AWS Summit Seoul 2025 Insight
들어가면서
이번 AWS Summit은 생성형 AI를 중심으로, 데이터 엔지니링, 운영, AI모델 활용 측면의 주제가 많았습니다.
생성형 AI(이하 Gen AI)가 업계의 새로운 광산(금을 케는)이 되었고, 이에 따라 기술적 전략을 수립하기 위한 Insight를 얻기에 좋은 자리였습니다.
본문
업계의 트렌드가 보편적인 목적의 AI모델(GPT와 같은 Foundation Model)을 활용하여, 빠르게 서비스를 구축하여 제공하는것으로 이미 진행되고 있습니다. 이에 따라, AI모델에 대한 사용방법과, Custom을 위한 데이터 수집 관점의 세션을 주로 참석하였습니다.
생성형 AI(Generative AI, 이하 Gen AI)
‘Amazon’ 서비스에서는, 모든 서버 요청에 대해, latency(혹은, 서버 응답시간)에 대해 ‘p99 1 sec 미만’을 유지하는걸 목표로 하고 있습니다.
latency에 대한 p99 값은, 전체 요청을 모집단(Population)으로 했을때, 99%에 위치하는 latency를 의미합니다.
즉, 여기서는 99%에 위치한 유저의 지연시간이 1초 미만임을 의미합니다.
이는, Gen AI에 대해서도 마찬가지인데, 실제로 Amazon에서 쇼핑과 관련한 GenAI에 대한 시연도 1 sec 정도의 latency를 보여주었습니다.(엄청 빨랐습니다)
‘Amazon’은 모두 AWS서비스를 통해 구성하기 때문에, AWS에서 제공하는 AI서비스들을 알 수 있었습니다.
Unified Studio
AI를 개발하는 과정의 통합환경.
AI를 개발할 때에는, 여러 데이터와 서비스들에 대한 ‘접근’이 필요한데, 이를 통합된 환경으로 제공해주는 서비스입니다.
 Unified Studio에서 사용 가능한, AI 작업의 목적에 따른 AWS서비스 분류. 각 서비스별로 어떤 역할을 하는지 쉽게 파악할 수 있습니다.
Unified Studio에서 사용 가능한, AI 작업의 목적에 따른 AWS서비스 분류. 각 서비스별로 어떤 역할을 하는지 쉽게 파악할 수 있습니다.
Amazon Bedrock
AWS의 AI서비스중, Bedrock은 여러 Foundation Model(Anthropic, Deepseek, Amazon Nova등)을 기반으로 빠르게 생성형 AI를 구축하게 해주는 Serverless Service입니다.
‘Foundation Model’은 보편적인 목적으로 미리 학습된 모델을 의미합니다. 이런 개념이 생기기 전에는, 각 목적(이미지 편집, 목소리 모사)에 맞는 모델을 직접 만들어야 했는데, 이제는 보편적인 목적으로 만들어진 ‘Foundation Model’을 시작점으로 하여, Custom하는 방식으로 접근합니다.

Amazon Bedrock의 여러 기능들
- 모델 증류(Model distillation)란?
더 큰 모델(파라미터가 더 많은)을 가지고, 더 작은 모델을 지도학습 시켜서, 작은 모델의 퀄리티를 높이는 테크닉입니다.
이렇게 하는 이유는, AI가 발전함에 따라, 더 적은 비용, 더 빠른 서비스를 제공하기 위함입니다.
뿐만아니라, ‘On device AI’(각자의 핸드폰에서 AI를 돌리는것으로 생각하시면 됩니다)에 대한 요구사항을 위해 사용됩니다.
OpenAI Platform
딥러닝 모델 지식의 증류기법, Knowledge Distillation
Bedrock에서는 여러 추론(Inference) 옵션(사용 요금 정책 개념)이 있습니다.
각각 ‘On demand(사용한 만큼)’, ‘Provisioned(사용량 예약)’, ‘Batch(비실시간, 예약처리)’가 있습니다.

