Consistent Hashing | Core Concepts - System Design Interview

- ‘Consistent Hashing’은
- 분산 시스템(Distributed System)의 Cluster에서, 데이터를 분산 저장할때 사용하는 기초적인 알고리즘 입니다.
예시로 보는 Consistent Hashing의 필요성
‘Ticketing System을 구성한다고 해봅시다.
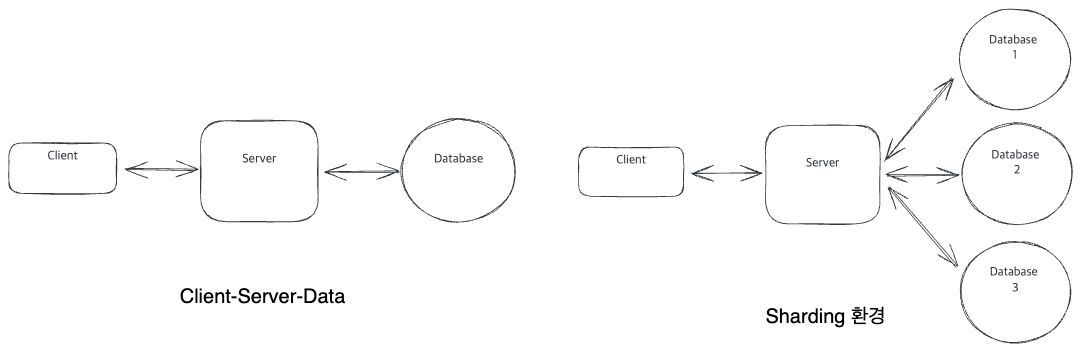 Simple System과 Sharding이 적용된 System
Simple System과 Sharding이 적용된 System
Client-Servcer-DataBase가 하나씩 구성되어 있는 ‘Simple System’으로 운영이 가능할때는 괜찮지만, 곧 다루는 이벤트(행사의 이벤트)가 늘면서 Data를 여러 Node에 분산시켜야 하게 됩니다.
데이터를 분산시키는 방법 : Simple Modulo Hashing
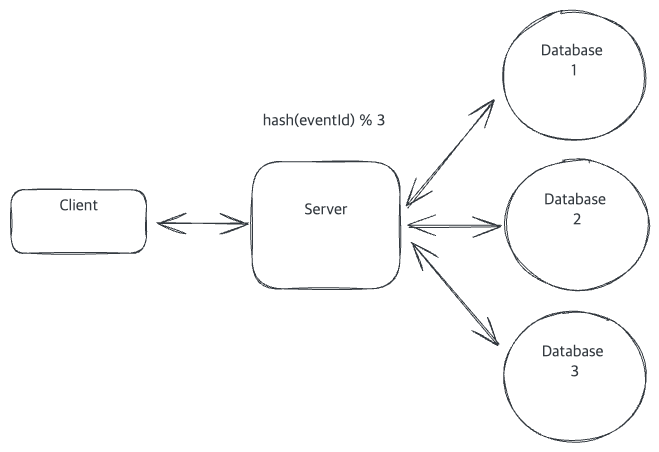 단순한 Modulo를 이용한 알고리즘
단순한 Modulo를 이용한 알고리즘
가장 단순하게 접근하면,
- Event의 ID를 Hash처리하여, number값으로 만듭니다.
- 해당 number값을 Modulo(%)연산을 통해 데이터베이스를 할당합니다.
- 할당된 DB에 데이터를 저장합니다.
