ChatGPT API 비용최적화 및 Bulk요청 보내기 | Prompt Engineering

LLM을 이용한 서비스를 개발할때, 처음에는 ChatGPT와 같은 SaaS(Software as a Service)의 API를 사용하게 됩니다.
이 API를 기반으로 Production 서비스를 운영하게 되면, 생각보다 많은 비용이 나오게 됩니다.
ChatGPT API Pricing
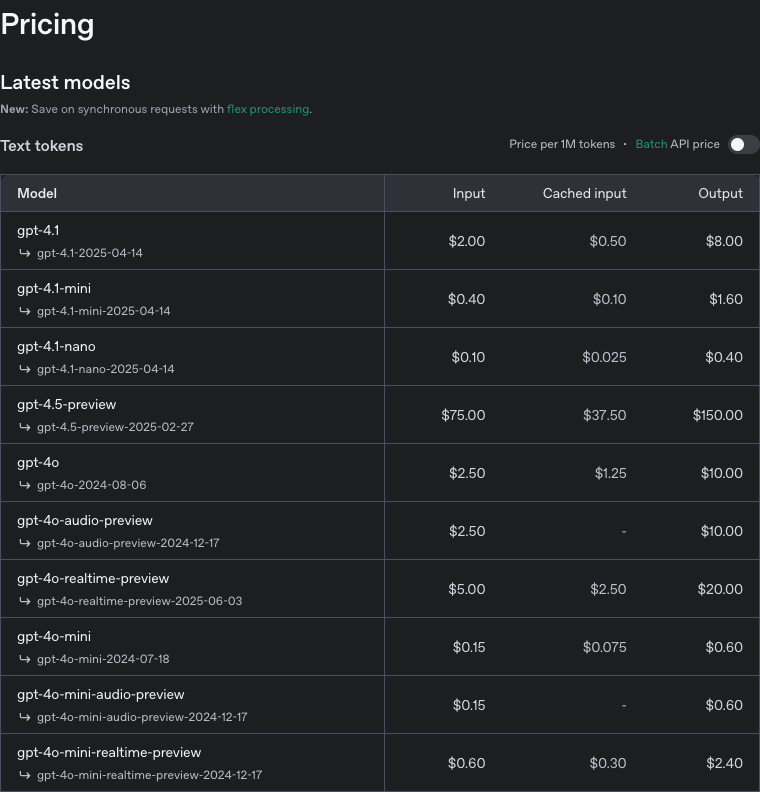 ChatGPT API Pricing
ChatGPT API Pricing
ChatGPT API의 Pricing 정책에 따르면, 다음과 같은 내용에 대해, 1M token당 과금정책을 사용합니다.
Input
LLM에 입력으로 사용되는 모든 텍스트에 대한 토큰수 입니다.Cached input
Cache정책에 따라, ChatGPT 서버에 캐시된 요청을 재사용할 경우, 별도의 token당 과금 정책이 적용됩니다.(좀 더 저렴합니다.)Output
LLM의 Output에 해당하는 모든 텍스트의 토큰수 입니다.
ChatGPT의 tokenizer를 통해, token갯수를 계산할 수 있습니다.
API 비용 최적화
- 위의 Pricing정책을 기준으로 보면, 비용최적화 방법은,
- Token 수를 줄이면서 동일한 작동을 하게 합니다.
- Pricing 정책 자체를 저렴하게 적용받도록 합니다.
이렇게 나뉘어 집니다.
이에 따라 비용 최적화 방법을 알아보겠습니다.
Prompt Cache가 적용되는 모델 사용하기
Prompt Caching is automatically applied on the latest versions of GPT‑4o, GPT‑4o mini, o1‑preview and o1‑mini, as well as fine-tuned versions of those models.
- from OpenAI Blog
ChatGPT API의 최신 모델을은 이전에 사용한 Input 데이터를 Cache해서 재사용합니다.
이 Cache된 Token들은, 5~10분정도 후에 비활성화 되고, 마지막으로 사용한지 1시간 안에 완전히 제거된다고 합니다.
아래는, API 요청에 대한 Response Body입니다.