Amazon Nova
Bedrock에서, Amazon이 만든 GPT Model인 ‘Nova’를 사용할 수 있습니다.
 Amazon Nova 모델 종류.
Amazon Nova 모델 종류.
한글도 지원합니다. 하지만, 한글에서의 성능은 검증이 좀 필요합니다.
모델 소개 페이지 Nova 모델 소개
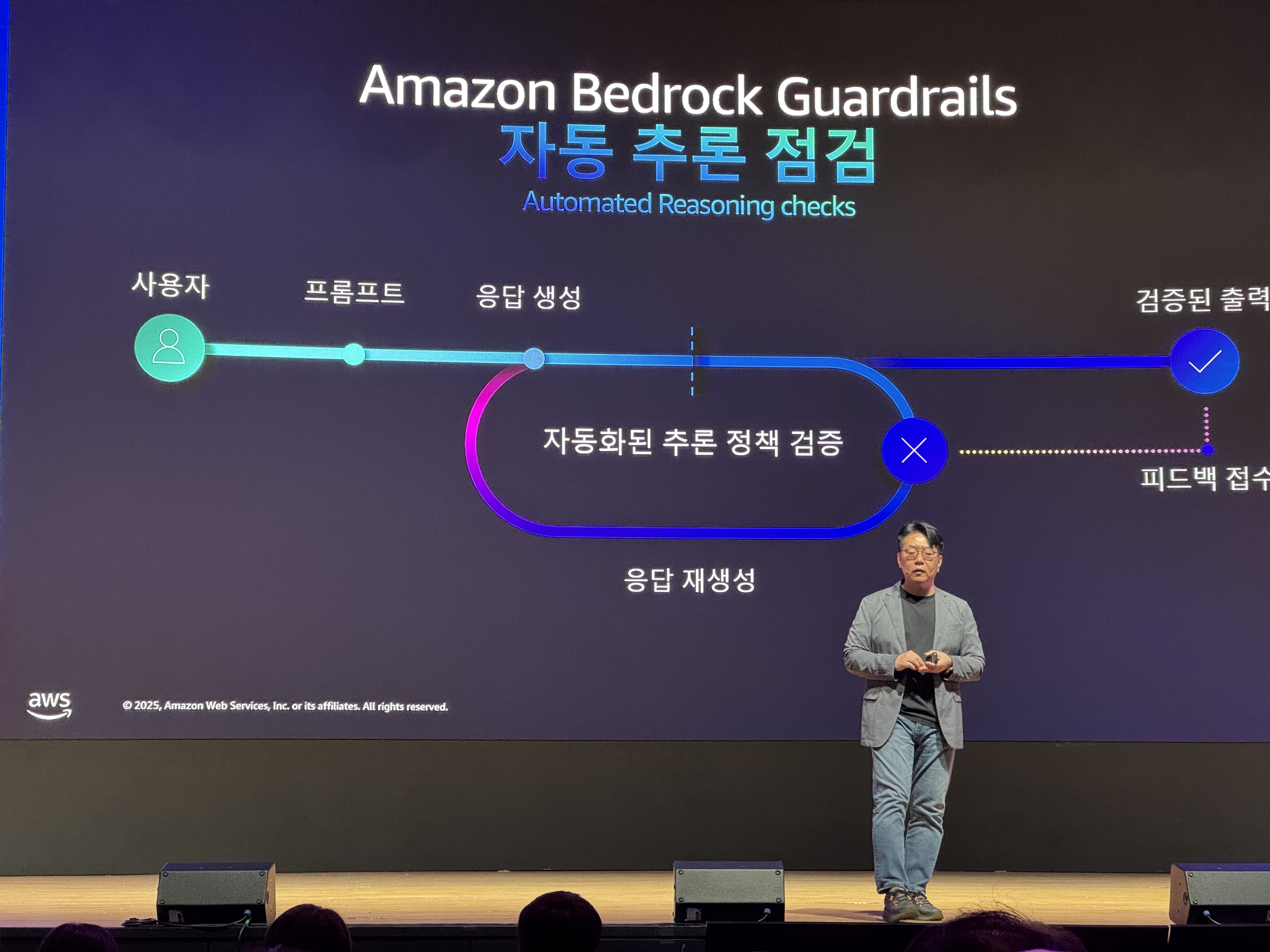
Amazon Bedrock Guardrails
Gen AI를 쓸때, 민감한 정보가 ‘권한이 없는 유저에게 전달되는것’에 대한 우려가 있는데, 이를 위한 보안 기능입니다.
