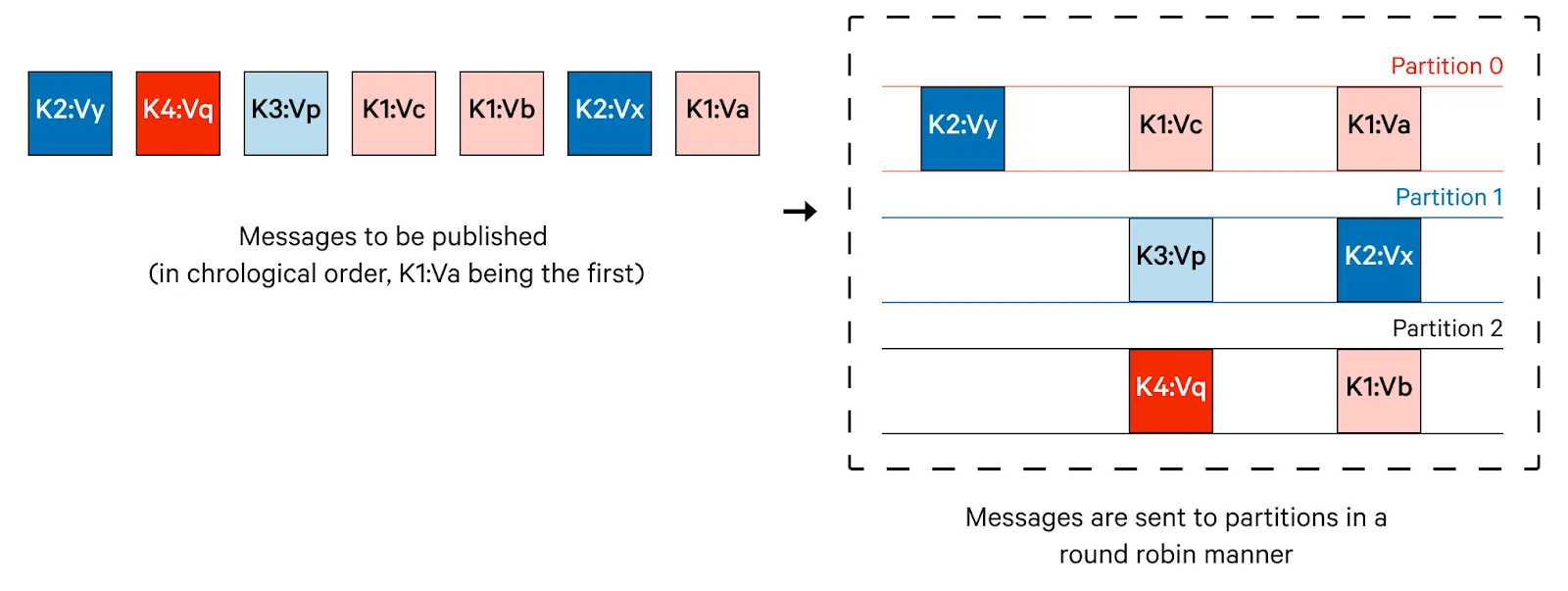 Round-Robin으로 Random하게 분배.
Round-Robin으로 Random하게 분배.
이 전략은 메시지 내용에 관계없이 메시지를 파티션에 순환적으로 할당합니다.
모든 파티션에 메시지가 균등하게 분배되도록 보장하지만, 관련 메시지가 서로 다른 파티션에 배치될 수 있으므로 순서대로 처리된다는 보장은 없습니다.
Sticky Partitioning (키가 null일 때 기본)
키가 null이면 “한 파티션을 당분간 고정(sticky)”해서 배치를 크게 묶어 성능을 향상시켰습니다.
배치를 flush 하거나 파티션 추가/에러 발생 시 다른 파티션을 새로 선택합니다.
