Chapter 1- Reliable, Scalable, and Maintainable Applications
이 1장에서는 책 전반에서 사용하는 전문 용어(terminology)와 접근 방식(approach)을 소개합니다.
신뢰성(reliability), 확장성(scalability), 유지보수성(maintainability) 같은 단어의 실제 의미와 목표를 당설하기 위해 어떻게 해야하는지 알아봅니다.
Reliability(신뢰성)
소프트웨어에 대한 Reliability에 대한 기대치는 다음과 같습니다.
The application performs the function that the user expected.
어플리케이션은 사용자가 기대한 기능을 수행한다.It can tolerate the user making mistakes or using the software in unexpected ways.
시스템은 사용자가 범한 실수나 예상치 못한 소프트웨어 사용법을 허용할 수 있다.Its performance is good enough for the required use case, under the expected load and data volume.
시스템 성능은 예상된 부하와 데이터 양에서 필수적인 사용 사례를 충분히 만족한다.The system prevents any unauthorized access and abuse.
시스템은 허가되지 않은 접근과 오남용을 방지한다.
Fault-tolerant(내결함성) or Resilient(탄력성)
Fault(결함)은 ‘잘못 될 수 있는 일’을 말합니다. 이 fault를 대처할 수 있는 시스템을 ‘Fault-tolerant(내결함성)’ 또는 ‘Resilient(탄력성)’을 지녔다고 말합니다.
‘Fault-tolerant’가 모든 결함을 견딜 수 있는 시스템을 의미하긴 하지만 실현가능하진 않습니다.(자연재해 같은 통제 불가능한 경우가 있습니다) 그래서 ‘특정 유형’에 대해서만 내성이 있는것으로 여깁니다.
Fault와 Failure
‘Fault’와 ‘Failure’는 동일하지 않습니다. ‘Fault’는 시스템의 한 구성요소(Composite)으로 여겨지지만, ‘Failure’는 사용자에게 서비스를 제공하지 못하고 시스템이 멈춘것을 의미합니다.
Fault-tolerant를 증가시키는 방법
고의적으로 결함을 유도함으로써 Fault-tolerant(내결함성) 시스템을 지속적으로 훈련합니다.
Netflix의 Chaos Monkey가 이런 접근 방식을 사용하고 있습니다.
Netfilx의 Chaos Monkey는 (Blog글에 따르면), AWS의 Production환경의 instance를 무작위로 마비시킨다고 합니다. 이를 통해 엔지니어들은 더 나은 ‘자동 복구’를 구축하도록 노력한다고 합니다.
보통은 결함을 예방하는것을 넘어서서 Fault-tolerant(내결함성)을 원하지만, 해결책이 없는경우와 같이 예방하는것이 더 나은 경우가 있습니다. 대표적으로 ‘Security(보안)’ 문제 입니다.
Hardware Faults
하드웨어 장치로부터 기인한 ‘fault’ 유형입니다. 무작의적이고 서로 독립적인 특징이 있습니다.
최근까지 ‘single machine’(1개의 장비로 운영되는 시스템)의 전체 장애는 매우 드물었기 때문에, 하드웨어를 중복으로 준비하는걸로 충분히 대응할 수 있었습니다.
하지만, 데이터의 양과 어플리케이션에 대한 의존성이 늘어나면서 더 많은 수의 장비를 사용하게 되었고, 하드웨어 결함율도 비례하여 증가하였습니다. 또한 AWS와 같은 Public Cloud에서 instance가 별도의 경고없이 사용중지되는 경우도 있습니다.
따라서, 소프트웨어도 ‘fault-tolerant’를 사용하는 시스템으로 옮겨가고 있습니다.
Software Errors
Software에서 기이한 ‘fault’ 유형입니다. 예상하기 어렵고, 노드간에 상관간계가 있어, ‘hardware faults’보다 더 자주 system error를 발생시킵니다.
Software Errors의 예시는 다음과 같습니다.
A software bug that causes every instance of an application server to crash when given a particular bad input. For example, consider the leap second on June 30, 2012, that caused many applications to hang simultaneously due to a bug in the Linux kernel.
