Merge sort implementation with rust(rust로 병합정렬 구현)
‘merge sort’는 ‘Divide and conquer(분할과 정복)’을 사용한 대표적인 알고리즘입니다. 이 ‘Divide and conquer’는 문제를 작게 쪼개서 해결하고, 이를 다시 합침으로서 문제를 해결해 나가는걸 말합니다.
‘Divide and conquer’는 여러 문제해결의 기본이 되곤 하며, 앞으로 부딪히는 문제가 너무 크게 느껴진다면, 이 전략으로 접근하면 도움이 됩니다.
‘merge sort’에서는 총 2단계로 알고리즘의 단계를 구분합니다.
- 분할(divide) 단계
- array를 반으로 나눕니다.
- 정복(conquer) 단계(merge 단계)
- 나뉘어진 2개의 array를 하나로 합칩니다. 이때, 정렬이 이루어집니다.(2개의 array를 각각 보면서 크기를 비교하여 합칩니다)
Time complexity and space complexity
Time complexity(시간복잡도)
| Best case | Average | Worst case |
|---|---|---|
| $O(n\log{n})$ | $O(n\log{n})$ | $O(n\log{n})$ |
어떤 상황이든 $O(n\log{n})$으로 안정적인 성능을 보여줍니다.
여기서 n은 정렬 대상이 되는 array 전체를 1회 탐색해야하는것을 의미합니다.
알고리즘의 단계로 보면,
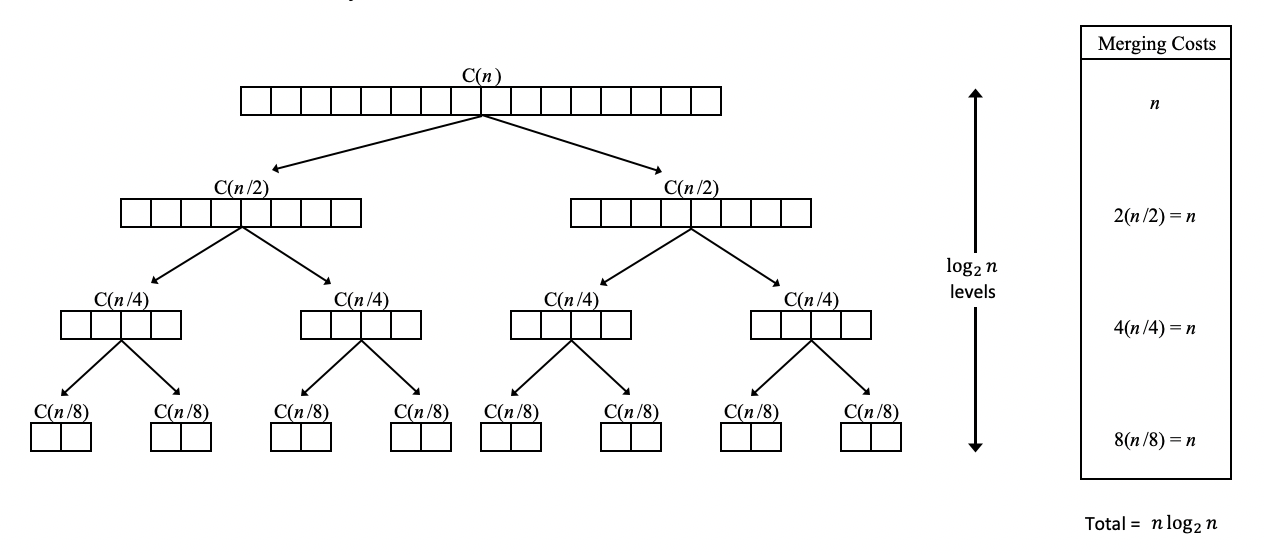 Merge sort analysis with Tree. 출처: https://mathcenter.oxford.emory.edu/site/cs171/mergeSortAnalysis/
Merge sort analysis with Tree. 출처: https://mathcenter.oxford.emory.edu/site/cs171/mergeSortAnalysis/
- 분할(divide) 단계
- $O(\log{n})$, array를 반으로 줄여나가면서 함수의 실행횟수가 $O(\log{n})$이 됩니다. 위 tree 이미지에서 tree depth가 이에 해당합니다.