Uniform Sticky Partition Strategy
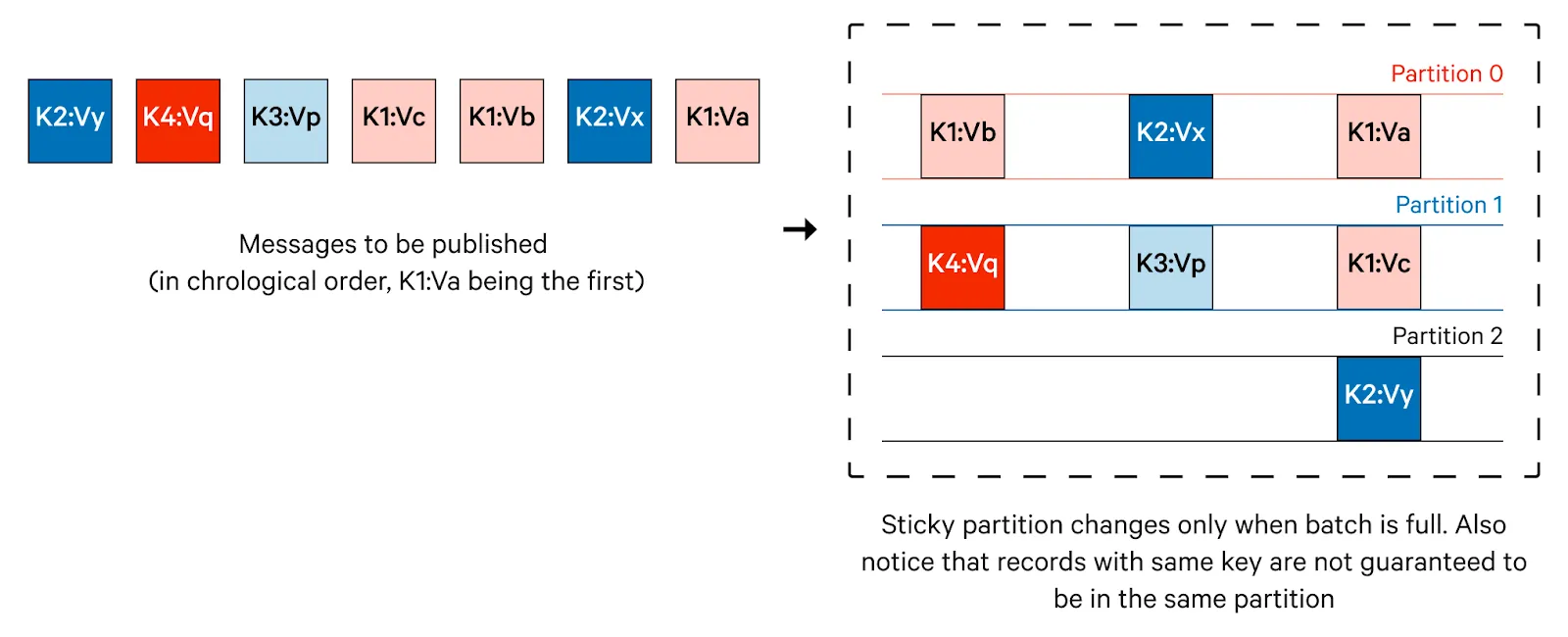 Uniform Sticky Partition Strategy
Uniform Sticky Partition Strategy
Sticky의 장점(큰 배치 유지)을 살리면서 토픽 전체 파티션에 더 균일하게 분배하는 전략입니다.
특히 많은 토픽/파티션을 동시에 다룰 때 분포 불균형을 줄여줍니다.
Consumer assignment strategies
같은 Consumer Group 안에서 파티션을 어떤 규칙으로 나눠 가질지 결정하는 알고리즘입니다.
Rebalancing 때, partition.assignment.strategy에 지정된 클래스가 실행돼 Partition→Consumer 매핑을 계산합니다.