It’s Time to Ditch the Leap Second: The Devastating Effect of Adding Just 1 Second
Leap second hits Qantas air bookings, while Reddit and Mozilla stutter- A runaway process that uses up some shared resource—CPU time, memory, disk space, or network bandwidth.
- A service that the system depends on that slows down, becomes unresponsive, or starts returning corrupted responses.
- Cascading failures, where a small fault in one component triggers a fault in another component, which in turn triggers further faults [10].
이런 bug는 특정 상황에 마주하기 전까지 오랫동안 나타나지 않을 수 있습니다.
‘Software Errors’에는 신속한 해결책이 없으며, 아래의 것들이 해결에 도움을 줍니다.
- carefully thinking about assumptions and interactions in the system
- thorough testing
- process isolation
- allowing processes to crash and restart
- measuring, monitoring, and analyzing system behavior in production
Human Errors
사람에 기인한 ‘fault’유형입니다. 사람이 최선의 의도를 갖고 있다해도, 미덥지 않다고 알려져 있습니다. 대규모 인터넷 서비스에 대한 연구에 따르면, 운영자의 설정 오류가 중단의 주요 원인이라고 합니다.
그럼에도 시스템의 ‘Reliability’를 어떻게 챙길까요?
Design systems in a way that minimizes opportunities for error. For example, well-designed abstractions, APIs, and admin interfaces make it easy to do “the right thing” and discourage “the wrong thing.” However, if the interfaces are too restrictive people will work around them, negating their benefit, so this is a tricky balance to get right.
잘 디자인된 ‘abstraction(추상화)’는 ‘정상적인 일’은 쉽게하고, ‘잘못된 일’은 어렵게 합니다.Decouple the places where people make the most mistakes from the places where they can cause failures. In particular, provide fully featured non-production sandbox environments where people can explore and experiment safely, using real data, without affecting real users.
사람이 실수할 수 있는 부분을 decouple(분리)시킵니다. 실제 데이터를 활용한 ‘sandbox’환경을 제공해야 합니다.- Test thoroughly at all levels, from unit tests to whole-system integration tests and manual tests. Automated testing is widely used, well understood, and espe‐ cially valuable for covering corner cases that rarely arise in normal operation.
- Allow quick and easy recovery from human errors, to minimize the impact in the case of a failure. For example, make it fast to roll back configuration changes, roll out new code gradually (so that any unexpected bugs affect only a small subset of users), and provide tools to recompute data (in case it turns out that the old com‐ putation was incorrect).
- Set up detailed and clear monitoring, such as performance metrics and error rates. In other engineering disciplines this is referred to as telemetry. (Once a rocket has left the ground, telemetry is essential for tracking what is happening, and for understanding failures [14].) Monitoring can show us early warning sig‐ nals and allow us to check whether any assumptions or constraints are being vio‐ lated. When a problem occurs, metrics can be invaluable in diagnosing the issue.
- Implement good management practices and training—a complex and important aspect, and beyond the scope of this book.
Scalability(확장성)
‘Scalability’는 증가한 부하에 대처하는 ‘시스템 능력’을 설명하는데 사용됩니다.
Describing Load(부하 기술하기)
시스템의 현재 ‘Load(부하)’를 간결한게 기술해야합니다. 이는 부하 성장 질문(”부하가 두 배로 되면 어떻게 될까?”)을 논의할 수 있게 합니다.
‘Load’를 설명하는 ‘Load parameter’는 시스템 구조에 따라 달라집니다. 이 구조에 따라,
requests per second to a web server, the ratio of reads to writes in a database, the number of simultaneously active users in a chat room, the hit rate on a cache, or something else
과 같은 값이 parameter가 될 수 있습니다.
Twitter(트위터) 예시(from Timelines at Scale)
트위터의 주요 동작은 다음과 같습니다.
Tweet(트윗) 작성
사용자는 새로운 메세지를 개시할 수 있습니다.(평균 초당 4.6k요청, 피크(peak)일 때 초당 12k 요청 이상)Timeline(홈 화면의 타임라인)
사용자는 팔로우한 사람의 tweet을 볼 수 있습니다.(초당 300k요청)
write 작업에 해당하는 ‘tweet작성’이 12k인건 다루기가 상당히 쉽습니다.