이때의 문제점
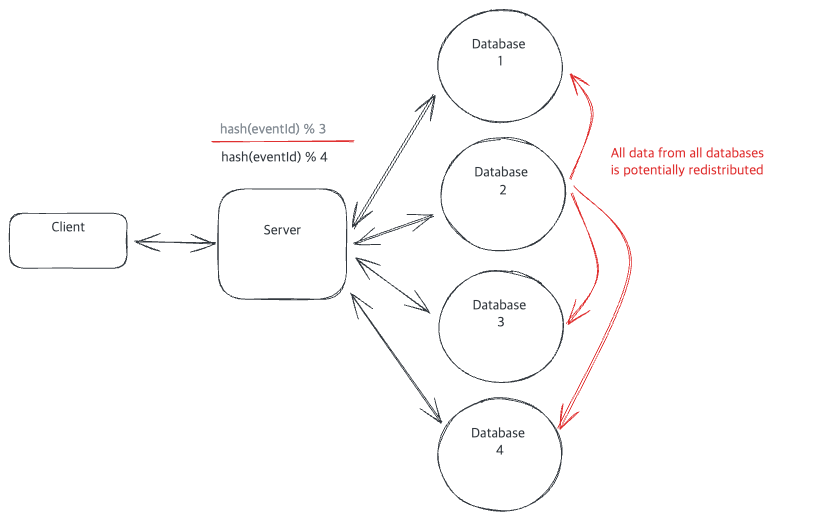 DB Cluster에 Node가 추가된다면..
DB Cluster에 Node가 추가된다면..
이때, DB Cluster에 Node가 추가된다면, Modulo의 값이 바뀌게 되면서, 전체 Data가 재분배(redistributed)되어야 하는 상황이 발생합니다.
이런 Data 재분배(redistributed)상황은 DB의 많은 리소스를 차지해서, 시스템에 장애를 만들어낼 수 있습니다. 즉, DB운영 작업에 리소스가 많이 투입되어, 외부 요청을 처리하지 못하게 됩니다.
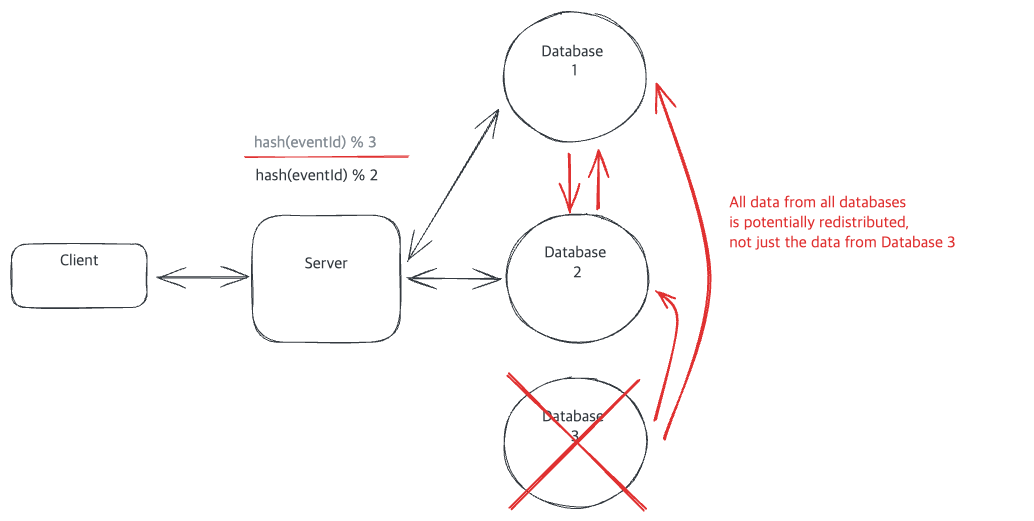 DB Cluster에 Node가 제거된다면..
DB Cluster에 Node가 제거된다면..
반대로, DB Cluster에서 Node가 제거되는 상황에서도, Data 재분배(redistributed)가 발생하게 됩니다.
Consistent Hashing의 필요성
‘Consistent Hashing’은 이런, 분산환경(Distributed System)에서 DB Instance구성이 변경되는 상황에 대한 솔루션을 제공해줍니다.
Q: 여기서 ‘Consistent’의 의미는 무엇인가요?
A: 노드가 추가되거나 제거되더라도(분산 환경 변화에도) 키–노드 매핑이 일관되게(consistent) 유지된다는 특성에서 유래하고 있습니다.