- 정복(conquer) 단계
- $O(n)$, 이 과정에서 정렬이 이루어지므로, 대상이 되는 array의 요소들을 1회씩 읽어야 합니다
왜 $O(2^{n})$이 아닐까?
이전 post에서는 recursive 호출에 대해 시간복잡도가 $O(2^{n})$이라고 했습니다.
‘Merge sort’에서 ‘recursion’을 사용함에도, 이번에는 왜 $O(n\log{n})$일까?
- Array를 divide(분할)하는 작업의 비용이 매우 낮습니다.
- ‘Recursive Algorithm’에서의 ‘Time Complexity(시간복잡도)’는 각 function들(tree의 node에 해당함)의 실행시간을 고려한 결과입니다.
- 하지만, ‘Merge sort’에선, 각 function에서 실행하는 분할(divide)과 합치는(merge)작업의 비용이 매우 적다고 여겨집니다.
- Array를 탐색하고 정렬하는 비용이 더 영향력있다.
- 그래서 function의 실행 횟수(Node의 총갯수)보다 array를 탐색하고 정렬하는 비용이 더 영향력이 있다고 판단하며, array를 탐색하고 정렬하는 횟수에 집중하여 $O(n\log{n})$이라고 표현합니다.
- $\log{n}$은 ‘탐색과 정렬’이 총 몇번 이루어지는지(tree의 depth)에 관한것이고, $n$은 각 단계별로 탐색해야할 array의 길이를 의미합니다.
Space Complexity(공간복잡도)
\(O(n)\)
array를 분할하는 과정에서 추가 공간이 필요합니다.
Merge sort with $O(1)$ space complexity
array의 element가 ‘양의 정수(unsigned integers)’일때, 수학적 trick을 이용해서 $O(1)$의 알고리즘을 만들 수 있다고 합니다. https://www.geeksforgeeks.org/merge-sort-with-o1-extra-space-merge-and-on-lg-n-time/
Implementation
첫번째 시도
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
use std::ops::DerefMut;
use rand::Rng;
fn generate_rand_array(size: usize) -> Vec<u32> {
let mut rng = rand::thread_rng();
let mut rand_arr= Vec::with_capacity(size);
for i in 0..size {
rand_arr.push(rng.gen_range(1..100));
}
return rand_arr
}
fn merge_sort(mut arr: Vec<u32>) -> Vec<u32> {
merge_sort_partition(arr.deref_mut());
return arr;
}
fn merge_sort_partition(arr: &mut [u32]) -> &mut [u32] {
if (arr.len() <= 1) {
return arr;
}
let mid = ((arr.len() / 2) as f64).floor() as usize;
let (left_arr, right_arr) = arr.split_at_mut(mid);
merge_sort_partition(left_arr);
merge_sort_partition(right_arr);
let sorted_left = left_arr.to_vec();
let sorted_right = right_arr.to_vec();
let mut left_idx = 0;
let mut right_idx = 0;
for idx in 0..arr.len() {
let mut value;
let left_val = if left_idx < sorted_left.len() {sorted_left[left_idx % sorted_left.len()]} else { u32::MAX };
let right_val = if right_idx < sorted_right.len() { sorted_right[right_idx % sorted_right.len()] } else { u32::MAX };
if (left_val < right_val) {
value = left_val;
left_idx += 1;
} else {
value = right_val;
right_idx += 1;
}
arr[idx] = value;
}
return arr
}
fn main() {
// random value로 이루어진 array 생성
let mut arr = generate_rand_array(10);
println!("{:?}", arr);
// [94, 10, 54, 27, 47, 4, 69, 6, 93, 87] 출력
let sorted_arr = merge_sort(arr);
println!("{:?}", sorted_arr);
// [4, 6, 10, 27, 47, 54, 69, 87, 93, 94] 출력
}
평가
알고리즘은 잘 작동하지만,chatGPT로부터 아래와 같은 feedback을 받았습니다.