하지만, 트위터의 확장성 문제는 ‘fan-out’에 있습니다. 이 ‘fan-out’은 1개의 tweet을 여러 팔로어들에게 노출해야하는 요구사항 때문에 생깁니다.
‘fan-out’은 입력(input)을 여러개의 출력(output)으로 확장하는것을 말합니다. 즉 1개의 신호를 여러 machine에서 처리할 수 있게 확장하는것을 말합니다. fan-out의 output(출력)은 다른 기능의 input(입력)이 됩니다.
 Twitter의 Timeline기능 예시
Twitter의 Timeline기능 예시
이를 해결하기 위해서,
- 관계형 데이터베이스를 이용하고, query를 통해 구현하는 방법이 있습니다.
- tweet이 등록되면, 전역 tweet collection에 등록하고, 필요에 따라 다음 query예시와 같이 팔로우중인 유저의 tweet을 불러옵니다.
1
2
3
SELECT tweets.*, users.*
FROM tweets JOIN users ON tweets.sender_id = users.id JOIN follows ON follows.followee_id = users.id
WHERE follows.follower_id = current_user
- 혹은, 각 사용자들의 Timeline의 cache를 만들고 유지하며, 이 cache에 새로운 tweet을 추가하는식으로 구현합니다.
- 이렇게하면, 각 유저의 Timeline에 대한 read요청은 이미 결과값이 계산되어(cache되어) 있기 때문에, 그 비용이 매우 저렴합니다.
’](/assets/img/for-post/DDIA-part1-chapter1/image%201.png) Tweeter Timeline 구조 from ‘Timelines at Scale’
Tweeter Timeline 구조 from ‘Timelines at Scale’ 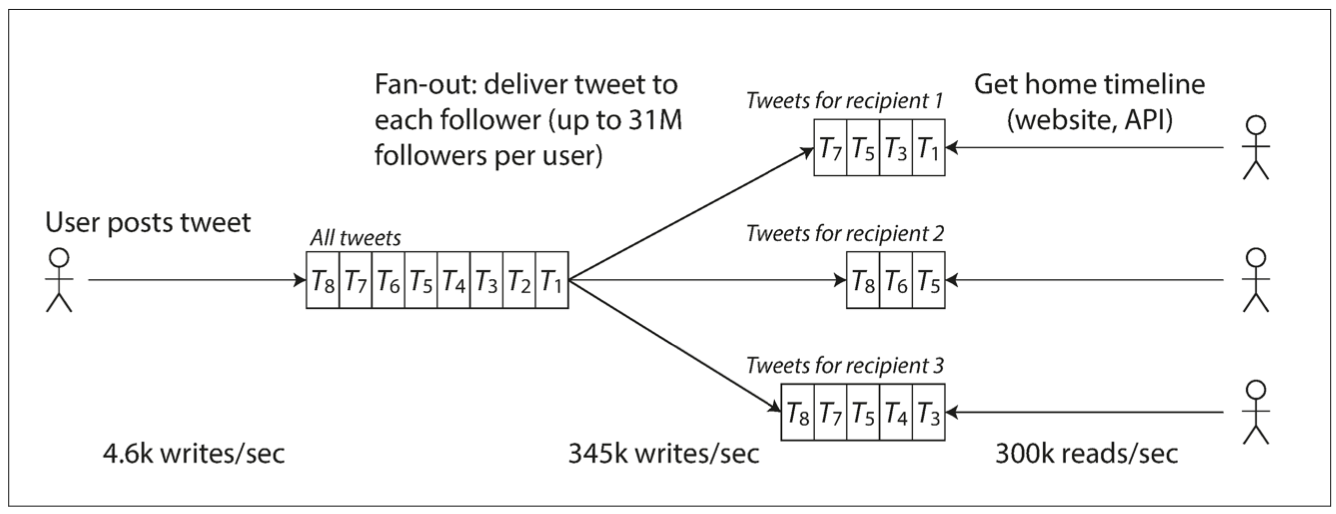 *Twitter’s data pipeline for delivering tweets to followers, with load parameters as of November 2012*
*Twitter’s data pipeline for delivering tweets to followers, with load parameters as of November 2012*
위의 접근방식중 두번째(cache를 이용한 방법)의 불리한점은 ‘트윗 작성’이 많은 부가 작업(여러 cache에 write해야하는것)을 필요로하게 된다는점 입니다. 이는 follow숫자가 많은 경우 치명적이게 되는데, 그래서 이 ‘follower 숫자’가 핵심적인 ‘Load parameter’가 됩니다.