Range assignor (default)
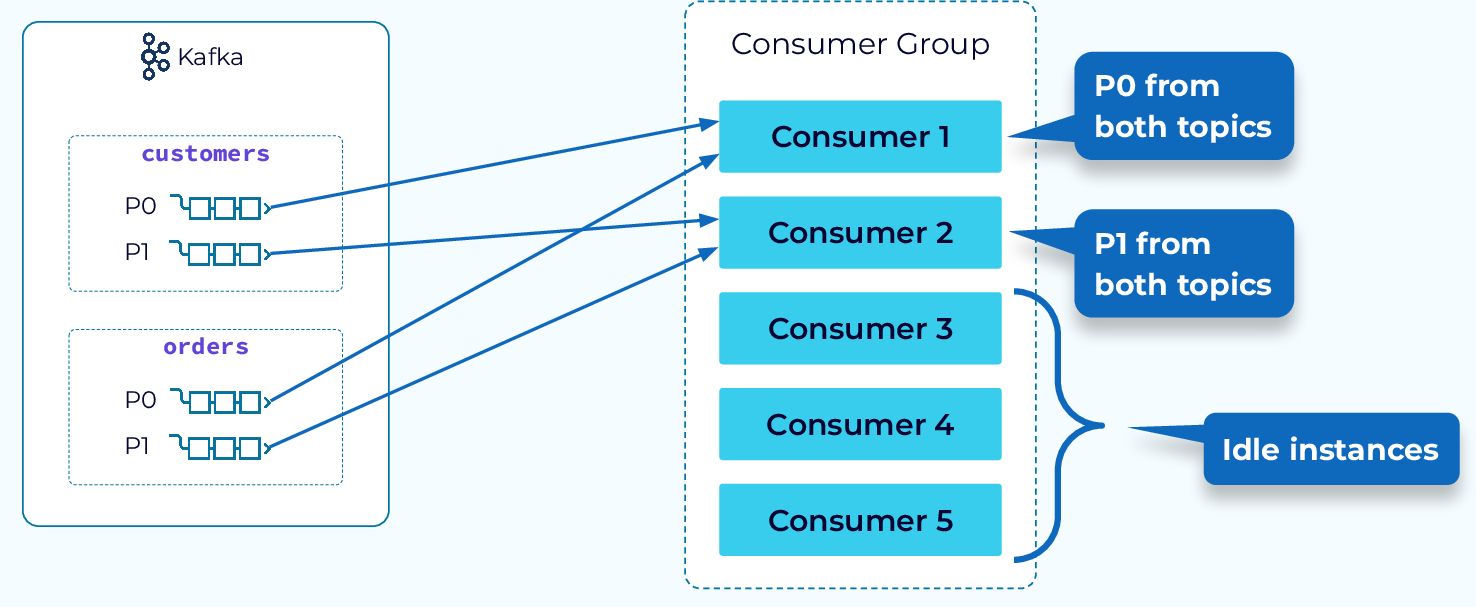 Range assignor | from developer.confluent.io
Range assignor | from developer.confluent.io
토픽별로 파티션을 정렬 후 컨슈머 수로 나눠 “연속 구간(range)” 배정합니다.
즉, 단순하게 파티션을 순서대로 컨슈머에 분배하되, 파티션과 컨슈머가 짝수로 나누어떨어지지 않으면, 앞부분의 컨슈머들에 파티션을 좀 더 가져갑니디.(Round Robin과는 여기서 차이가 있음)
Round-robin assignor
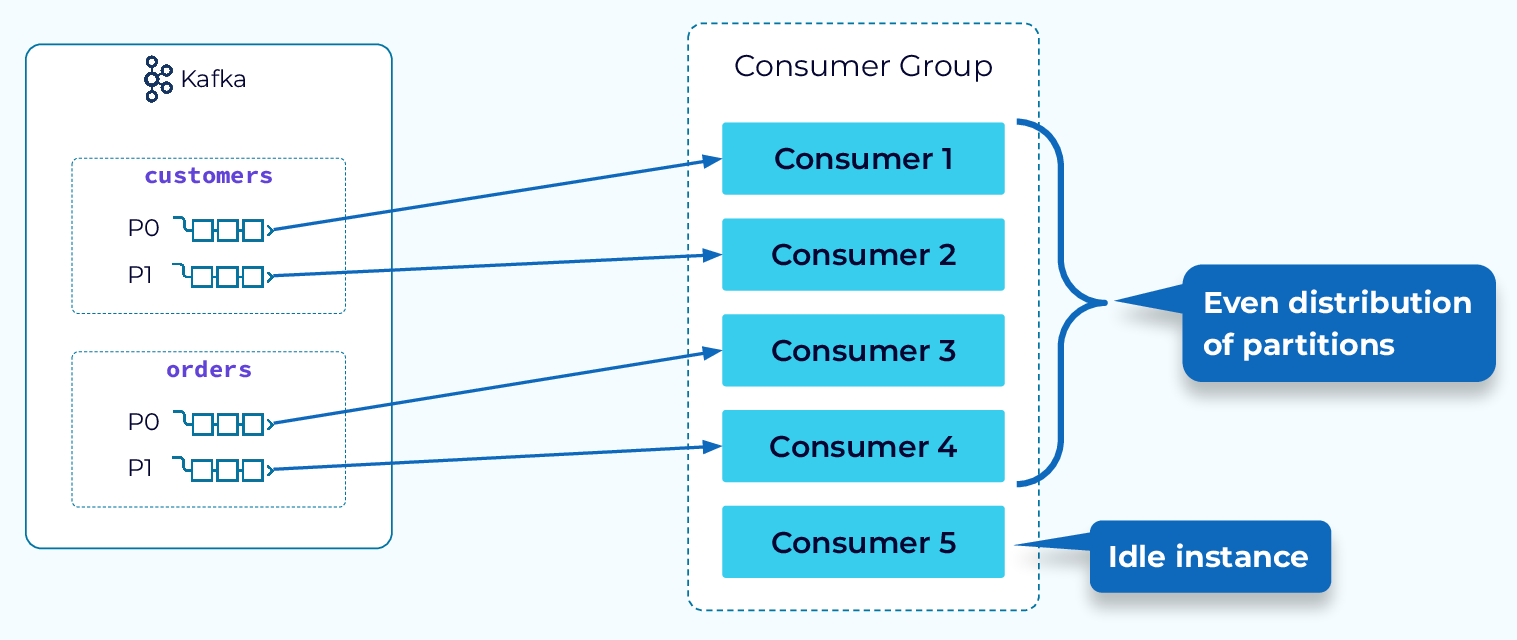 Round-robin Assignor | from developer.confluent.io
Round-robin Assignor | from developer.confluent.io
모든 토픽의 파티션을 하나의 리스트로 붙여 라운드로빈을 돌립니다.(토픽 구분 없이 모든 파티션을 균등 분배.)
사용되는 Consumer 수를 극대화하는 것을 목표로 할때 사용합니다.