- 불필요한 메모리 사용 제거할것
left_arr.to_vec()이 부분이 기존 Vec의 slice에 대한 pointer를 기준으로 새로운 Vec를 생성함으로써, 불필요하게 저장공간을 사용하고 있다.
deref_mut사용하지 말것.- ‘Vec’의 Slice 기능을 사용할것.
- ‘deref’는 역참조(dereference, pointer가 가리키는 메모리에 접근하여 데이터를 가져오는것.) 값을 반환하는 method로서, 여기선 array의 주소를 function에 argument로 전달하기 위한 맥락으로 사용하였습니다.
- 이 ‘deref’를 명시적(explicit)으로 사용하는것은 rust에서 anti-pattern으로 여겨집니다. 메모리의 값을 읽는 것은 암시적으로 이루어져야 하는데, 명시적으로 하게되면 코드의 간결함이 떨어지게 됩니다. 이는 코드의 가독성과 안정성을 떨어트리는 요인이 됩니다.
- ‘deref’는 역참조(dereference, pointer가 가리키는 메모리에 접근하여 데이터를 가져오는것.) 값을 반환하는 method로서, 여기선 array의 주소를 function에 argument로 전달하기 위한 맥락으로 사용하였습니다.
두번째 시도
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
use rand::Rng;
fn generate_rand_array(size: usize) -> Vec<u32> {
let mut rng = rand::thread_rng();
let mut rand_arr= Vec::with_capacity(size);
for _ in 0..size {
rand_arr.push(rng.gen_range(1..100));
}
return rand_arr
}
fn merge_sort(mut arr: Vec<u32>) -> Vec<u32> {
merge_sort_partition(&mut arr);
return arr;
}
fn merge_sort_partition(arr: &mut [u32]) -> &mut [u32] {
if arr.len() <= 1 {
return arr;
}
let mid = ((arr.len() / 2) as f64).floor() as usize;
// divide
merge_sort_partition(&mut arr[..mid]);
merge_sort_partition(&mut arr[mid..]);
let mut merged_arr = arr.to_vec(); // rust의 borrow정책때문에 필요.
// merge
merge(&arr[..mid], &arr[mid..], &mut merged_arr);
arr.copy_from_slice(&merged_arr);
return arr
}
fn merge(arr1: & [u32], arr2: & [u32], result_arr: &mut [u32]) {
let mut left_idx = 0;
let mut right_idx = 0;
for idx in 0..result_arr.len() {
let value;
let left_val = if left_idx < arr1.len() {arr1[left_idx % arr1.len()]} else { u32::MAX };
let right_val = if right_idx < arr2.len() { arr2[right_idx % arr2.len()] } else { u32::MAX };
if left_val < right_val {
value = left_val;
left_idx += 1;
} else {
value = right_val;
right_idx += 1;
}
result_arr[idx] = value;
}
}
fn main() {
// random value로 이루어진 array 생성
let arr = generate_rand_array(10);
println!("{:?}", arr);
let sorted_arr = merge_sort(arr);
println!("{:?}", sorted_arr);
}
‘merge’단계를 별도의 function으로 분리하였습니다.
이 과정에서 rust의 ‘second mutable borrow occurs here’에러가 발생하였습니다.
‘second mutable borrow occurs here’
rust에서는 References and Borrowing라는 변수 및 메모리 참조 정책을 사용합니다.
borrow checker를 통해 compile단계에서의 메모리 참조 위험을 감지하고 알려줍니다. 위 코드에서 merge_sort_partition(&mut arr);의 &mut arr은 변수 arr에 대한 수정 권한을 function에 넘겨주는것과 같습니다.
이를 받는 function에선 해당 권한을 1회만 사용할 수 있습니다.
때문에, ‘second mutable borrow occurs here’ error는 이를 2회 이상 사용하려 했다는 내용입니다.
- 이를 해소하기 위해,
- arr을 별도의 메모리로 copy(여기선 새로운 Vec를 생성했습니다)하고,
- 함수 마지막에 원본 arr에 정렬된 최종 데이터를 copy함으로써 이 정책을 우회했습니다.
Reference
- Rust ‘References and Borrowing’
- https://doc.rust-lang.org/1.8.0/book/references-and-borrowing.html