트위터는 5초 이내에 팔로워들에게 tweet을 전송하기위해 노력한다고 합니다.
트위터에서는 최종적으로, 두번째 구현방식을 기반으로, 팔로워가 매우 많은 소수 유저의 경우 이 방식에서 제외시키고, 첫번째 접근방식과 유사하게 작동한다고 합니다.
Describing Performance(성능 기술하기)
일단 ‘System load’를 묘사하고나면, Load가 증가할 때, 어떤일이 일어나는지 다음 2가지 방법으로 살펴볼 수 있습니다.
When you increase a load parameter and keep the system resources (CPU, mem‐ ory, network bandwidth, etc.) unchanged, how is the performance of your system affected?
Load parameter가 증가했을때, scale-up(cpu, 메모리, 네트워크 대여폭을 증가)하지 않고 유지하면 시스템 성능이 어떻게 변화할까?When you increase a load parameter, how much do you need to increase the resources if you want to keep performance unchanged?
Load paramter가 증가했을때, 성능이 유지되길 원한다면, 자원을 얼마나 늘려야 할까?
이 질문들이 가능해지려면, ‘Performance number(성능 수치)’가 필요합니다.
Hadoop 같은 ‘batch processing system(일괄 처리 시스템)’은 thoughput(처리량)을 중요하게 생각하는 반면, 온라인 시스템은 ‘resposne time(응답시간)’을 중요하게 생각합니다.
‘latency(지연시간)’와 ‘response time(응답시간)’의 차이
’response time’은 Client의 관점에서 본 시간으로, 요청을 처리하는 실제 시간외에도 네트워크 지연, 큐 지연도 함하고 있습니다. 반면, ‘latency’는 요청이 처리되길 기다리는 시간입니다.
‘Response time(응답시간)’의 경우, 같은 요청이라도 매 요청마다 달라집니다. 이는 여려가지 요인이 있지만, 이 ‘Response time’을 사용할때는 그 값의 ‘distribution(분포)’로 봐야합니다.
이 ‘distribution(분포)’를 볼때, ‘arithmetic mean(산술 평균)’본다 ‘percentile(백분위)’을 사용하는게 좋습니다. ‘percentile’의 종류는 다음과 같습니다.
- p50
- 특정 범위안에서 값을 정렬하고, 50%에 위치하는 값을 가리킵니다.
- 사용자가 보통 얼마나 오래 기다리는지 확인할때 사용합니다.
- p95, p99, p999
- ‘higher percentiles(상위 백분위)’ 혹은 ‘tail latency(꼬리 지연 시간)’으로 불립니다.
- 특이값(outliers)이 얼마나 안 좋은지 볼때 사용합니다.
이러한 ‘Percentile(백분위)’은 ‘Service level objective(SLO, 서비스 수준 목표)’와 ‘Service level agreement(SLA, 서비스 수준 협약서)’에서 자주 사용합니다.
예를 들어,
the service is considered to be up if it has a median response time of less than 200 ms and a 99th percentile under 1 s (if the response time is longer, it might as well be down), and the service may be required to be up at least 99.9% of the time.
이런식으로 사용되곤 합니다.
Tail latency amplification(꼬리 지연 증폭)
end-user(최종 사용자)에게 요청 일부가 여러 백엔드 요청으로 이루어져 있다면, ‘p95, p99’와 같은 ‘higher percentiles’가 중요합니다. 각 요청을 병렬처리하고 있다고 하더라도, 모든 작업이 완료되는건 가장 느린 요청이 완료되어야 합니다. 이 때문에, 최종 ‘response time(응답 시간)’이 느려지는데, 이를 ‘tail latency amplification(꼬리 지연 증폭)’이라고 합니다.