하지만, Rebalancing시에, 전체 Partition에 대해 재배치가 이루어저야 하는 문제(Eager Rebalance)가 있습니다. 즉, 일부분의 Partition만 조정하지 못하는 문제가 있습니다.
Sticky assignor
‘Round-robin’과 유사하지만, Rebalancing 할 때에 일부의 Partition만 재배치됩니다.
Cooperative Sticky assignor(권장)
Sticky기반에, ‘필요 파티션만 천천히 이동’하는 assignor입니다.
Eager(전통적)인 assignore는 컨슈머 목록에 변화가 생기면, 모든 Consumer를 반납하고 다시 할당 받습니다. 이 과정에서 ‘Stop-the-world’가 발생하여, Lag 급증, 중복 처리 위험이 발생하게 됩니다.
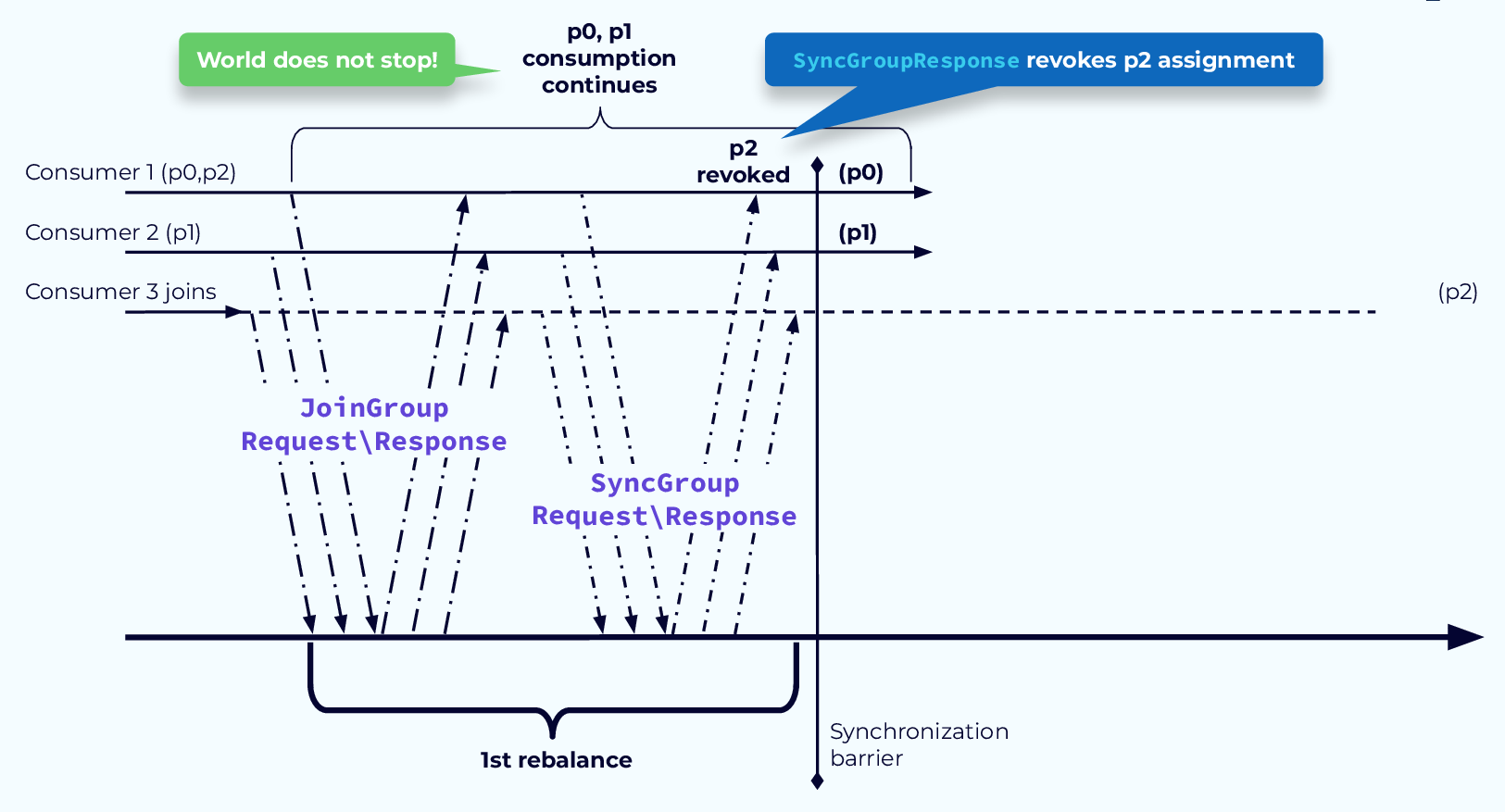 Avoid Pause with CooperativeStickyAssignor Step 1
Avoid Pause with CooperativeStickyAssignor Step 1
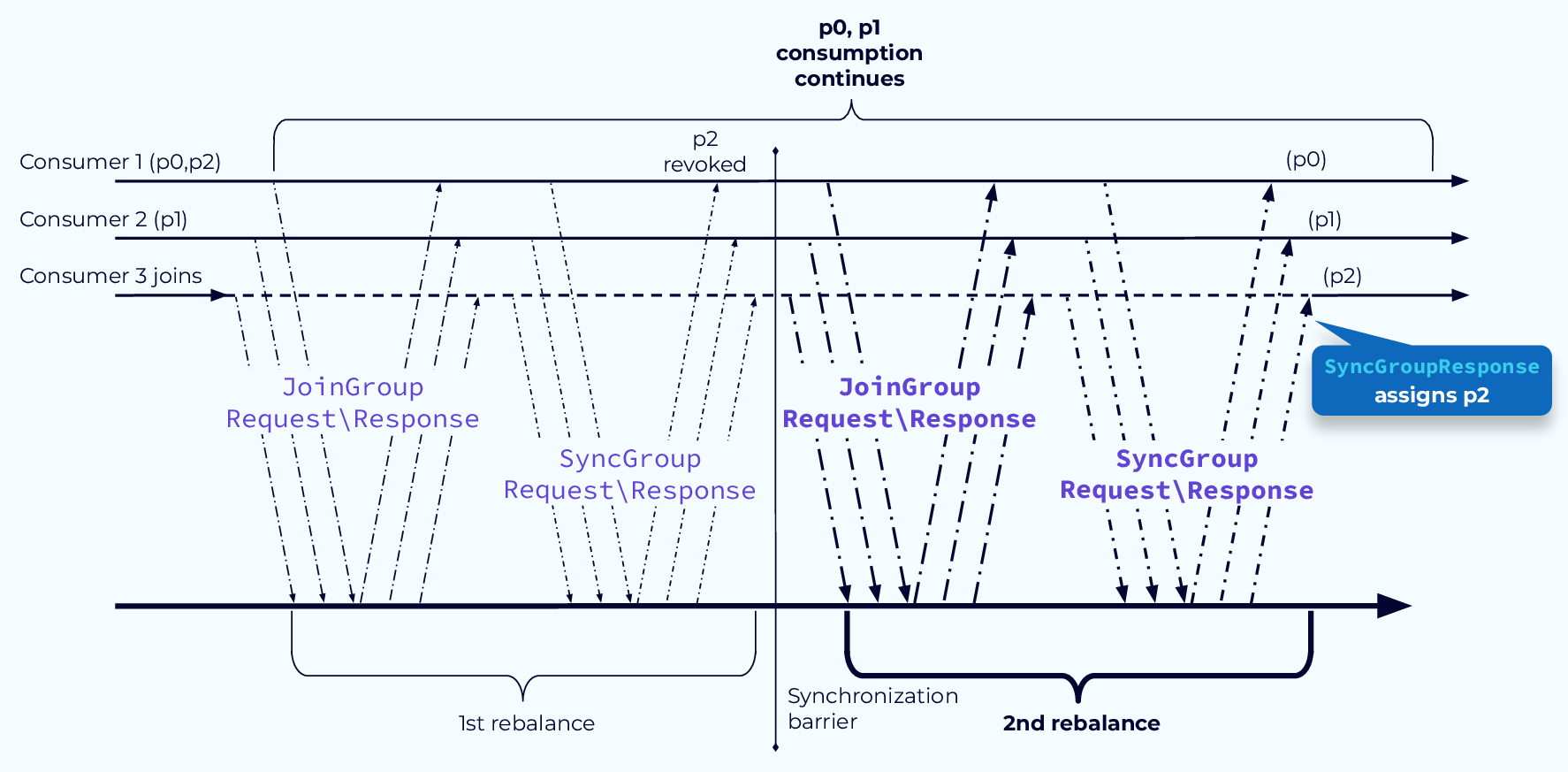 Avoid Pause with CooperativeStickyAssignor Step 2
