NIPA ML 프로젝트 ‘Synchro-you’ 공유
들어가기전에..
2024 Google MLB가 끝나고, NIPA와 Google MLB와 연계된 실무 프로젝트(이하 NIPA)를 이어가게 되었습니다.
NIPA에서 6명이 팀을 이루어 ML을 이용한 ‘Synchro-you’라는 제품을 만들었습니다.
Synchro-you 프로젝트 소개
최근 유행하고 있는 각종 챌린지 영상에서 영감을 받아, ‘내가 얼마나 잘 따라하는지’를 확인하는 서비스를 만들게 됐습니다.

AI를 활용한 실시간 댄스 점수 확인 서비스
(How Accurate is My Dance Sync?)
- AI가 동장을 정밀하게 인식하고,
- 기준이 되는 동작과의 유사도를 점수로 제공합니다.
- 즉각적인 피드백을 받음으로서, 사용자들은 자신의 퍼포먼스를 개선할 수 있습니다.
- Game처럼 플레이할 수 있습니다.
예상하는 문제들..
촬영 각도에 따라 좌표 차이가 발생할 수 있는 문제.
3차원 공간에서 동작이 일치해도, 2차원인 영상으로 변환되기 때문에, 촬영 각도에 따라 좌표 차이가 발생할 수 있습니다.같은 길이(time기준)의 영상이여도, fps(Frame per seconds)의 차이로 총 데이터의 길이가 다를 수 있다.
즉, 단순히 두 영상의 frame과 frame을 비교한다는 생각으로 접근할 순 없다.
구현 전략
Rule-based 방법과 Deep Learning을 이용한 방법 비교
저희는 ‘동작이 일치한다’는 개념에 대해서 고민하기 시작했습니다.
동작을 어떻게 수치화(feature로 만들것인지) 고민하기 시작했습니다.
그래서 결론 지은것이, 동작(movement)의 맥락(Context)이 필요하다는 것이었습니다
Rule-based를 이용한 방법
‘Rule-based’는 특정 규칙을 정의하여 비교하는 방법입니다. 우리 제품같은 경우, ‘frame별로 특정 포인트가 일치하면 일치 하는지’ 정도로 표현할 수 있습니다.
이 방법을 사용하면, 움직임의 frame을 일치시켜야 하는 문제가 있습니다.
 frame과 frame을 비교하는 예시
frame과 frame을 비교하는 예시
- from https://en.wikipedia.org/wiki/Dynamic_time_warping
Deep Learning을 이용한 방법(채택된 방법)
DTW라는, 시계열(time series)기반의 2개의 연속된 데이터(sequence)간 유사도(similarity)를 측정할 수 있는 알고리즘이 있다고 합니다.
여기서 영감을 받아, 영상속 사용자의 pose를 인식하여, 주요 관절의 각도(angle)을 비교하는 방향으로 구현하게 되었습니다.
- 이렇게 하면,
- 카메라 촬영 각도에 따른 문제(불일치 문제)를 해결할 수 있습니다.
- 학습이나 추론에 사용하는 데이터량을 줄일 수 있습니다.

데이터 선정

AI hub의 ‘K-pop 안무영상’을 활용하였습니다.
이 데이터셋은 한가지 춤에 대해서 여러 각도로 찍은 영상을 포함하고 있습니다. 이를 이용해, Positive인 경우와 Negative경우의 학습 데이터를 쉽게 구성할 수 있습니다.
데이터셋 안에 이미 관절 좌표가 있지만, 저희가 쓸 라이브러리 데이터에서 추출한게 아니기 때문에, 데이터 일관성을 위해 사용하지 않았습니다.
데이터 전처리
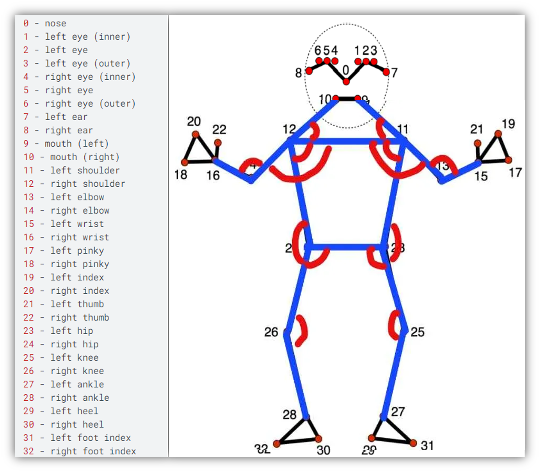 mediapipe의 pose landmark정보와 사용한 각도(angle)
mediapipe의 pose landmark정보와 사용한 각도(angle)
- Landmark feature
- 영상 데이터 → Media pipe (라이브러리) 적용 → 프레임 별 Landmark 추출 → 스켈레톤 벡터 계산 → 신체 부위 각도 계산
- Feature selection
- 33개의 landmark를 각도(angle)로 바꾸어, 최종 Input값은 신체각도 12개가 되었습니다.(위 이미지에서 빨간색으로 표시된 부분)
- Sequential data
- 특정 frame 단위(여기선 30)로 각도값들을 결합시켜서(concat), sequential데이터로 만들어 inference를 실행하게 됩니다.