이전 방식인 Modulo방식은 Node 구성이 변경됨에 따라, 전체 데이터가 re-hashing되어야 하지만, ‘Consistent Hashing’은 일관된 Hash값을 제공하여, re-hashing을 최소화합니다.
핵심 아이디어는, Data와 Database를 ‘hash ring’이라 불리는 ‘Circular space(순환 공간)’에 정리해 두는 것입니다.
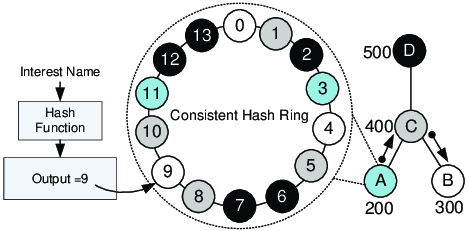 Consistent Hash Ring
Consistent Hash Ring
Consistent Hashing의 작동 과정
DB Node가 4개 있다고 가정했을때, 이를 통해 ‘Hash Ring’을 구성합니다.
그리고 이 Hash Ring의 고정값의 범위를 0 ~ 100으로 구성합니다.(예시로 구성, 100 이상도 가능합니다.)
DB Node들은 이 Hash Ring에 일정하게 분포되도록 합니다.(데이터를 균일하게 분포시키기 위해)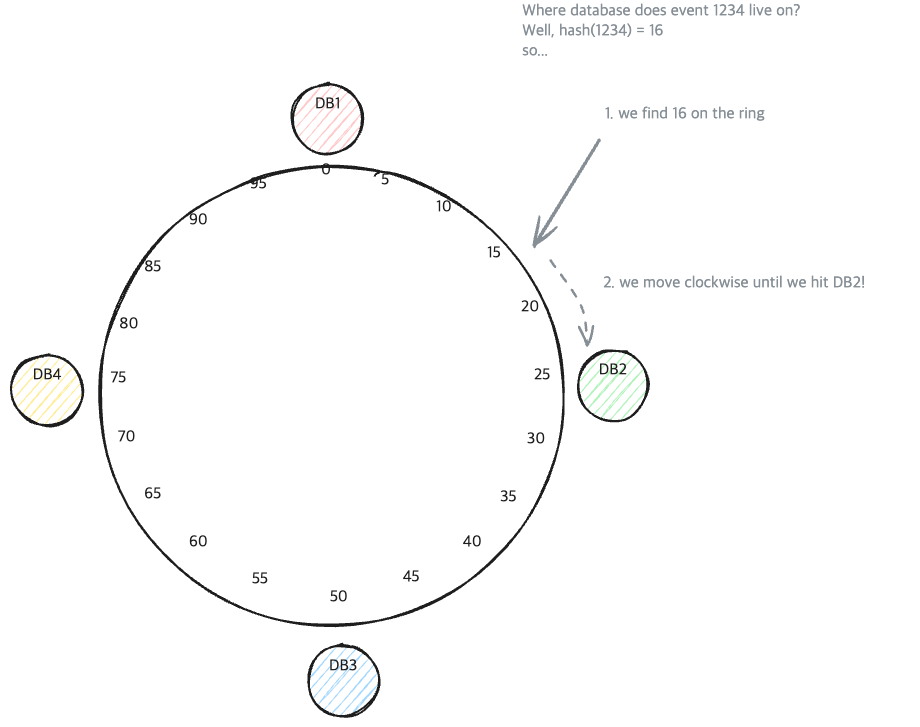 Hash Ring | hellointerview.com
Hash Ring | hellointerview.com여기서 삽입(insert)하고자 하는 데이터의 hash값이 만들어지면, 시계 방향으로 제일 가까운 DB Node에 저장합니다.
이 과정은, 아래와 같습니다.- 데이터의 Key값을 Hash처리 합니다.
Hash값을 기반으로, Hash Ring위의 위치를 계산합니다.
