Redis | Key Technologies - System Design Interview

Redis 소개
Redis is the world’s fastest in-memory database. - from redis.io
- Redis는
- C로 작성된, 오픈소스 in-memory key-value 저장소 입니다.(데이터를 Disk가 아닌 RAM에 저장하여 사용합니다.)
- 빠른 속도와 다양한 자료구조(Data structure)를 지원하는, NoSQL DB입니다.
- String, List, Hash, Set, Sorted Set, 비트맵, HyperLogLog 등 다양한 자료구조(Data Structure)를 지원합니다.
- 빠른 속도와 다양한 자료구조(Data structure)를 지원하는, NoSQL DB입니다.
NoSQL은 기존에 많이 쓰이던, 관계형(SQL) DB가 아닌것을 의미합니다.
관계형 DB와 다르게, 더 유연한 데이터 모델과 확장성을 제공합니다.
만약 데이터 저장 과정에서, Durability(영속성)이 더 중요하다면, Redis는 적합하지 않습니다.
Redis가 AOF(Append-Only File)을 통해, Data의 Persistent를 지원하고 있지만, 이는 RDB의 것만큼 보장(guarantee)해주지 못해기 때문입니다.
단, AWS의 Memory DB와 같은 대안도 가능합니다.
Redis는 Key-Value Store입니다.
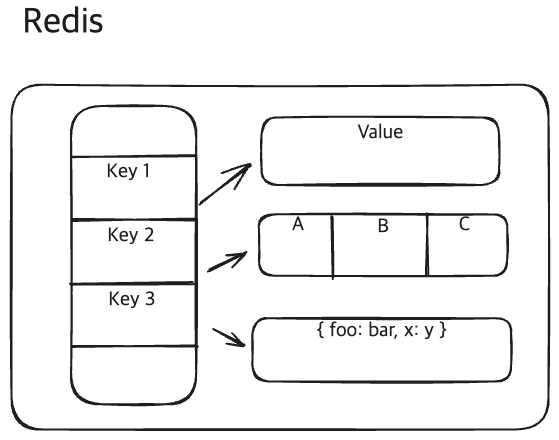
Redis는 Key-Value 저장소 입니다.
Key는 반드시 ‘String’이어야 하며, Value는 Redis가 지원하는 데이터 구조(binary data and strings, sets, lists, hashes, sorted sets 등)는 모두 가능합니다.
또한, Redis안에서의 모든 object들은 Key를 갖고 있어야 합니다.
Redis의 Value Type
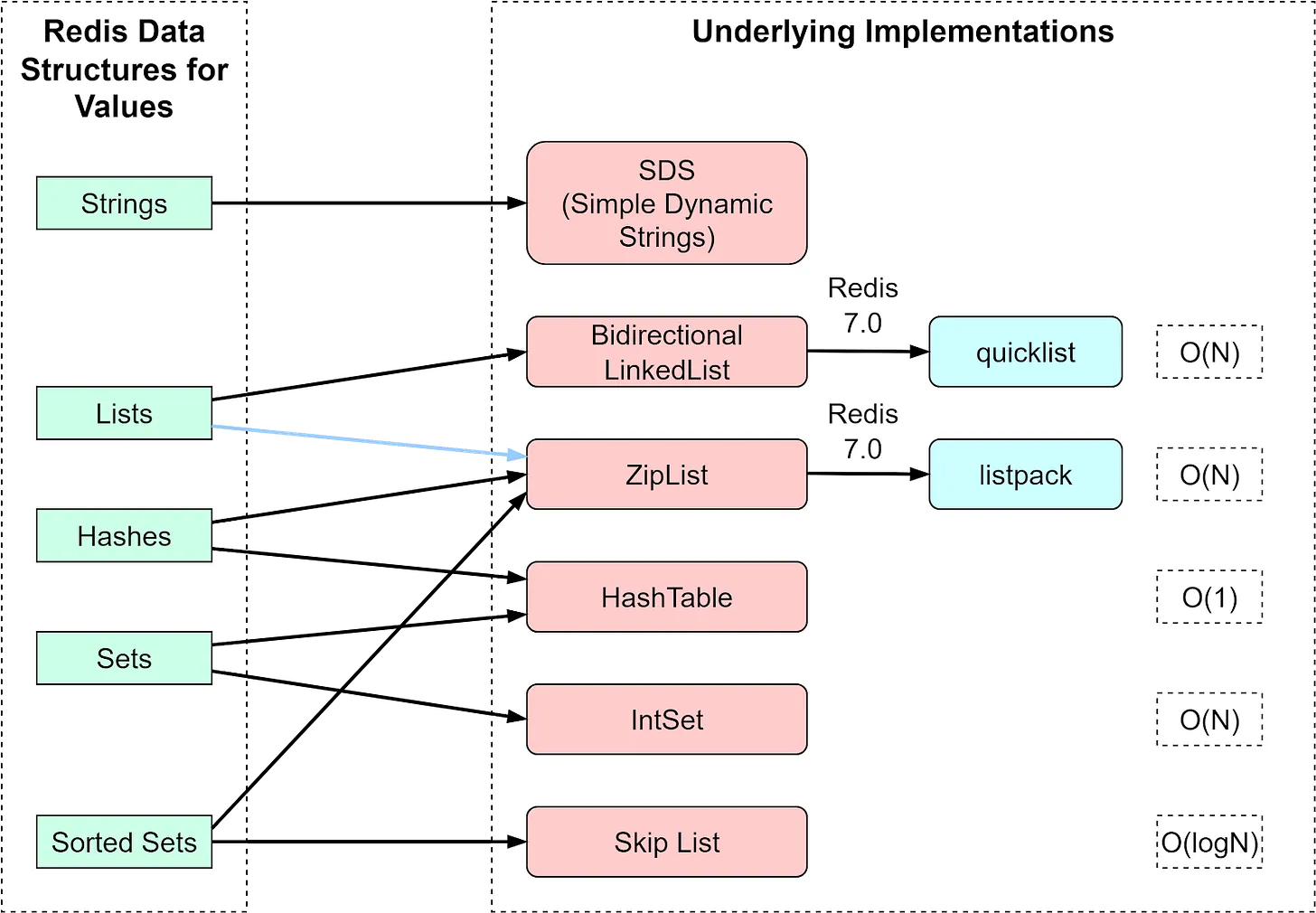 Redis의 Value Type 및 구현 Algorithm | from blog.bytebytego.com
Redis의 Value Type 및 구현 Algorithm | from blog.bytebytego.com
Redis의 Single Thread와 성능
Redis는 단일 스레드(Single Thread) 구조임에도 불구하고, 수십만 RPS(requests per second) 를 처리할 수 있을 정도로 매우 빠릅니다.