모델 학습 방법, Supervised Contrastive Learning
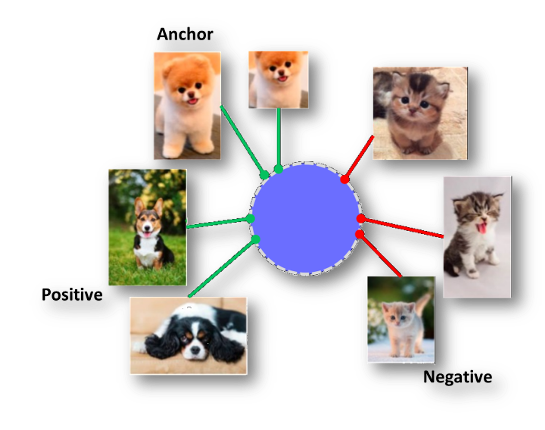
Anchor를 기준으로, Positive Pair와 Negative Pair을 지정하여 학습시킵니다.
Positive Pair: 같은 춤 내의 서로 다른 방향에서 촬영된 두 영상
Negative Pair: 서로 다른 춤을 춘 두 영상
모델 구조
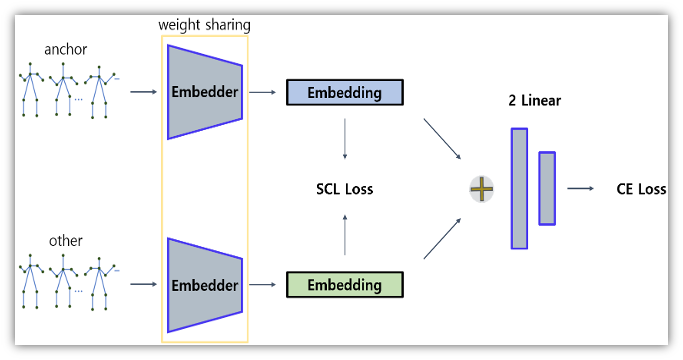 ※Embedder: LSTM + Layer Normalization.
※Embedder: LSTM + Layer Normalization.
‘Synchro-you’ model architecture
- input된 데이터를 일관성을 유지하기 위해, 같은 가중치를 사용하여 ‘Embedding vector’를 계산 합니다.
- 2개의 ‘Embedding vector’간 ‘Supervised Constrastive Learning Loss(SCL loss)’를 계산합니다.
- $\frac{\text{positive}}{\text{positive} + \text{negative}}$으로 모델을 평가하게 만들어, Postive간의 유사도는 높이고(↑), negative의 유사도는 낮추도록(↓) 하였습니다.
- Binary classification을 통해, positive(1)과 negative(0)사이의 값이 만들어지도록 합니다.
모델 배포 전략
소규모 프로젝트 팀이기 때문에, 자동화된 배포전략을 구축하긴 어려웠습니다.
- TorchScript사용
- 모델 빌드팀과 서비스 빌드팀을 decouple하기 위해서, Pytorch 프레임쿼크의 TorchScript를 사용하였습니다.
- 모델 학습(Learning)환경에서 학습이 완료되면, 해당 모델의 가중치(weight)와 모델 구조를 TorchScript로 변환하여 저장하였습니다.
- 추후, 서비스 빌드팀에서 TorchScript를 받아, 다양한 환경에서 API서버를 빌드할 수 있게되었습니다.
- 모델 학습(Learning)환경에서 학습이 완료되면, 해당 모델의 가중치(weight)와 모델 구조를 TorchScript로 변환하여 저장하였습니다.
개인정보 보호 전략
사용자가 자신이 찍힌 모습을 Server로 전송하는건 좀 더 민감한 문제가 됩니다.
때문에, 영상을 서버로 전송하지 않고, Web App(Client)에서 영상의 Pose 및 각 관절 좌표를 인식하여 서버로 보냅니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
curl --location 'http://localhost:4000/predict' \
--header 'Content-Type: application/json' \
--data '{
"seq": 0,
"user_pose_data": [[
0.503532886505127,
0.25677618384361267,
-0.2561524510383606,
0.5126909613609314,
0.245061457157135,
-0.2039661705493927,
...
0.4993351995944977,
0.8586224317550659,
-0.2884582281112671
]
]
}'
Service Architecture

Client
nextjs와 reactjs를 이용해서 static으로 bulid하여 배포하였습니다.
mediapipe를 통해 Client에서 영상의 좌표를 뽑아 서버에게 inference를 요청합니다.
mediapipe가 WASM(WebAssembly, 웹 어셈블리)를 지원하여, Web app에서도 손쉽게 사용할 수 있습니다.
Server
FastAPI와 pytorch를 이용해서 inference를 간단하게 구성하였습니다.
Infra
AWS의 ECS환경에서 CPU inference를 수행합니다.
시연
몇개의 챌린지를 예시로, Positive인 경우와 Negative인 경우의 점수 차이를 비교해 보았습니다.