이때, Hash처리한 값을 Hash Ring위의 좌표로 변환하기 위해, Hash Ring 값의 범위로 Modulo하는 과정을 거칩니다.\(h_{\rm ring} = \text{hash}(\,\text{key}\,) \bmod M \text{(M은 Ring의 크기)}\)
이는, $H = \text{hash}(key)$의 값의 범위가, 보통 Hash Ring의 범위보다 크기 때문에 필요합니다.
- $h_{\rm ring}$(Hash Ring위의 좌표)에서 값을 증가시키며, 가장 가까운 DB Node를 찾습니다.(Ceil연산)
- DB Node를 찾게 되면, 해당 Node에 데이터를 저장합니다.
DB Node가 추가되는 경우
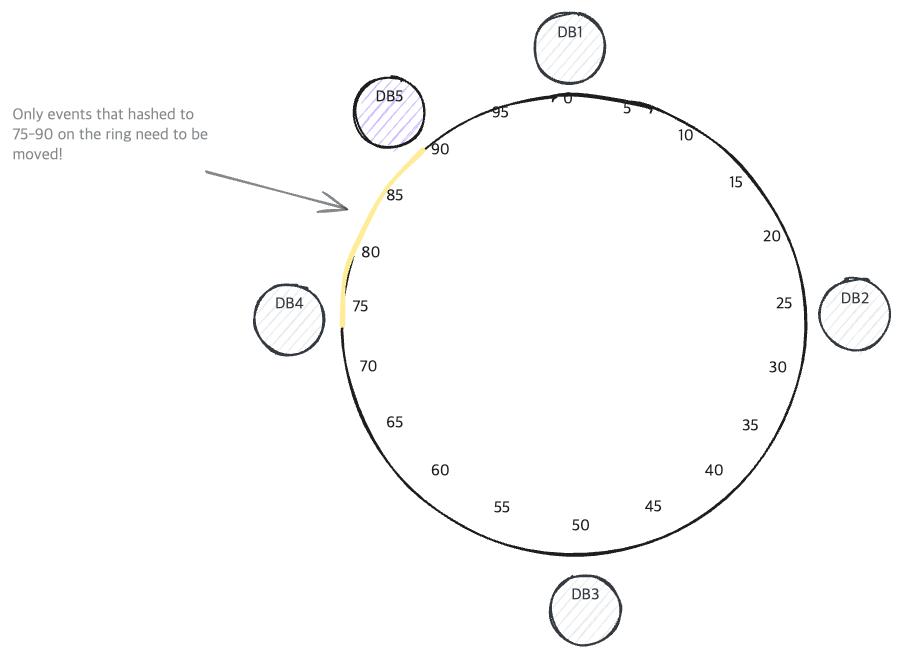 DB Node가 추가되는 경우 | hellointerview.com
DB Node가 추가되는 경우 | hellointerview.com
이 경우, 전체 데이터가 아닌, 일부 데이터에 대해 데이터 재배치가 이루어집니다.
- 만약, DB4와 DB1사이에 새로운 DB5를 위치시킨다면,
- DB1에 가야 했던 일부 데이터가 DB5로 재배치됩니다.
- 다른 데이터들은 그대로 위치합니다.
- 이 예시의 경우, DB1에 있던 데이터의 약 30%정도의 데이터만 재배치 됩니다.(Hash Ring의 값에 따른 추정)
- 다른 데이터들은 그대로 위치합니다.