여기서는, 이것이 가능한 이유를 살펴보고자 합니다.
Redis 6부터는 I/O(read/write) 에 일부 멀티스레드가 도입되었습니다.
클라이언트 요청을 읽어오거나 응답을 보내는 작업은 멀티스레드 가능하지만, 명령(Command)실행 자체는 여전히 Single Thread로 작동합니다.
RAM 기반 처리
모든 데이터는 디스크가 아닌, RAM에 저장되어 있기 때문에, I/O 병목이 거의 없습니다.
즉, 디스크 → 메모리로 데이터를 불러오는 비용이 들지않고, 즉시 데이터를 이용한 연산이 가능합니다.
Lock 경합(Race Condition) 없음
 Lock Race Condition을 표현하는 이미지
Lock Race Condition을 표현하는 이미지
Redis는 Single Thread를 사용해서, 여러 Thread간의 동시성 문제를 위해 Lock을 사용할 필요가 없습니다.(애초에 Single Thread이기 때문에)
 CPU의 Context Switching을 비유적으로 표현하는 이미지
CPU의 Context Switching을 비유적으로 표현하는 이미지
이는 ‘Context Switching(CPU Level에서의 작업 전환)’ 비용과 ‘Lock Condition Race’(Lock을 얻기 위한 경합)을 완전히 제거해줍니다.
이를 통해, 훨씬 예측 가능하고 빠른 처리 시간을 제공합니다.
Epoll 기반 비동기 이벤트 처리
Redis는 리눅스 epoll을 사용해 수천 개의 클라이언트 연결을 하나의 이벤트 루프에서 효율적으로 처리합니다.
Linux Epoll의 역할을 보여주는 이미지 | devarea.com
- ‘epoll’은
- 수많은 파일 디스크립터(FD)(예: 클라이언트 소켓)의 입출력 가능 상태(I/O readiness) 를 효율적으로 감시합니다.
- 이벤트가 발생한 것만 알려주는 고성능 커널 기능입니다.
이벤트가 없는 Connection은 무시하고, 이벤트가 발생한 소켓만 처리하여, 매우 빠른 성능을 보여줍니다.
‘Epoll’은 시스템 콜로 호출되는 커널 기능입니다. 이 또한 Redis의 Single Thread에서 작동합니다
‘Command’가 단순하고 작다.
Redis에서 사용하는 명령어는, 대부분 매우 가볍습니다.(GET, SET, INCR 등은 O(1) 또는 O(log N) 수준의 처리 시간.)
Redis 내부 데이터 구조가 최적화되어 있어 탐색, 삽입, 정렬 등에 강력한 성능을 보여줍니다.
C언어 기반
Redis는 C언어로 개발되어 있어, 운영체제와 매우 가까운, 저수준에서 동작합니다.
즉, 별도의 VM없이 실행되어 메모리와 CPU사용을 최적화 하였습니다.