Avoid Pause with CooperativeStickyAssignor Step 2
두 단계를 거쳐, “필요한 파티션만” 이동시켜 Stop-the-world를 피합니다.
Kafka Message의 Forward/Backward Compatibility 필요성
System이 성장하면서, Kafka의 Message도 계속 성장합니다.
Kafka에서는 Avro를 통해, Schema의 진화(혹은 성장, Schema Evolution)를 가능하게 합니다.
여기서는 Avro를 이용하여, Message의 ‘Forward/Backward Compatibility’가 왜 필요한지 알아봅니다.
Kafka는 장기 보존 & 리플레이(Reprocess)가 가능합니다.
Kafka는 메시지를 며칠~몇 달 이상 보존하고, 언제든 과거 데이터를 다시 읽어 처리합니다.
시간이 흐르면서 메시지 구조가 바뀌어도 과거 이벤트를 해석할 수 있어야 합니다.
Avro는 작성 시점(writer) 스키마와 읽기 시점(reader) 스키마를 맞추는 규칙으로, 과거 데이터도 안전하게 디코딩할 수 있게 합니다.
Producer/Consumer의 독립 배포가 이루어집니다
마이크로서비스 환경에서 Producer와 Consumer는 동시에 배포되지 않습니다.
- Producer가 필드를 추가/변경했는데 만약, Consumer가 구버전이라면..?
- JSON처럼 암묵적인 약속에만 의존하면 쉽게, 시스템이 깨질 수 있습니다.
- Avro + Schema Registry는 호환성 모드(BACKWARD/FORWARD/FULL 등)를 통해 “새 스키마 등록” 자체를 통제하고, 깨지는 변경을 차단합니다.
다양한 Consumer(Analytics, ETL, Alert 등)에 대응해야 합니다.
하나의 토픽을 여러 Consumer Group이 서로 다른 목적/언어/프레임워크로 읽는 환경입니다.
모든 Consumer가 정확한 필드 타입, 기본값, null 허용 여부를 알아야만 안정적으로 처리할 수 있습니다.
Kafka와 RabbitMQ(전통적인 Message Queue)의 차이
Kafka와 RabbitMQ는 그 사용 목적과 디자인된 방향성에 차이가 있습니다.
메시지 전송 방식
- RabbitMQ: 메시지 큐 방식으로 메시지를 큐에 저장한 후, 소비자가 가져가면 메시지가 삭제됩니다. 메시지의 지속성보다는 즉각적인 전달이 중요할 때 적합합니다.