Amazon Q Business
사내 데이터를 연결하여, 빠르게 사내용 AI Agent를 만들게 해줍니다.
한글 기반으로, 자체적으로 Query를 생성하여, 적절한 DB에 요청을 보내주기도 합니다.
Amazon Q Business 정식 버전 출시 – 생성형 AI 기반 업무 생산성 향상 지원 기능 추가 | Amazon Web Services
Gen AI와 RAG
Gen AI의 치명적인 단점중 하나가, 환각(hallucination, 속이는것)입니다. 즉, 없는 데이터를 그럴듯하게 만들어내는 문제가 있습니다. 이를 해결하기 위한 Solution으로 사용되는것이 RAG(Retrieval, Augmented, Generation)입니다.
RAG는 결국, GenAI가 참조할 수 있는 정보를 추가로 제공해주는 개념입니다.
이 RAG를 제공하기 위해, Gen AI에서 접근 가능한 DB에, Gen AI가 이해할 수 있는 형태(Vectorized)의 데이터가 준비되어 있어야 합니다.
이는, ‘데이터 저장공간’에 대한 준비 뿐만 아니라, ‘데이터 전처리’도 필요하다는 것을 의미합니다.
사례, ‘ENVERUS’
Foundation Model을 기반으로, Custom 목적의 데이터 수집을 어떤 Flow로 하는지 알 수 있었습니다.
 ENVERUS의 데이터 처리 Flow
ENVERUS의 데이터 처리 Flow
이를 Pipeline Architecture로 세분화 하여 표현하면, 아래와 같습니다.
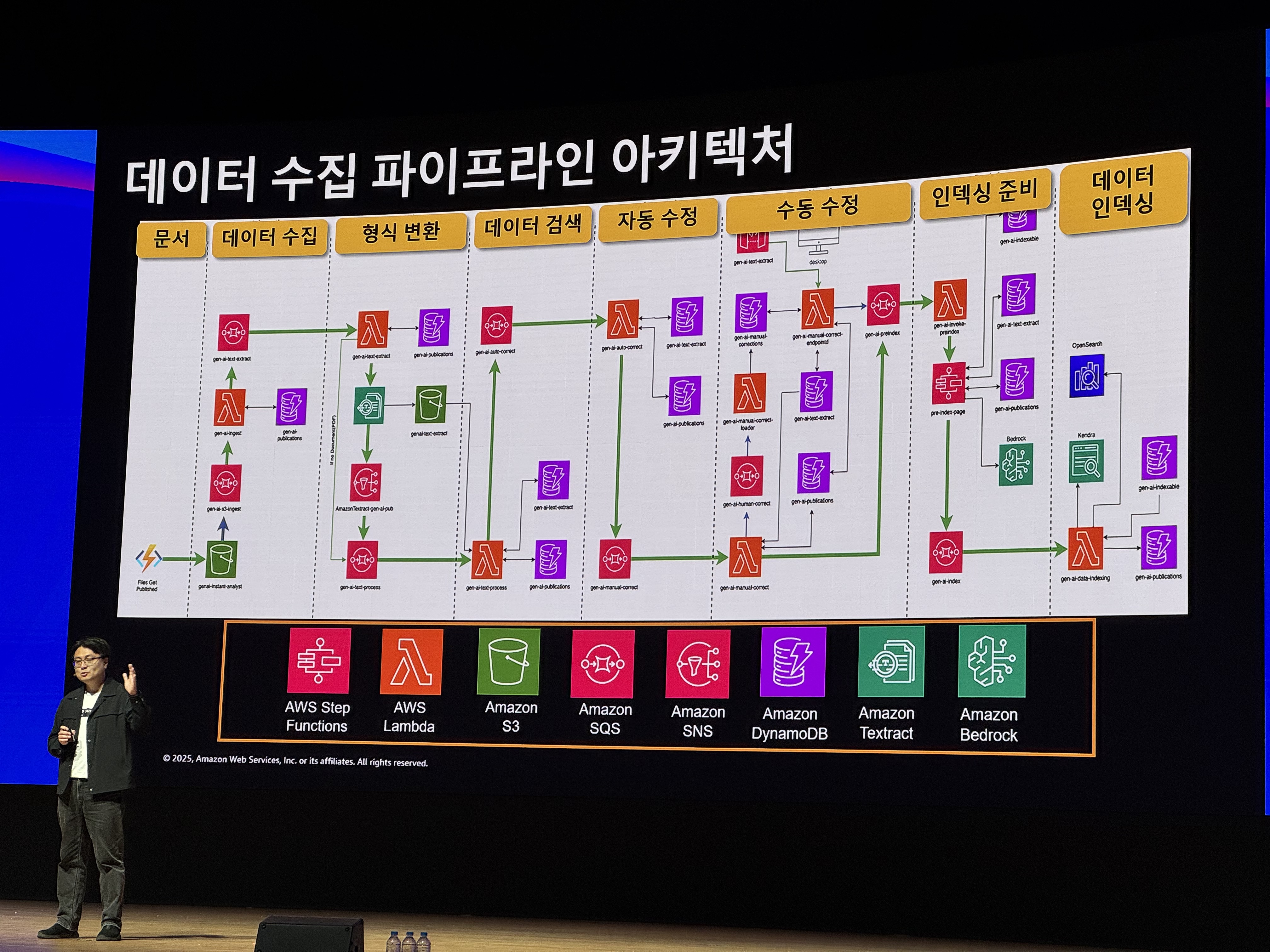 ENVERUS의 데이터 수집 Pipeline Architecture