Redis의 Infra 구성 방법들
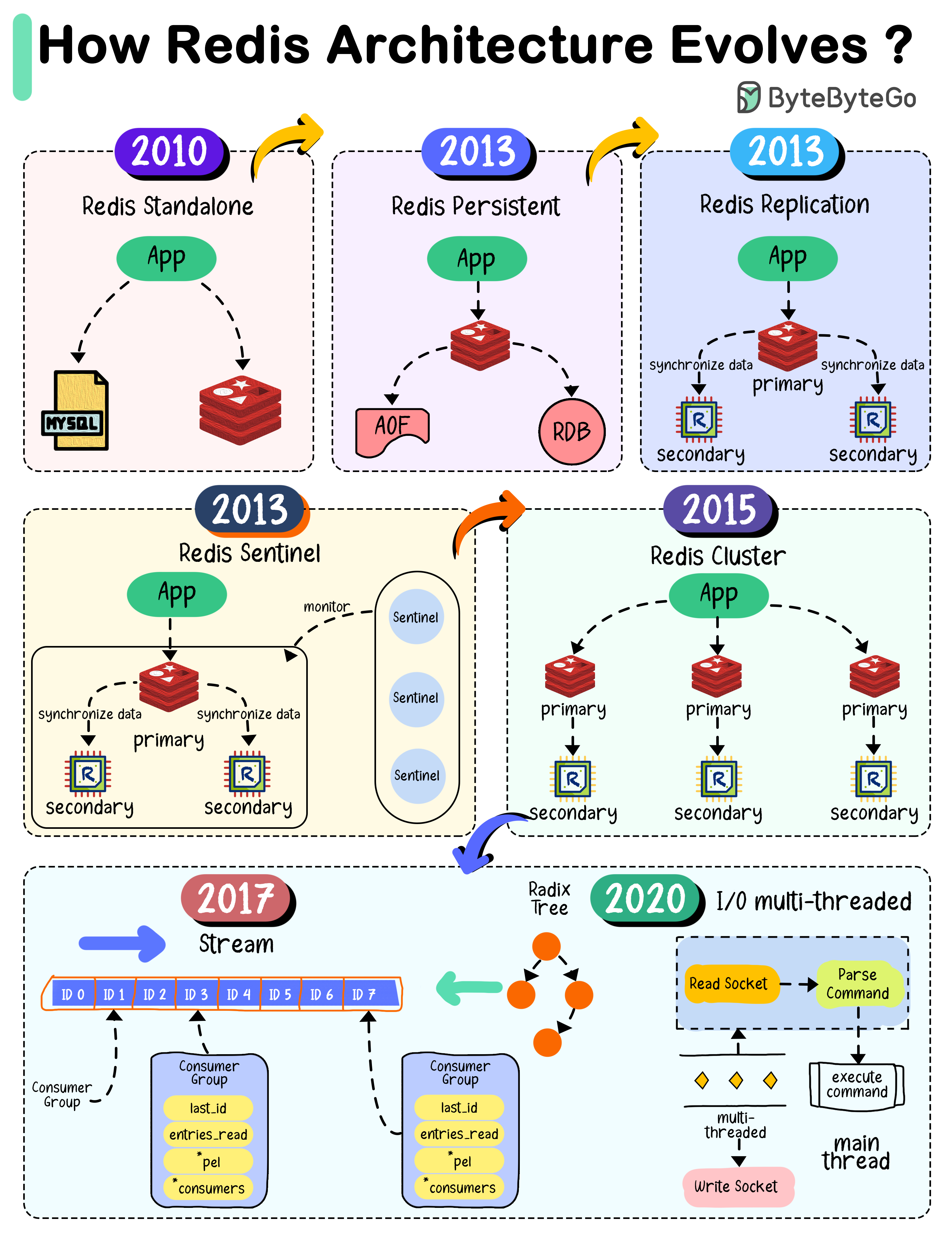 Redis의 Infra Architecture의 변화 | bytebytego.com
Redis의 Infra Architecture의 변화 | bytebytego.com
Redis는 기본적으로 Single Node로 동작할 수 있지만, HA(High Availability)를 위해 Replica나 Cluster형태로도 구성 가능합니다.
Redis Cluster
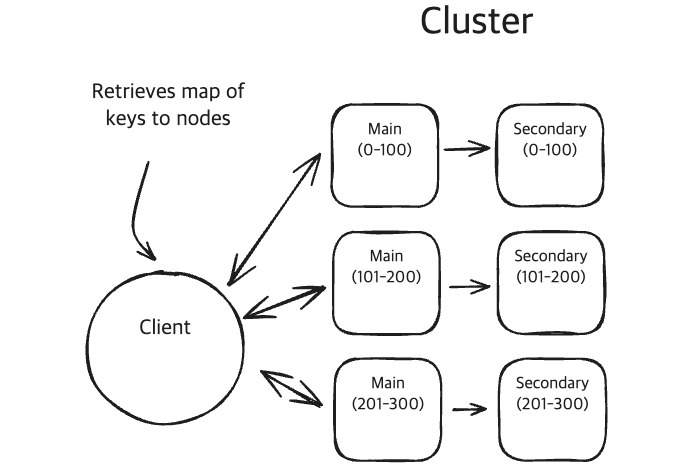 Redis Cluster와 Key분배
Redis Cluster와 Key분배
Gossip Protocol
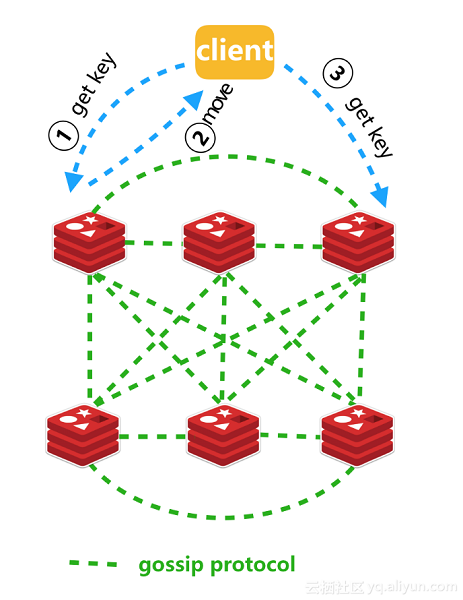 Redis Cluster와 gossip protocol
Redis Cluster와 gossip protocol
- ‘gossip protocol’은
- Redis Cluster 환경에서 노드 간 상태 정보를 전파(synchronize) 하는 데 사용되는 간단하고 효율적인 통신 프로토콜입니다.