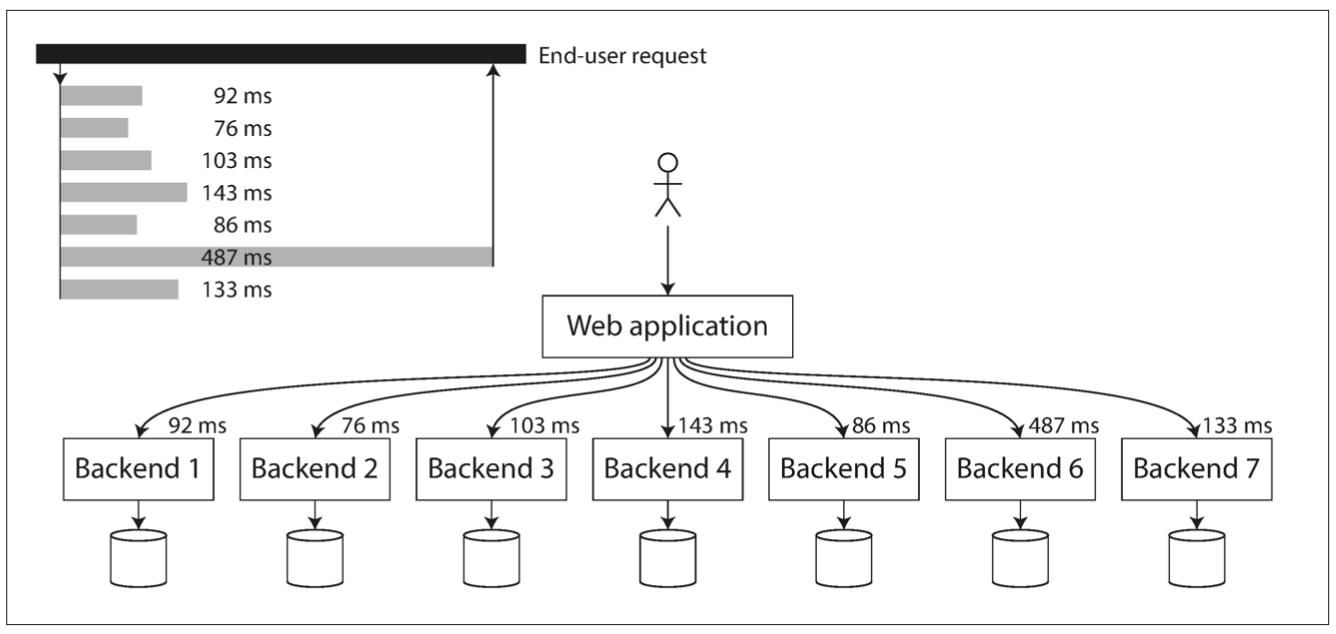
Approaches for Coping with Load(부하 대응 접근 방식)
시스템의 성능을 측정하기 위한 ‘Load(부하)’와 ‘Metric(지표)’를 정했으니, 확장성을 논의할 수 있습니다.
‘Load parameter(부하 변수)’가 어느정도 증가하더라도 성능을 좋게 유지하려면 어떻게 해야 할까요?
- Scaling up(용량 확장, 수직확장)
- 더 고사양의 장비로 이동합니다
- Scaling out(규모 확장, 수평확장)
- 다수의 낮은 사양의 장비로 확장하여 Load(부하)를 분산시킵니다. 이런 Architecture를 ‘shared-nothing’ 이라고 합니다.
Stateless(상태를 저장하지 않음, 각 장비가 독립적으로 기능을 수행) 서비스를 ‘scale out’하는건 간단하지만, ‘stateful’ 데이터 시스템을 분산 설치하는건 아주 많은 복잡도가 발생되는 일입니다.
그래서, ‘High-availability(고가용성)’에 대한 요구사항이 생기기 전까지는 단일 노드에 데이터베이스를 유지하는것이 최근까지의 통념입니다.
저자는 최근에는 분산 시스템을 위한 도구와 추상화가 좋아지면서, ‘Distributed data systems(분산 데이터 시스템)’이 기본으로 자리잡을 수 있다고 설명하고 있습니다.
모든 상황에 맞는 확장 아키텍쳐(magic scaling source라 불리는)는 없습니다.