ENVERUS의 데이터 수집 Pipeline Architecture
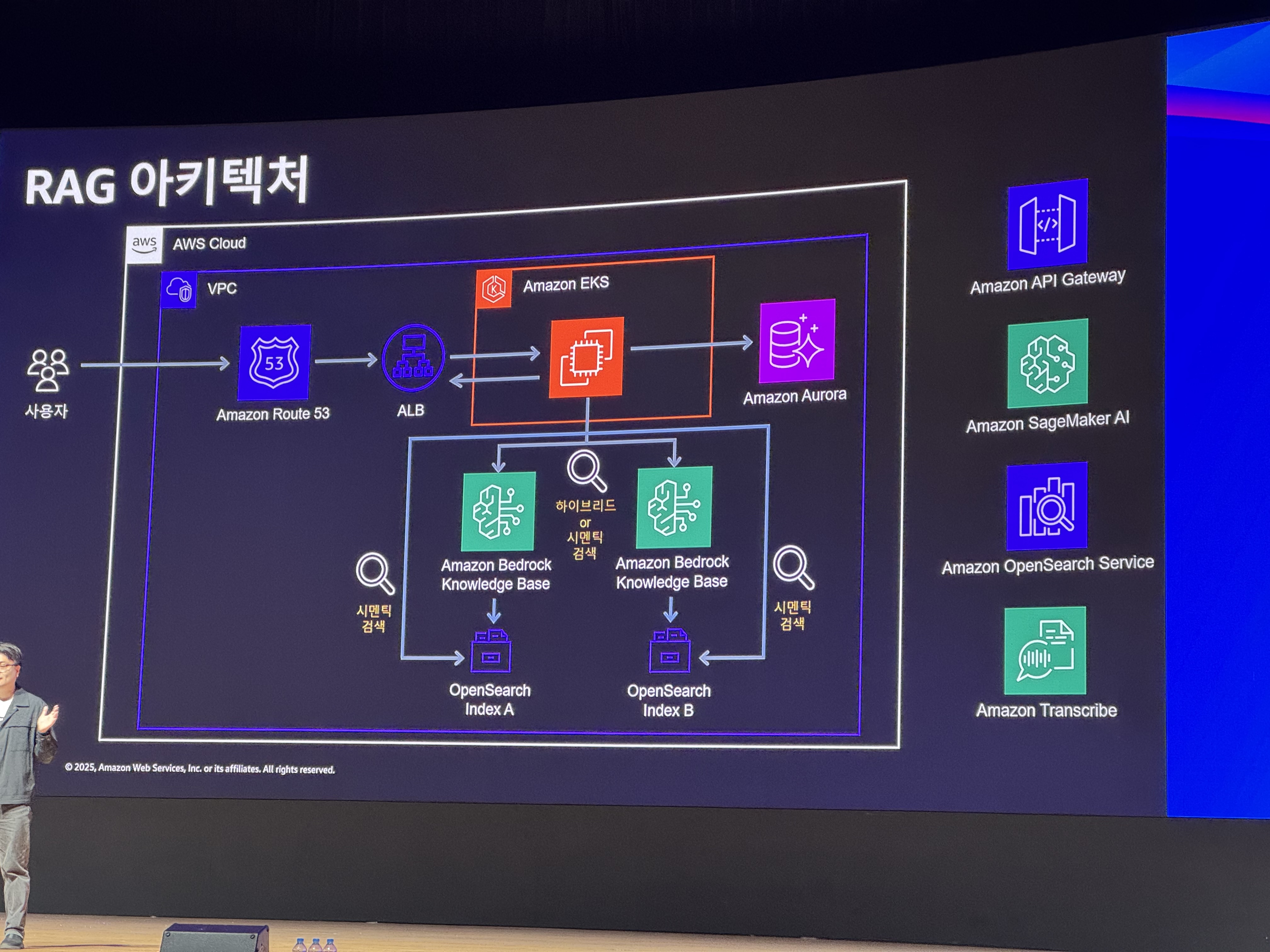 RAG를 구성하는 System Architecture
RAG를 구성하는 System Architecture
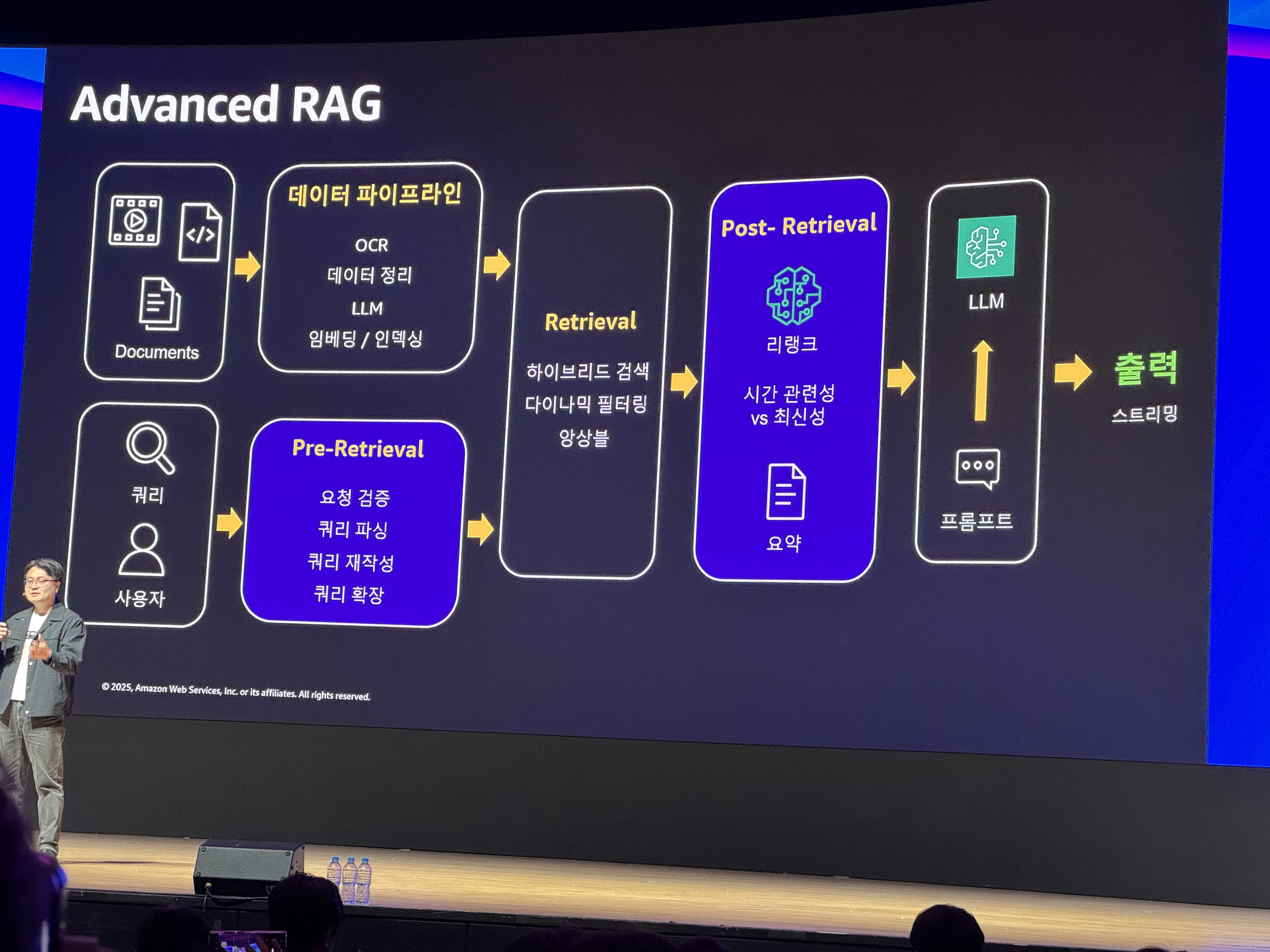
데이터 저장 Workflow
데이터를 수집하고, Gen AI가 이해할 수 있는 데이터(Embedding Vector)로 만드는 flow입니다.
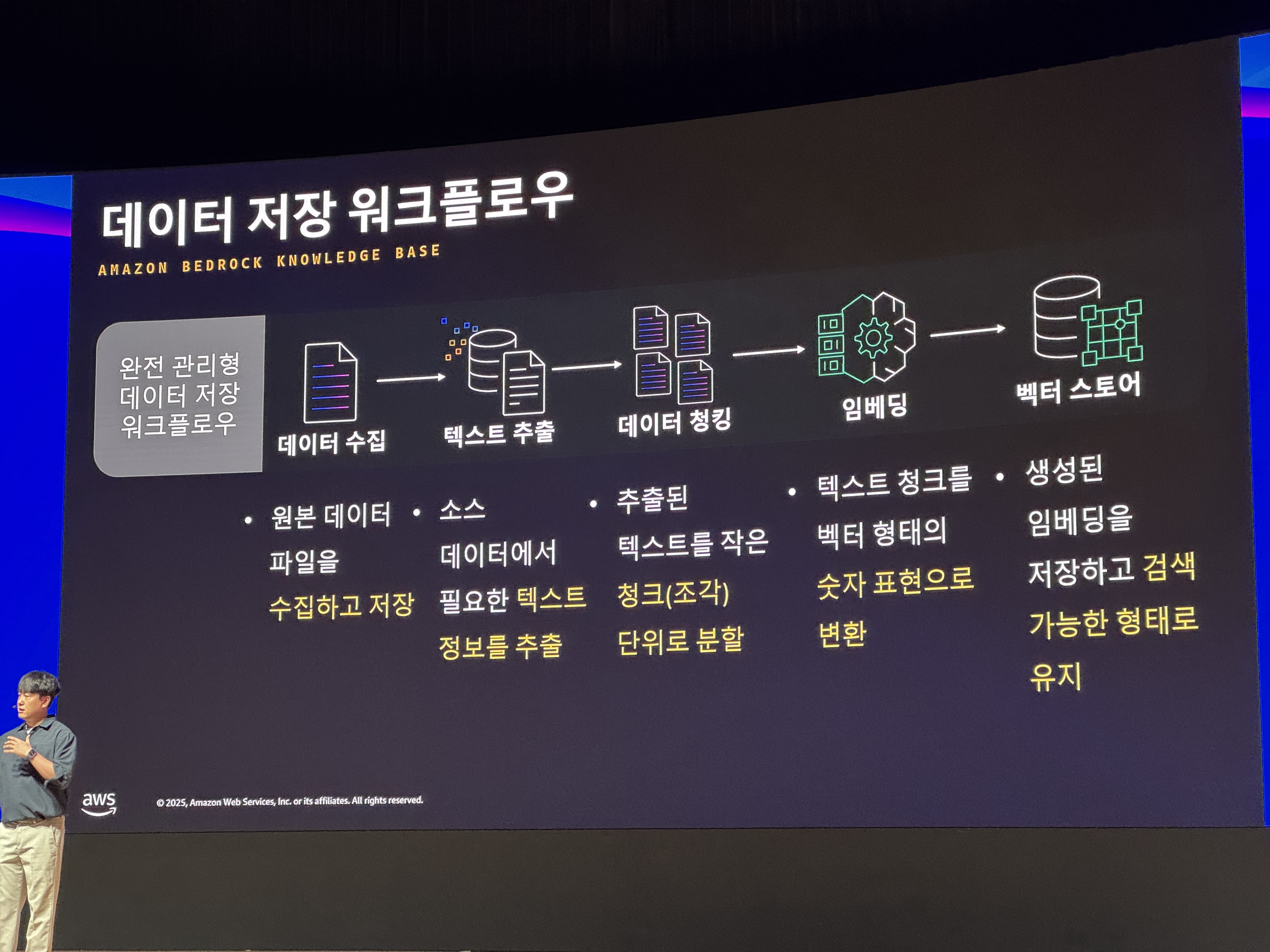 data 저장 workflow
data 저장 workflow
- 데이터 수집
텍스트 추출
Gen AI에서 ‘정보’로 판단할 데이터들을 추출 합니다.데이터 청킹(쪼개기)
추출된 데이터 전부를 Gen AI가 한번에 받아들일 순 없기때문에, 특정 기준(띄어쓰기 혹은 글자 수, 맥락 등의 기준)으로 조각냅니다.임베딩(embedding)
데이터 청크(chunk, 조각) 마다 ‘GenAI가 이해할 수 있는 데이터(Embedding vector, 임베딩 벡터)’로 만듭니다.