- 클러스터의 각 노드들이 서로의 상태 정보를 주기적으로 교환하면서, 장애 감지, 노드 변경 전파, 뷰 일관성 유지 등을 가능하게 해주는 경량 분산 통신 방식입니다.
Q: 왜 ‘gossip’ protocol이라고 부르나요?
A: Node간 데이터를 주고받는 방식이, 마치 사람들이 소문을 주고받는 것처럼, 일부 정보만 여러 노드 간에 점진적으로 퍼지기 때문입니다.
ex) “노드 X가 다운된 것 같아” → Y가 듣고 Z에게 전파
Hash Slot
Redis Cluster로 구성한다면, ‘Hash Slot’이라는 개념을 사용하게 됩니다.
- ‘Hash Slot’은
- Cluster에서 데이터를 분산저장하는 Sharding의 최소 단위입니다.
- 데이터의 Key값과 Node를 맵핑(mapping)해줍니다.
- 키를 어느 노드에 저장할지를 결정하는 데 사용되는 고정된 범위(0 ~ 16383)의 해시 공간입니다.
- 만약 구성 Node의 변경이 있다면, Hash Slot단위로 Node에 재분배됩니다.(키 단위가 아닌 “슬롯 단위”로 이동되므로 성능과 일관성 측면에서 유리합니다.)
- Redis Client는 이 ‘Hash Slot’을 Caching하여, Key값에 따라 해당 Key를 갖고 있는 Node에 바로 접속합니다.
- 데이터의 Key값과 Node를 맵핑(mapping)해줍니다.
Redis가 Consistency를 보장하는 방법
Single Thread를 기반으로 명령어를 원자적으로 처리
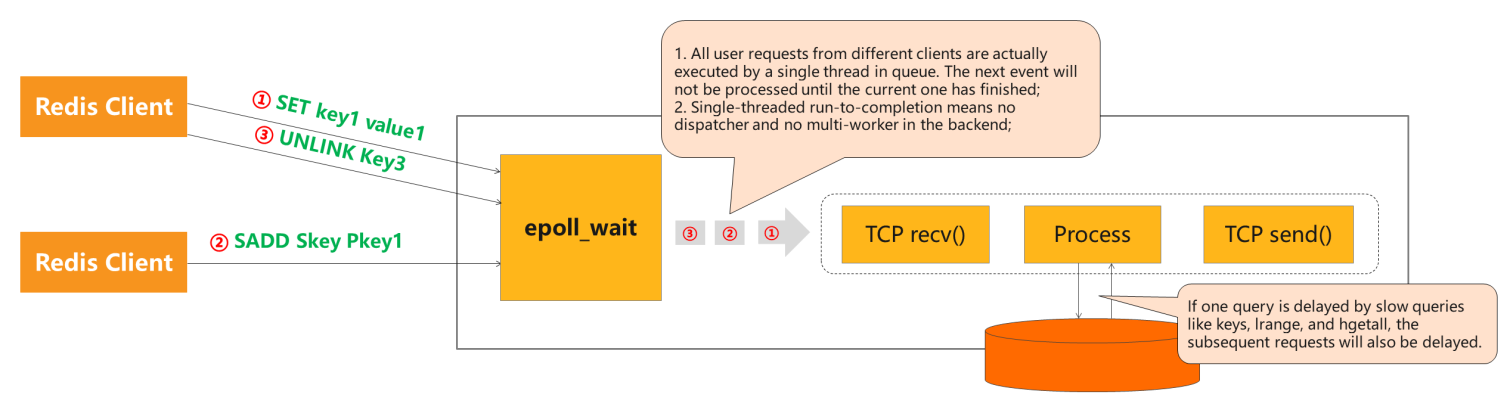 여러 Client 요청을 처리하는 단일 Redis Instance
여러 Client 요청을 처리하는 단일 Redis Instance
Redis 서버 프로세스는 단일 스레드로 동작하기 때문에, 들어오는 모든 명령이 순서대로(serialized) 처리됩니다.
덕분에 하나의 명령(command) 은 실행 중 중단되지 않으며, 원자성(Atomicity) 을 자연스럽게 보장합니다.
단, Redis 6부터, ‘클라이언트 소켓 읽기/쓰기’, ‘명령을 실행하기 전/후의 버퍼 작업’에 대해서 멀티쓰레드 I/O가 도입되었습니다.
Epoll?
epoll은 Linux 커널에서 제공하는 고성능 I/O 이벤트 통지 메커니즘입니다.
수많은 파일 디스크립터(FD)(예: 클라이언트 소켓)의 입출력 가능 상태(I/O readiness) 를 효율적으로 감시하고, 이벤트가 발생한 것만 알려주는 고성능 커널 기능입니다.
Replication에서는 Eventual Consistency사용
- 기본적으로 Redis는 Primary에서 처리된 쓰기 작업을 Replica에게 비동기적으로 전파합니다.
- 이론적으로, 마스터에 쓰기가 완료된 직후 장애가 나면 일부 업데이트가 슬레이브에 전파되지 않을 수 있어, 최종 일관성(Eventual Consistency) 을 따릅니다.