DB Node가 제거되는 경우
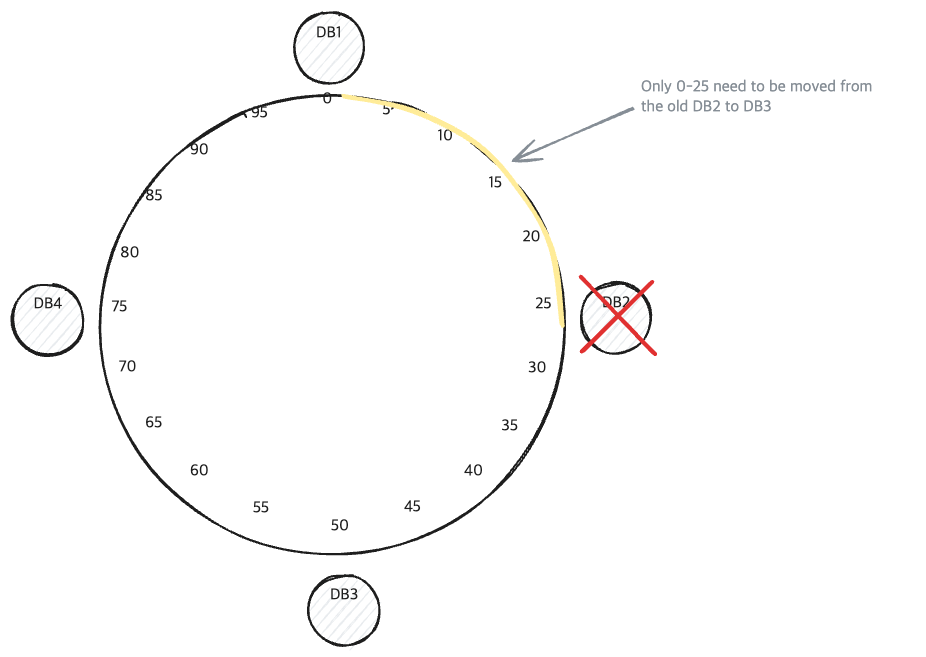 DB Node가 제거되는 경우 | hellointerview.com
DB Node가 제거되는 경우 | hellointerview.com
이 경우, 제거된 Node에 있던 데이터만 재배치 됩니다.
- 만약, DB2가 시스템 장애로 Cluster에서 제거됐다면,
- DB2에 있던 데이터 전부가, DB3에 재배치됩니다.
- 다른 데이터들은 그래도 위치합니다.
여기까지, ‘단순 Modulo방식’에 비해 많이 개선된 부분이 있지만, 여전히 ‘DB Node가 제거되는 경우 Node의 전체 데이터가 재배치되는 문제’가 있습니다.
이는 Hash Ring위에서 DB Node간 데이터양의 불균형을 만들어냅니다.
이를 해결하기 위해, ‘Virtual Node’로 Hash Ring을 구성하는 방법을 사용합니다.
Virtual Nodes로 Hash Ring 구성하기
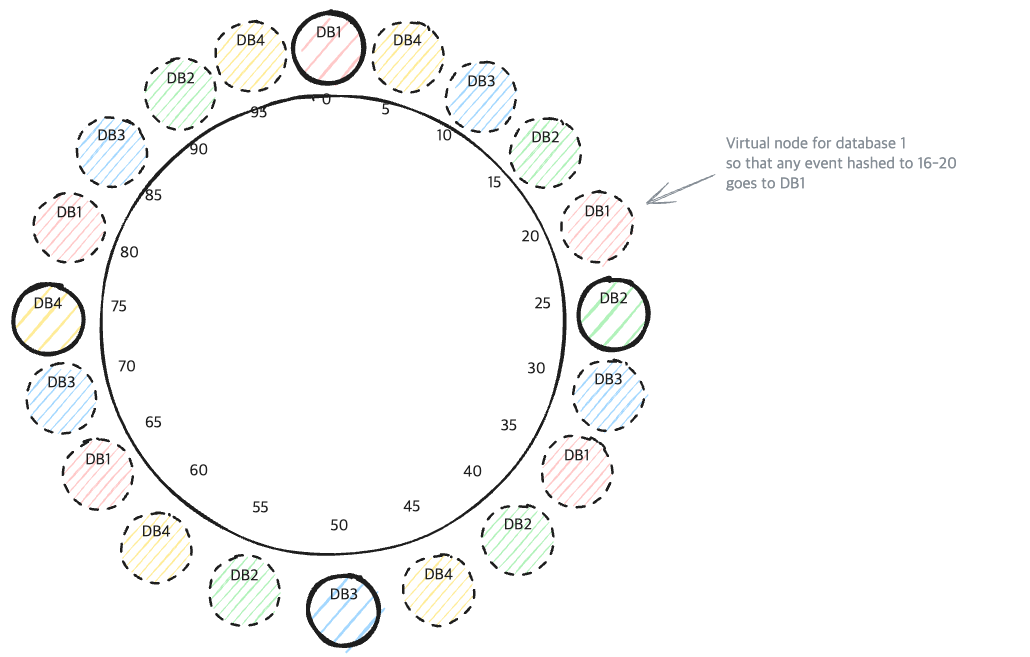 Hash Ring을 Virtual Node로 구성합니다. | hellointerview.com
Hash Ring을 Virtual Node로 구성합니다. | hellointerview.com
- 이 ‘Virtual Nodes’방법은,
- Hash Ring위에 단 하나의 지점에만 Node를 배치하는것이 아닌, 여러 지점에 가상(Virtual)으로 배치하는 방법입니다.