‘삐끼삐기 챌린지’
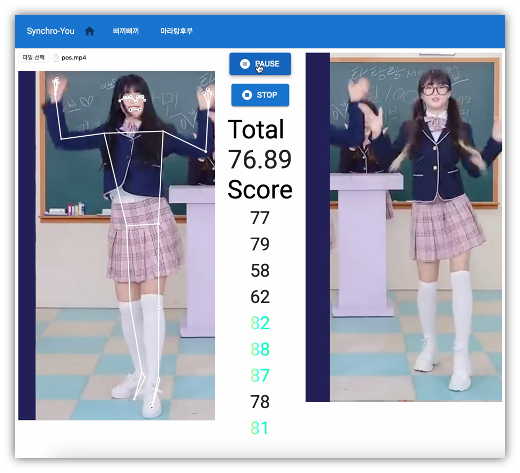
긍정(Positive) 사례
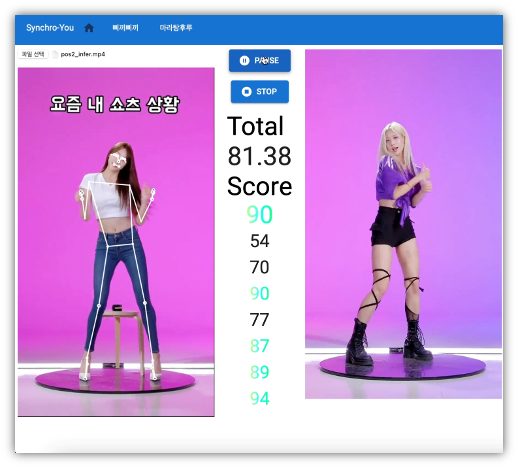 삐끼삐기 Positive 사례
삐끼삐기 Positive 사례
부정(Negative) 사례
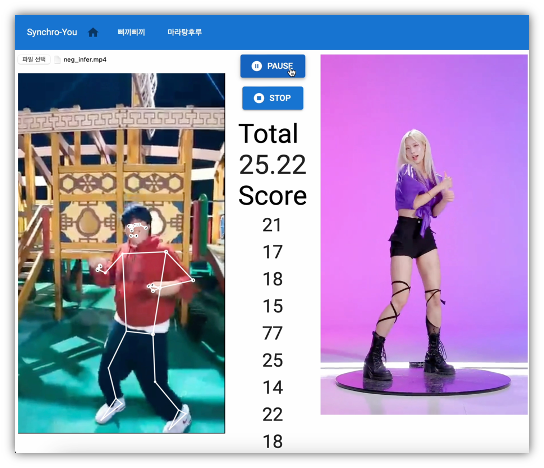 삐끼삐기 Negative 사례
삐끼삐기 Negative 사례
‘마라탕후루 챌린지’
긍정(Positive) 사례
 마라탕후루 Positive 사례
마라탕후루 Positive 사례
부정(Negative) 사례
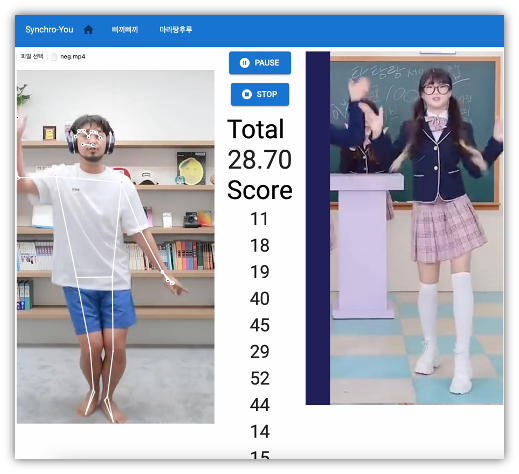 마라탕후루 Negative 사례
마라탕후루 Negative 사례
영상(Demonstration)
회고
팀장으로 역할하면서 여러 사람들과 ML제품을 zero-base에서 만들어간 것은 처음이었습니다.
모두 진지하게 임해주셔서, 참 보람찬 프로젝트였습니다.
남은 과제
gRPC를 이용한 real-time inference 제공
처음 설계시에는 real-time inference를 위한 환경까지 구축하는것이었지만, 프로젝트 시간 관계상, 그리고 이미 서버의 inference time이 500ms로 준수한 성능을 내주어서, 나중으로 미루었습니다.영상 시작점이 제각각인 경우에 대한 대응 미비
같은 챌린지 영상이어도, 움직임이 시작되는 시점이 달라 정확한 inference가 이루어지지 않는 문제가 남아있습니다.Client의 버벅임 문제
Client에서 inference가 WASM이라 병렬로 이루어지긴 하지만, 해당 결과를 영상에 좌표를 매 frame마다 그리는게 원인으로 보이며, web worker를 통해 해결할 수 있지 않을까… 싶습니다.
References
- DTW(Dynamic time warping)
- Dynamic time warping
- TorchScript
- TorchScript — PyTorch 2.5 documentation