Cluster에서의 Consistency
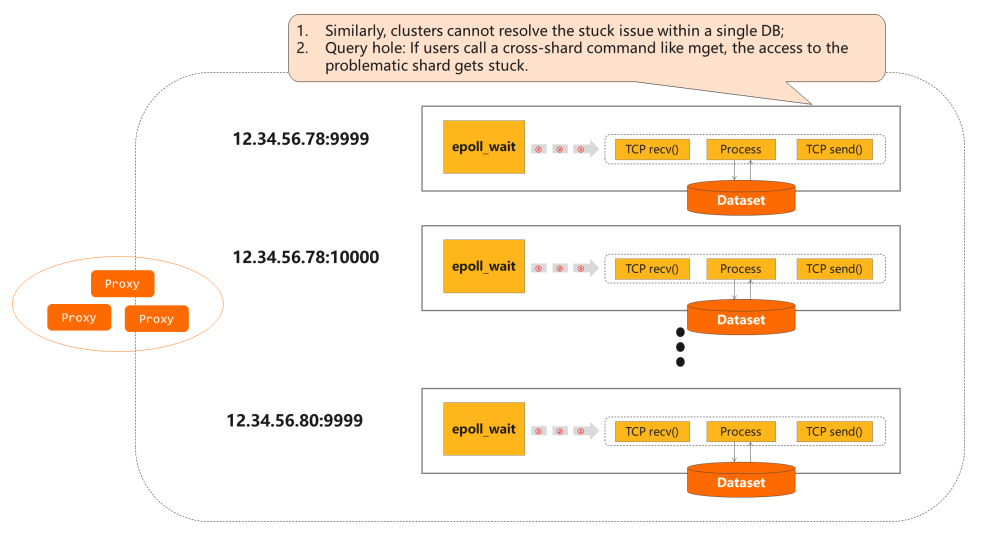 Cluster로 구성된 Redis
Cluster로 구성된 Redis
- Redis Cluster는 데이터를 16,384개의 해시 슬롯(hash slot) 으로 분산 저장합니다.(Sharding)(Cluster가 하나의 instance처럼 작동)
- 샤드 간 트랜잭션을 지원하지 않으며, 하나의 키에 대한 연산은 항상 그 키를 소유한 노드(master)에서 처리됩니다.
- 클러스터 구성원 간 복제는 마스터–슬레이브 모델을 따르므로, 기본적으로 비동기 복제에 따른 최종 일관성을 제공합니다.
Redis의 Persistence
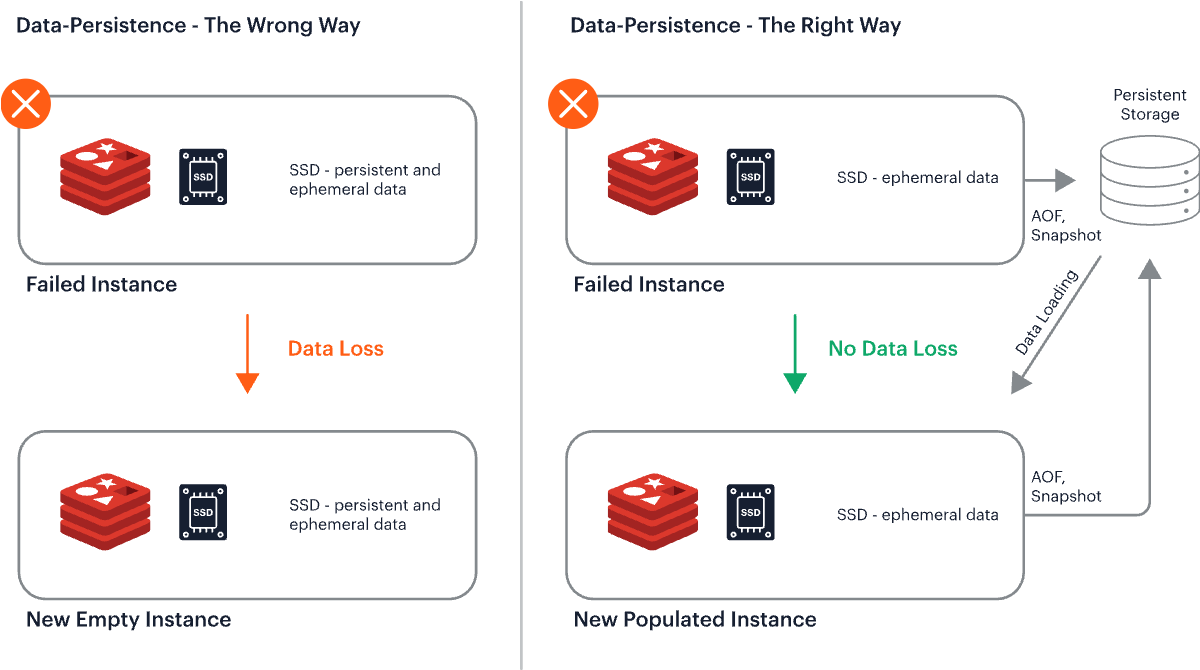 Redis에서, ‘Persistence를 위한 기능들’의 작동 방식 | from redis.io
Redis에서, ‘Persistence를 위한 기능들’의 작동 방식 | from redis.io
Redis can persist your data either by periodically dumping the dataset to disk or by appending each command to a disk-based log.