여기서, cached_tokens 를 통해, cache를 사용했는지 알 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"...": "",
"usage": {
"total_tokens": 2306,
"prompt_tokens": 2006,
"completion_tokens": 300,
"prompt_tokens_details": {
"cached_tokens": 1920,
"audio_tokens": 0,
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"audio_tokens": 0,
}
}
}
Fine-tuning시에는 저렴한 이전세대 모델을 사용합니다.
만약 모델을 Fine-tuning해서 사용한다면, 별도의 Pricing이 적용됩니다(좀 더 비쌉니다).
이때, 무조건 최신 모델을 쓰는 것보다, 이전 세대의 모델을 Fine-tuning해서 사용하는게 더 적합합니다.
‘Fine-tuning’하게 되는 의도를 봤을때, 사용 목적이 뚜렷하기 때문에, 이전 세대의 모델에서도 충분한 성능을 발휘해서 그렇습니다.
이때, 트레이닝 데이터를 만들때, 상위 모델을 사용해서 데이터를 만들면 더 효과적입니다.
References
- GPT-3.5-Turbo is cheap and fast, but is’s not as smart as GPT-4 | OpenAI Youtube
The New Stack and Ops for AI
Prompt내 JSON에 대해, minify하기
Input Prompt내에, JSON형식을 사용하는 부분이 있다면, 이를 minify하면, Token절약에 도움이 됩니다.
minify하게 되면, 들여쓰기(indentation)와 같은 공백과 줄바꿈이 제거됩니다.
아래 JSON 데이터를 기준으로 비교해 보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
{
"orders": [
{
"orderId": "A1",
"date": "2025-07-01",
"customerName": "김철수",
"items": [
{ "productId": "P1", "qty": 2 },
{ "productId": "P2", "qty": 1 }
]
},
{
"orderId": "A2",
"date": "2025-07-01",
"customerName": "이영희",
"items": [
{ "productId": "P3", "qty": 1 }
]
},
{
"orderId": "A3",
"date": "2025-07-01",
"customerName": "박민수",
"items": [
{ "productId": "P4", "qty": 3 },
{ "productId": "P5", "qty": 2 }
]
}
]
}
원본의 Token 수
215개의 Token으로 나누어 집니다.
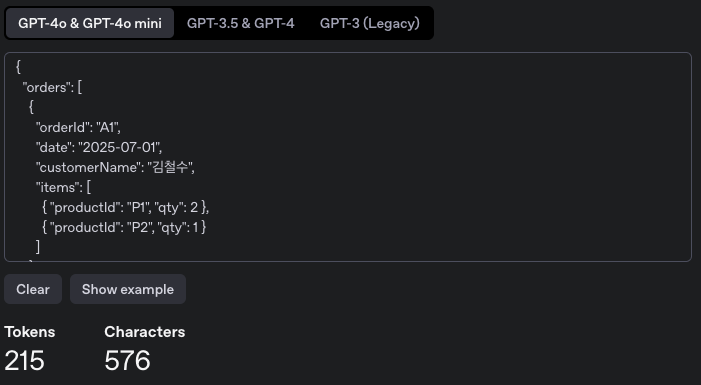 원본 JSON의 Token 수
원본 JSON의 Token 수
Minified된 JSON의 token 수
기존의 215 → 133으로 Token수 가 줄었습니다.
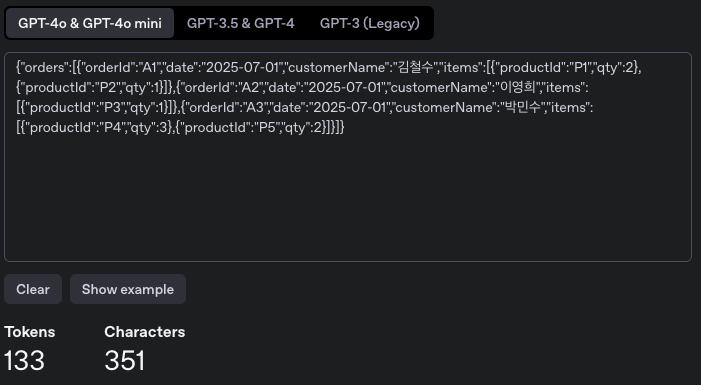 Minified JSON의 Token 수
Minified JSON의 Token 수
Bulk 요청으로 System Prompt 비용 최소화 하기
ChatGPT API를 Production 서비스에서 사용할때, Input 데이터로 가장 반복적이고 큰 부분을 차지하는 것이 ‘System Prompt’입니다.