- Kafka: 로그 스트림 방식으로, 메시지가 브로커에 쓰여지면 로그처럼 유지됩니다. 소비자는 오프셋을 기반으로 메시지를 읽기 때문에 여러 소비자가 같은 메시지를 반복적으로 읽을 수 있으며, 메시지가 삭제되지 않고 설정된 기간 동안 저장됩니다.
데이터 영속성 및 내구성
- RabbitMQ: 메시지는 큐에 있고 기본적으로 소비 후 사라지므로 일시적인 데이터 전송에 적합합니다. 영구 큐 설정을 통해 메시지 영속성을 유지할 수 있지만, Kafka와 같은 로그 저장 방식과는 다릅니다.
- Kafka: 기본적으로 데이터가 로그로 유지되기 때문에 저장 기간을 설정하지 않는 한 삭제되지 않습니다. 따라서 데이터의 내구성이 높고 이벤트의 순차적 흐름을 유지하기 위해 적합합니다.
성능 및 처리량
- RabbitMQ: 낮은 지연 시간과 빠른 전송 속도를 제공하여, 단일 메시지의 빠른 처리가 필요한 경우 유리합니다. 하지만 대용량의 데이터 스트리밍이나 로그 수집에는 성능이 한계에 도달할 수 있습니다.
- Kafka: 초당 수백 MB의 데이터를 처리할 수 있는 고성능 스트리밍 시스템으로, 대용량의 실시간 로그 및 이벤트 스트리밍에 적합합니다.
메시지 순서와 중복 처리
- RabbitMQ: 메시지 순서를 보장하지는 않지만, 필요한 경우 순서가 보장되도록 설정할 수 있습니다. 중복 처리 방지를 지원하며 각 메시지를 고유하게 식별하고 소비자에게 전달합니다.
- Kafka: 파티션 내에서 메시지 순서를 보장하며, 메시지가 중복될 수 있습니다. 여러 소비자가 같은 메시지를 반복적으로 읽을 수 있으므로 순차적 로그 분석에 적합합니다.
RabbitMQ는 빠른 메시지 전달과 작업 큐가 필요한 마이크로서비스 통신에 적합하며, Kafka는 대규모 데이터 스트리밍 및 로그 처리에 강점을 갖고 있습니다.
적용 예시
Espresso
Espresso는 LinkedIn의 분산 NoSQL DB입니다.
Kafka는 그 Espresso에서 발생한 변경 사항을 복제·전파하기 위한 내부 커밋 로그/스트림(backbone)으로 쓰입니다.
즉, Espresso가 ‘Source of truth’라면, Kafka는 그 변경을 다른 레플리카나 시스템으로 정확하고 순서 있게 전달하는 파이프 역할을 합니다.
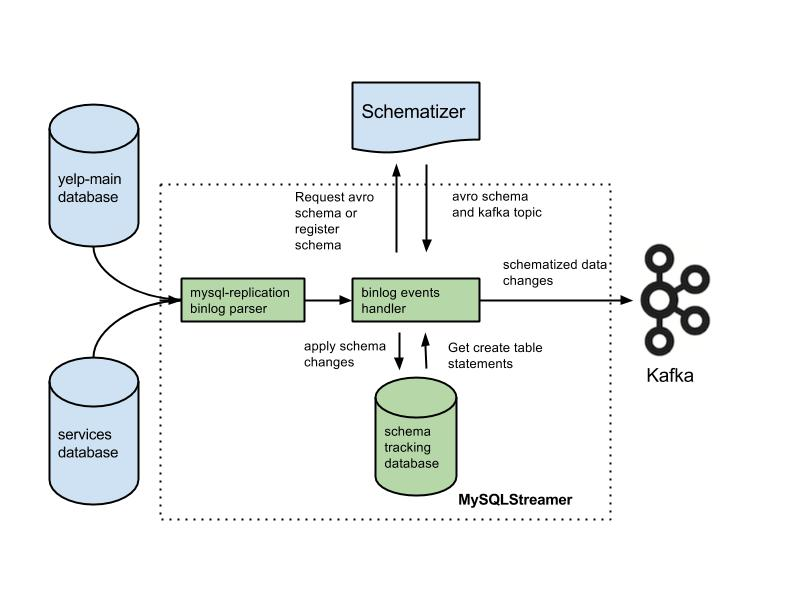 Yelp에서 MySQL DB를 Kafka를 통해 Replication하는 Flow. Kafka에 이벤트를 전달하기까지만 보여줌. | engineeringblog.yelp.com
Yelp에서 MySQL DB를 Kafka를 통해 Replication하는 Flow. Kafka에 이벤트를 전달하기까지만 보여줌. | engineeringblog.yelp.com
Kubernetes에서 적용하기
Kubernetes에서 Kafka를 구성할때는, Operator를 통해 구성합니다.