- from redis.io
- Redis에서는 Data를 보존하기 위해,
- 정기적으로 Disk에 데이터를 쓰거나(periodically dumping the dataset to disk)
- 각각의 Command를 Disk기반의 Log에 기록하는(appending each command to a disk-based log)
방법을 사용합니다.
정기적으로 Disk에 데이터를 쓰기(rdb파일로 쓰기)
지정된 시점(snapshot)의 메모리 데이터를 통째로 덤프해서 .rdb 파일로 저장하는 방식을 말합니다.
각각의 Command를 Disk기반의 Log에 기록하기(AOF)
Redis에서 실행된 모든 쓰기 명령을 순차적으로 로그 파일에 기록하는 방식입니다.
AOF 파일은 계속 커지므로, 주기적으로 압축 및 재작성이 필요합니다.
Redis는 자동으로 ‘BGREWRITEAOF(AOF최적화 명려어)’를 수행해 오래된 명령을 요약합니다.
rdb와 AOF조합 방법
- RDB만 사용: 단순하고 빠른 복구가 필요한 경우에 사용합니다.
- AOF만 사용: 안정성이 중요한 경우에 사용합니다.
- RDB + AOF 함께 사용
대부분의 실무 환경에서 추천됩니다.
이 경우, 복구 시 AOF가 더 최신이면 AOF 우선으로 사용합니다.(AOF를 더 신뢰)
Redis와 Memcached
Redis와 Memcached는 모두 인메모리 기반의 캐시 시스템이지만, 목적과 기능 측면에서 다음과 같은 차이점이 있습니다.
데이터 구조
- Redis는 리스트, 해시, 셋, 정렬셋 등 다양한 구조를 제공 → 큐, 랭킹, 통계에 유용합니다.
- Memcached는 단순한 문자열 key-value 구조 → 복잡한 로직은 애플리케이션에서 직접 구현해야 합니다.
Persistence (데이터 보존)
- Redis는 RDB(rdb파일로 저장)/AOF(Append-Only File) 방식으로 디스크에 데이터를 저장 가능하며, 이를 통해 장애 후 복구가 가능합니다.
- Memcached는 서버 재시작 시 모든 데이터가 사라집니다.
분산성과 고가용성
- Redis는 Sentinel, Cluster 등을 통해 자동 failover 와 수평 확장이 가능합니다.
- Memcached는 클라이언트 단에서 key hashing을 통해 수동 샤딩(consistent hashing)을 구현해야 합니다.
Pub/Sub 기능
- Redis는 채널 기반 메시지 전달 기능(Pub/Sub)을 제공하여 실시간 이벤트 알림 등에 사용 가능합니다.
- Memcached는 이런 기능 없이, 단순 Cache용도로 사용합니다.
요약
- ‘Memcached’는
- 가볍고 빠른, 단순 캐시용으로 사용하고,
- ‘Redis’는
- 다기능 인메모리 데이터 플랫폼으로 사용합니다.
Redis 사용 방법들
Redis as a Cache
 Redis를 Cache로 사용할때의 Flow
Redis를 Cache로 사용할때의 Flow
Redis를 Cache로 사용하는것은 가장 흔하게 사용되는 사례중 하나입니다.
- Redis를 Cache로 사용할때는,
- 각 key에 대해 TTL(Time-to-live)를 설정합니다.(이는 Redis가 데이터를 관리하는 방법을 가이드 해주는 역할을 합니다.)
Cache용도로 Redis를 사용하다 보면, ‘Hot key’문제에 부딪히게 되는데, 이는 뒤에서 다루려고 합니다.
Redis as a Distributed Lock
‘Distributed Lock’으로 Redis를 사용하는것 또한 가장 흔한 사례중 하나입니다.
만약 System에서, ‘Ticket 구매’와 같이 ‘Strong Consistency’가 필요한 경우, Redis를 사용하여 Lock을 구현할 수 있습니다.
만약, 사용하고 있는 DB레벨에서 이미 Consistency를 제공하고 있다면, 해당 기능을 쓰는게 좋습니다. Redis를 통해 Lock을 구현하면, 불필요하게 복잡도를 높이게 됩니다.
Redis를 이용하여 ‘Distributed Lock(분산 Lock)’을 구현하는 알고리즘 및 프로토콜로 ‘Redlock’이 있습니다.
Redis for LeaderBoards
Redis의 ‘sorted set’데이터 타입은 정렬된 데이터를 제공해주며, $log(N)$시간의 Query응답을 제공해줍니다.
이는 LeaderBoard App에 적합한 스펙입니다.
만약 LeaderBoard와 같이, Write throughput은 높고, Read Latency는 낮아야 하는 경우를 SQL DB로 대응하려고 하면, 꽤나 힘들겁니다.
Redis for Rate Limiting
Rate Limiting은 특정 클라이언트가 지나치게 많은 요청을 보내지 못하도록 제한하는 기법입니다.
- Redis는
- 고속의 in-memory 연산 + TTL 기능 + 원자적 연산을 제공하기 때문에, ‘Rate Limiting’용으로 사용할 수 있습니다.
- 카운터 기반, 토큰 버킷, 슬라이딩 윈도우 등 다양한 알고리즘으로 지원할 수 있습니다.