- 만약, DB2가 Fail상태가 된다면,
- Hash값에 따라, 데이터가 재배치 됩니다.
- 이때, Hash값에 따라, 남아 있는 다른 Node(DB1, DB3, DB4)에 분산되어 재배치됩니다.
즉, Node가 Fail상태가 되면, 해당 Node의 데이터가 여러 Node로 분산되어 재배치됩니다.
Virtual Nodes를 사용하는 이유
데이터 분포 균일화
실제 노드가 링 위에 딱 하나의 점으로만 존재하면, 해시 함수 특성에 따라 특정 영역에 데이터가 몰릴 수 있습니다.
각 실제 노드를 여러 개의 작은 “가상 노드”로 분할해 링 위에 고르게 흩어 놓으면, 키가 더 고르게 분산됩니다.노드 용량·성능 차이 반영
머신마다 처리 성능이 다를 때, 노드마다 할당할 가상 노드 수를 달리 줌으로써 “무거운” 머신에 더 많은 샤드를 몰아줄 수 있습니다.
예) CPU·메모리가 2배인 노드는 가상 노드를 2배 배치노드 추가·제거 시 부드러운 재배치
실제 노드 하나를 추가/삭제할 때마다 전체 키 공간 중 가상 노드 하나 분량만 이동하면 되므로,
“영향받는 키 비율”이 1/N → 1/(N·v) 수준으로 더욱 작아집니다.(여기서 v는 각 실제 노드당 가상 노드 개수)운영 유연성
가상 노드 단위로 릴리스·점검이 가능해, 실제 노드를 직접 건드리지 않고도 롤링 업데이트나 장애 격리가 수월해집니다.
Consistent Hashing 사용 사례
‘Consistent Hashing’은 데이터를 분산하는 ‘방법’에 해당하기 때문에, DB뿐만 아니라, Cache, Message Broker등의 사례가 있습니다.
Apache Cassandra
- ‘Apache Cassandra’는
- 분산 키-값 저장소로, 내부적으로 Consistent Hashing 기반의 토큰 링(token ring) 구조를 사용해 데이터를 분산·저장합니다
- Node(virtual node) 개념을 도입해, 클러스터 내 각 물리 Node에 여러 개(기본 256개)의 토큰을 랜덤 배치하며, 데이터 분포를 훨씬 고르게 만듭니다.
Apache Cassandra는 Amazon의 ‘Dynamo’ 분산 저장 시스템을 사용하고 있습니다.
(이런 Case를 Dynamo-style 시스템이라고 합니다.)