Strimzi
Strimzi는 Kubernetes(또는 OpenShift) 위에서 Apache Kafka를 쉽게 배포·운영·보안·업그레이드할 수 있도록 해주는 오픈소스 Kafka 오퍼레이터 세트입니다.
References
- Apache Kafka | kafka.apache.org
- Apache Kafka
- Kafka Overview | ibm-cloud-architecture.github.io
- Kafka Overview - IBM Automation - Event-driven Solution - Sharing knowledge
- LinkedIn and Apache Kafka | linkedin.com
- LinkedIn and Apache Kafka
- Kafka Ecosystem at LinkedIn | linkedin.com
- Kafka Ecosystem at LinkedIn
- Kafka at LinkedIn: Current and Future | engineering.linkedin.com
- Kafka at LinkedIn: Current and Future
- Kafka on Kubernetes: Reloaded for fault tolerance | engineering.grab.com
- Kafka on Kubernetes: Reloaded for fault tolerance
- The Fundamentals of Apache Kafka Architecture | developer.confluent.io
- Apache Kafka Architecture Deep Dive
- How LinkedIn Customizes Its 7 Trillion Message Kafka Ecosystem | blog.bytebytego.com
- How LinkedIn Customizes Its 7 Trillion Message Kafka Ecosystem
- Jay Kreps Hadoop Summit 2011 Building Kafka and LinkedIn’s Data Pipeline | youtube.com
- Jay Kreps Hadoop Summit 2011 Building Kafka and LinkedIn’s Data Pipeline
- Building a Real-time Data Pipeline: Apache Kafka at LinkedIn | youtube.com
- Building a Real-time Data Pipeline: Apache Kafka at LinkedIn
- How Kafka Producers, Message Keys, Message Format and Serializers Work in Apache Kafka? | geeksforgeeks.org
- How Kafka Producers, Message Keys, Message Format and Serializers Work in Apache Kafka? - GeeksforGeeks
- Apache Kafka | d3s.mff.cuni.cz
- 2.11 Apache Kafka
- Apache Avro | avro.apache.org
- Documentation
- About Schema Registry | docs.confluent.io
- Schema Registry for Confluent Platform | Confluent Documentation
- Kafka Partition Strategies | github.com/AutoMQ
- Kafka Partition: All You Need to Know & Best Practices
- Kafka partition strategy | redpanda.com
- Kafka Partition Strategies: Optimize Your Data Streaming
- Consumer Group Protocol | developer.confluent.io
- Consumer Group Protocol: Scalability and Fault Tolerance
- Guide to Consumer Offsets: Manual Control, Challenges, and the Innovations of KIP-1094 | confluent.io
- Kafka Consumer Offsets Guide—Basic Principles, Insights & Enhancements
- Kafka Rebalancing: Triggers, Side Effects, and Mitigation Strategies | redpanda.com
- Kafka Rebalancing: Triggers, Effects, and Mitigation
- Kafka consumer lag—Measure and reduce | redpanda.com
- Kafka consumer lag - Measure and reduce
- Kafka와 RabbitMQ비교 | ibm.com
- What is Apache Kafka? | IBM
- Introducing Espresso - LinkedIn’s hot new distributed document store | engineering.linkedin.com
- Introducing Espresso - LinkedIn’s hot new distributed document store
- Espresso Database Replication with Kafka | confluent.io
- Espresso Database Replication with Kafka - Confluent | KR
- Streaming MySQL tables in real-time to Kafka | engineeringblog.yelp.com
- Streaming MySQL tables in real-time to Kafka
- strimzi | strimzi.io
- Strimzi - Apache Kafka on Kubernetes
- Scaling Elasticsearch Across Data Centers With Kafka | elastic.co
- Scaling Elasticsearch Across Data Centers With Kafka