How to build a Rate Limiter using Redis
Redis for Proximity Search(근접 검색, 예: 위치 기반 검색 또는 유사 단어 검색)
Redis는 기본적으로 전통적인 RDBMS의 공간 인덱스(GIS) 나 벡터 검색 엔진은 아니지만, 몇 가지 기능을 조합하여 근접 검색을 구현할 수 있습니다.
Getting Started With Geo Location Search in Redis
‘Proximity Search에는 2가지 맥락이 있는데, ‘지리적 근접 검색’과 ‘유사 문자열 검색’이 그것입니다.
Redis GEO 기능으로 위치 기반 Proximity Search
Redis는 GEOADD, GEORADIUS, GEODIST, GEOPOS 등의 명령어로 지리 정보(위도, 경도)를 저장하고 검색할 수 있습니다.
내부적으로는 Geohash + Sorted Set으로 구현되어 있습니다.
문자열 유사성 기반 Proximity Search
Redis 자체적으로 지원하지는 않고, RediSearch 모듈을 통해 구현할 수 있습니다.
‘RediSearch’는 텍스트 인덱싱, 검색, 유사 단어 매칭, 벡터 검색 (ANN) 까지도 지원합니다.
Redis for Event Sourcing
Redis 5.0부터 추가된 데이터 구조인 ‘Stream’을 통해, ‘Event Sourcing’패턴을 구현할 수 있습니다.
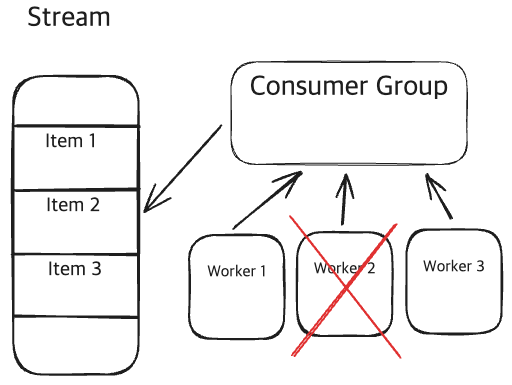 Redis streams and consumer groups | hellointerview.com
Redis streams and consumer groups | hellointerview.com
- ‘Event Sourcing’은
- 상태를 저장하는 대신, 모든 변경 이벤트의 로그(event stream)를 기록해서, 나중에 그 이벤트들을 재생(replay)하여 현재 상태를 만들어내는 아키텍처 패턴입니다.
- ‘Redis Stream’은
- ‘Append-only Log’처럼 작동하는 자료구조입니다.
- 시간 순서대로, Log형식으로 데이터를 저장합니다.
- 내부적으로는 Kafka의 topic-like 구조와 매우 유사하며, ID 순 정렬, 범위 조회, consumer group 처리 등이 가능합니다.
- 시간 순서대로, Log형식으로 데이터를 저장합니다.
때문에 ‘Stream’을 통해 ‘Event Sourcing’을 구현할 수 있으며, 메모리 기반이라 매우 빠른 성능을 제공해줍니다.(Redis 특성에서 오는 데이터 유실 가능성이 있음.)
Redis for Pub/Sub
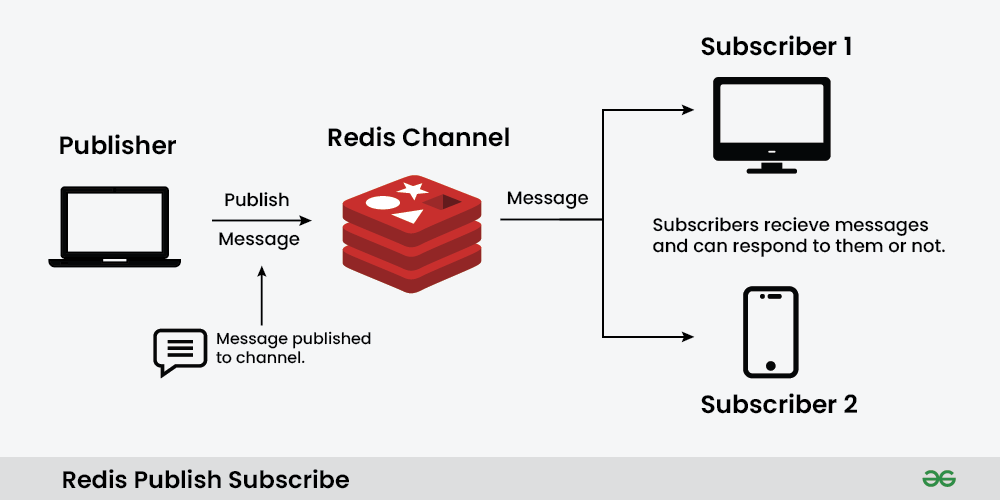 Redis Pub/Sub | from geeksforgeeks.org
Redis Pub/Sub | from geeksforgeeks.org
Redis는 자체적으로 ‘publish/subscribe(Pub/Sub)’ Messaging pattern을 지원하며, 메시지 브로커처럼 채널 기반으로 메시지를 전달하는 기능입니다.
이는 주로 Chat System이나 실시간 Notification 혹은 ‘Message생산자와 소비자를 decouple하는 시나리오’에서 사용됩니다.
Redis는, Pub/Sub에 대해서도 sharding을 지원합니다. (Redis 구버전에서는 불가)
장점
- 메모리 기반이라 초 저지연 메세징 기능을 제공합니다.
- 간단한 설정으로 바로 사용할 수 있습니다.