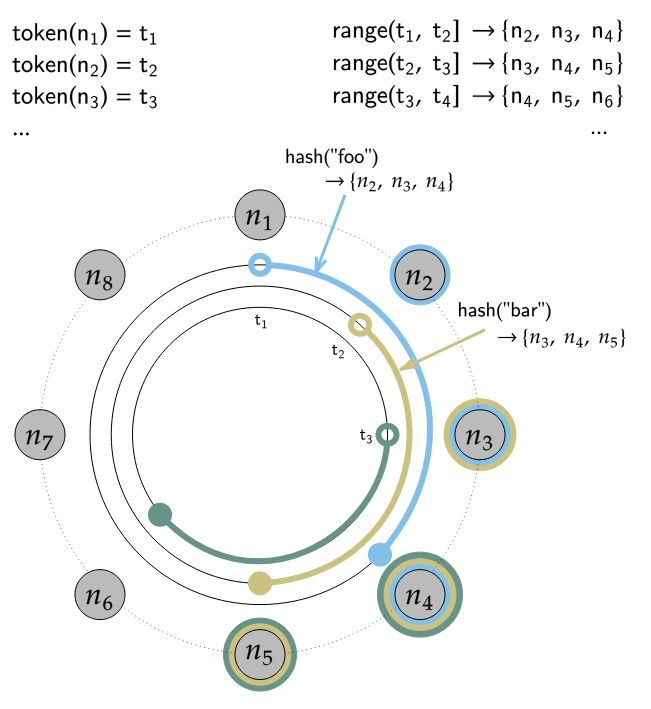 Apache Cassandra의 Token Ring | cassandra.apache.org
Apache Cassandra의 Token Ring | cassandra.apache.org
Amazon DynamoDB
- ‘Amazon DynamoDB’은
- 완전관리형 NoSQL 키–값·문서(Document) 데이터베이스입니다.
- 데이터의 ‘Partition’ 과정에서 ‘Consistent Hashing’을 사용하고 있습니다.
Content Delivery Networks(CDNs)
- ‘CDNs’은
- 전 세계에 분산된 엣지(Edge) 서버들에 콘텐츠를 캐시(Cache)하고, 사용자의 요청을 가장 적절한 서버로 라우팅해 응답 지연(latency)을 줄이는 시스템입니다.
- CDN에서 Server(Node) Pool을 관리할때, ‘Consistent Hashing’을 사용합니다.
- 요청 URL에 따라 이 Traffic을 처리할 Node가 정해지는 방식입니다.
- CDN에서 Server(Node) Pool을 관리할때, ‘Consistent Hashing’을 사용합니다.
단순히 URL로만 Node가 정해지면, 특정 Server(Node)가 ‘Hot’상태에 도달하게 됩니다.
때문에, 실제 CDN의 설계는 Consistent Hashing 단독이 아니라, 여러 기법을 조합해 핫스팟을 완화하게 됩니다.(인기 콘텐츠일 수록 여러 Edge서버에 복제본을 두는 등..의 방식 사용)
References
- Consistent Hashing | hellointerview.com
- Hello Interview | System Design in a Hurry
- Consistent hash ring | researchgate.net
- FIGURE 4: Consistent hash ring and forwarding process.
- Consistent Hashing Explained | systemdesign.one
- Consistent Hashing Explained
- Design Consistent Hashing | bytebytego.com
- System Design · Coding · Behavioral · Machine Learning Interviews
- Dynamo | cassandra.apache.org
Apache Cassandra relies on a number of techniques from Amazon’s Dynamo distributed storage key-value system.
- Apache Cassandra에서의 분산 저장 시스템은 Amazon의 Dynamo의 테크닉에 영향을 받았다는 얘기.(Dynamo-style 시스템)
- Dynamo | Apache Cassandra Documentation
- Apache Cassandra에서의 분산 저장 시스템은 Amazon의 Dynamo의 테크닉에 영향을 받았다는 얘기.(Dynamo-style 시스템)
- Dynamo: Amazon’s Highly Available Key-value Store(논문) | www.cs.cornell.edu
- www.cs.cornell.edu
- How is hashing speeding up your CDN | cdn77.com
- How is hashing speeding up your CDN | CDN77.com
- Distributing Content to Open Connect | netflixtechblog.com
We use Consistent Hashing to distribute content across multiple servers as follows.
- Distributing Content to Open Connect