이 ‘System Prompt’를 재사용 하는 방법으로, LLM에 여러 요청을 한번에 보내는 ‘Bulk’요청을 생각하게 되었습니다.
처음에는, ChatGPT앱에서 처럼, 대화창을 하나 생성해서, Context를 재사용하는 방법을 찾아보았지만, 그런 방법은 없었습니다.
‘System Prompt’는 ChatGPT에게 지시사항을 입력하는 용도의 Prompt입니다.
이는, ChatGPT API의 ‘Structured Output’기능을 통해, LLM에 Bulk요청에 대한 의도를 전달하는 방법입니다.
Example
System Prompt를 다음과 같이 구성합니다.
‘Few shot’을 위해, 몇가지 Example을 전달합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
## System prompt
**Role**
- English-speaking coach
**Goal**
- Assess grammar and non-native difficulty.
**Few-Shot Examples**
**Example 1**
Input Sentence:
1. “And now I'm going to clean up or remove the clutter in this space.”
2. Build your muscle memory, so in the interview, it will naturally be easier to pronounce.
Output:
{"0":{"difficulty":"medium","grammar":"correct"},"1":{"difficulty":"medium","grammar":"correct"}}
JSON Schema를 이용해, ‘Structured Output’을 설정합니다.
Response Schema
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
{
"name": "check-grammar",
"strict": true,
"schema": {
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"patternProperties": {
"^[0-9]+$": {
"$ref": "#/definitions/body"
}
},
"additionalProperties": false,
"definitions": {
"body": {
"type": "object",
"properties": {
"difficulty": {
"type": "string",
"enum": [
"low",
"medium",
"high"
]
},
"grammar": {
"type": "string",
"enum": [
"correct",
"incorrect"
]
}
},
"required": [
"difficulty",
"grammar"
],
"additionalProperties": false
}
},
"properties": {},
"required": []
}
}
이제 User Prompt안에서 Bulk로 처리할 수 있습니다.
1
2
3
4
## User Prompt
Input Sentence:
1. Not until the culmination of her exhaustive research did Dr. Emerson realize the profound implications her findings would have on contemporary epistemology.
2. DevOps is everywhere, but too often, people think they can buy “DevOps in a box” and just sprinkle some tools and automation over your broken or slow (or even super-fast AWS) stack.
Output
1
{"0":{"difficulty":"high","grammar":"correct"},"1":{"difficulty":"medium","grammar":"correct"}}
Batch 요청 사용하기
꼭 동기식(Synchronous) 처리가 필요한게 하니라면, 비동기식(Asynchronous)처리인 ‘Batch API’를 통해 50%정도의 비용을 줄일 수 있습니다.
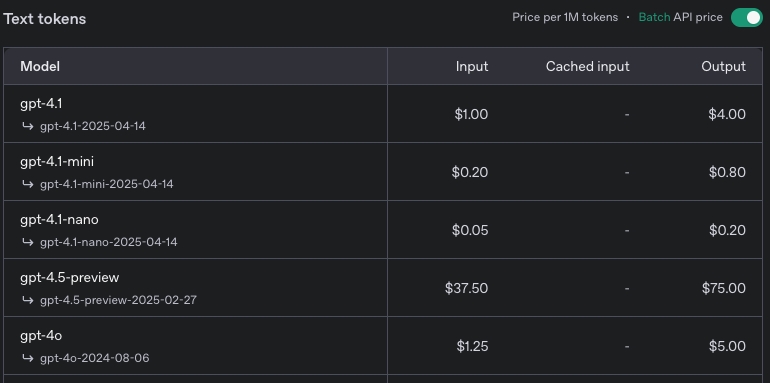 ChatGPT Batch API Pricing
ChatGPT Batch API Pricing
References
- ChatGPT API Pricing | ChatGPT API Reference
- OpenAI Platform
- Prompt Caching int the API | OpenAI Blog
- Prompt Caching in the API
- Prompt Caching | ChatGPT API
- OpenAI Platform
- Structured Outputs | ChatGPT API Reference
- OpenAI Platform
- GPT-3.5-Turbo is cheap and fast, but is’s not as smart as GPT-4 | OpenAI Youtube
- The New Stack and Ops for AI
- ChatGPT Batch API | ChatGPT API Reference
- OpenAI Platform