특정 Application의 주요 동작과 잘 하는 동작이 무엇인지 대한 가정을 기반으로, 확장성을 갖춘 architecture를 설계합니다.
Maintainability(유지보수성)
소프트웨어의 비용은 대부분 초기 개발이 아니라, 이어지는 유지보수가 큰 부분을 차지한다고 합니다.
많은 엔지니어들이 소위 ‘legacy’ 시스템을 유지보수하는것을 선호하지 않습니다. 이는 유지보수 과정의 많은 ‘고통’이 동반되기 때문입니다.
다행이도, 소프트웨어 설계과정에서 이 ‘고통’을 고려하여 설계함으로서 최소화 할 수 있습니다.
- Operability(운용성)
- Make it easy for operations teams to keep the system running smoothly.
- 운영하기 쉽게 만들어라
- Simplicity(단순성)
- Make it easy for new engineers to understand the system, by removing as much complexity as possible from the system. (Note this is not the same as simplicity of the user interface.)
- 복잡도를 최대한 제거하여 새로운 엔지니어가 이해하기 쉽게 만들어라.
- Evolvability(발전성)
- Make it easy for engineers to make changes to the system in the future, adapting it for unanticipated use cases as requirements change. Also known as extensibility, modifiability, or plasticity.
- 엔지니어가 시스템을 쉽게 변경할 수 있게 해야한다.
Operability(운용성)
‘좋은 운용성’이란 동일하게 반복되는 task를 쉽게 수행하게끔 만들어, 운영팀이 고부가가치 활동에 노력을 집중하게 한다는 의미입니다. 이를 위해, 아래와 같은 일을 할 수 있습니다.
- Providing visibility into the runtime behavior and internals of the system, with good monitoring
- Providing good support for automation and integration with standard tools
- Avoiding dependency on individual machines (allowing machines to be taken down for maintenance while the system as a whole continues running uninter‐ rupted)
- Providing good documentation and an easy-to-understand operational model (“If I do X, Y will happen”)
- Providing good default behavior, but also giving administrators the freedom to override defaults when needed
- Self-healing where appropriate, but also giving administrators manual control over the system state when needed
- Exhibiting predictable behavior, minimizing surprises
Simplicity(단순성)
프로젝트가 커짐에 따라서, 시스템은 매우 복잡하고 이해하기 어려워집니다. Complexity(복잡도)는 같은 시스템에서 작업하는 사람들의 진행을 느리게하고, 유지보수 비용을 증가시키는 원인이 됩니다.
이 Complexity(복잡도)는 다양한 증상으로 나타납니다.
‘explosion of the state space’, ‘tight coupling of modules’, ‘tangled dependencies’, ‘inconsistent naming and terminology’, ‘hacks aimed at solving performance problems’, ‘special-casing to work around issues elsewhere’등이 있습니다.
때문에, Simplicity(단순성)이 시스템의 핵심 목표여야 합니다. 또한 Simplicity(단순성)이 기능을 줄인다는 의미는 아닙니다.
Moseley와 Marks는 ‘Out of the Tar pit’에서 ‘accidental complexity(우발적 복잡도)’를 설명하며, 이를 end-user에게 보이는 문제에 있는게 아니라, ‘구현’단에서만 발생하는것으로 정의하고 있습니다.
Evolvability(발전성)
시스템의 요구사항이 바뀌지 않을 가능성은 매우 적습니다.
이 책에서는 Agile기법이 적용되는 소프트웨어 보다는, 다양한 application이나 다른 특성을 가진 서비스로 구성된 ‘larger data system(대규모 데이터 시스템)’수준에서 민첩성을 높이는 방법을 찾습니다.
이를 위해선, 시스템의 ‘Simplicity(단순성)’과 ‘Abstraction(추상화)’가 매우 중요합니다.
References
- Netfilx의 Chaos Monkey와 관련된 Blog글
- The Netflix Simian Army
- Why Do Internet Services Fail, and What Can Be Done About It?
[Why Do Internet Services Fail, and What Can Be Done About It? USENIX](https://www.usenix.org/conference/usits-03/why-do-internet-services-fail-and-what-can-be-done-about-it) - Tweeter의 ‘Timelines at scale’
- Timelines at Scale