- Pub/Sub Client는 Redis Cluster를 구성하는 각 Node마다 하나의 Connection을 사용합니다.
Pub/Sub Channel마다 하나씩 쓰는게 아니라서, 커넥션 사용을 최소화할 수 있습니다.
단점
메세지 영속성(Persistence)이 없습니다.
Subscriber가 연결되어 있지 않으면, 메시지는 버려집니다.큐(queue) 가 아닌, 모든 구독자에게 동시에 전달하는 ‘Broadcast’구조입니다.
Redis의 단점과 개선방법
Hot Key Issues
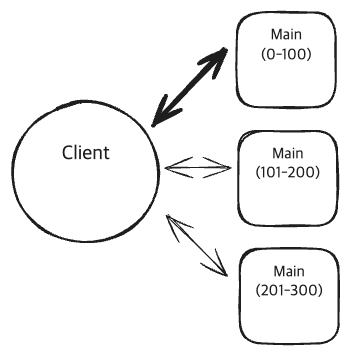 Redis Cluster에서 0-100범위에 대해 Hot Key Issue가 발생 | from hellointerview.com
Redis Cluster에서 0-100범위에 대해 Hot Key Issue가 발생 | from hellointerview.com
- ‘Hot Key Issues’는
- 특정 키(key)에 과도하게 많은 요청이 집중되어 시스템의 성능 저하 또는 병목이 발생하는 문제를 말합니다.
- Redis의 특정 key에 트래픽이 몰리면서 해당 key와 연관된 노드나 자원이 비정상적으로 과부하 되는 문제입니다.
Redis는 기본적으로 단일 스레드 기반이기 때문에, 하나의 key에 너무 많은 명령이 몰리면 그 key를 포함한 처리 루프 전체가 지연될 수 있습니다.
만약 Cluster환경이라면, 해당 key가 할당된 해시 슬롯(slots)이 포함된 특정 노드에만 부하가 집중될 수 있으며, 이는 노드간 불균형(CPU, 메모리, 네트워크 I/O에 대한)을 초래합니다.
해결 방법
- Client level에서 In-memory Cache를 추가하여, Redis에 너무 많은 요청이 발생하지 않도록 합니다.
- Redis에서 사용하는 Key에 Random number를 추가하여, 여러 Node에 걸쳐서 데이터가 분산되도록 합니다. (Key Sharding)
예: “rank:global” → “rank:global:shard1”, “rank:global:shard2”
Big Key Issues
- Big Key Issue란,
- Redis의 단일 key가 너무 많은 요소(예: 리스트, 해시, 셋 등)를 가지고 있어서, 해당 key에 대한 연산이 느려지거나 전체 Redis 인스턴스에 영향을 주는 문제입니다.
- key 자체가 크다는 의미가 아니라, 하나의 key에 저장된 데이터가 지나치게 많은 경우를 말합니다.
‘Big Key’에 대한 정의 및 평가 기준은 실제 사용 및 애플리케이션의 특정 요구 사항에 따라 달라질 수 있습니다.
예를 들어, 높은 동시성 및 낮은 지연 시간 시나리오에서는 10KB의 키만 빅 키로 간주될 수 있습니다. 그러나 낮은 동시성 및 고용량 환경에서는 빅 키의 임계값이 약 100KB일 수 있습니다
해결 방법
Key를 나눕니다.(Sharding / Chunking)
큰 리스트를 “chat:room:123:page:1”, “chat:room:123:page:2” 처럼 분할합니다.- Key에 대한 전체 연산은 피합니다.
- 문자열 data인 경우, 압축을 고려합니다.
References
- Redis | hellointerview.com
- Hello Interview | System Design in a Hurry
- Redis About | redis.io
- About - Redis
- Redis Distributed Caching | redis.io
- Distributed Caching
- Redis Cluster Architecture | redis.io
- Redis Cluster Architecture | Redis Enterprise
- Three Ways to Maintain Cache Consistency | redis.io
- Three Ways to Maintain Cache Consistency | Redis
- Redis Race Condition | redis.io
- Redis Race Condition
- High-Concurrency Practices of Redis: Snap-Up System | alibabacloud.com
- High-Concurrency Practices of Redis: Snap-Up System
- Understanding the Failover Mechanism of Redis Cluster | alibabacloud.com
- Understanding the Failover Mechanism of Redis Cluster
- Snapshotting | redis.io
- Redis persistence
- Append-only file | redis.io
- Redis persistence
- Redis Architecture의 진화 | bytebytego.com
- ByteByteGo | How Redis Architecture Evolved
- What makes Redis lightning fast ? | engineeringatscale.substack.com
- What makes Redis lightning fast ?
- Linux – IO Multiplexing – Select vs Poll vs Epoll | devarea.com
- Linux – IO Multiplexing – Select vs Poll vs Epoll
- BGREWRITEAOF | redis.io
- BGREWRITEAOF
- Distributed Locks with Redis | redis.io
- Distributed Locks with Redis
- How to build a Rate Limiter using Redis | redis.io
- How to build a Rate Limiter using Redis
- Getting Started With Geo Location Search in Redis | redis.io
- Getting Started With Geo Location Search in Redis
- How to Use Redis as an Event Store for Communication Between Microservices | redis.io
- How to Use Redis as an Event Store for Communication Between Microservices | Redis