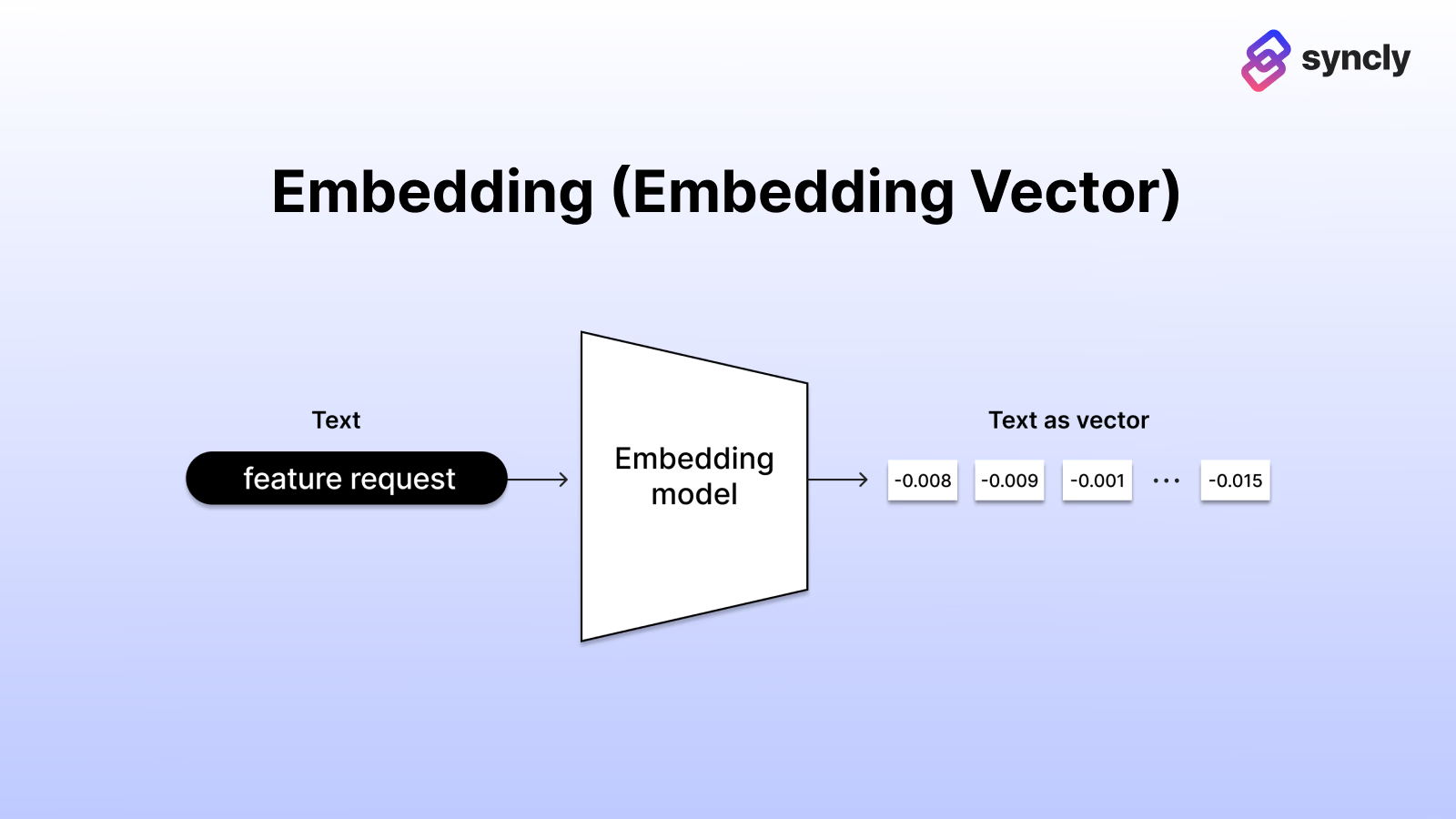 Embedding vector가 만들어지는 과정
Embedding vector가 만들어지는 과정 Embedding을 생성할 수 있는 모델 option들
Embedding을 생성할 수 있는 모델 option들데이터 조각(Chunk)을 받아서, 이를 일관된 기준에 따라, 수치화(Vectorize, embedding vector로 만듬)해야 합니다. 이 역할을 하는것이 임베딩 모델(embedding model)입니다.
- 임베딩 모델
- 바이너리 임베딩
기존 임베딩 모델과 같이 0~1사이의 실수(float)값을 갖는게 아닌, ‘0, 1’ 단 2개의 값 만으로 embedding을 만듭니다. 이는 성능과 비용 개선 효과가 있지만, 정확도가 많이 차이납니다.
- 벡터 스토어
생성된 데이터를 전문으로 다루는 벡터스토어에 저장합니다.
이로서, Prompt에 대해서, ‘벡터 유사도(vector similarity)’를 활용하여, 관련된 데이터, 관련 없는 데이터 구분이 가능해집니다.
 Vector Store로 가능한 옵션들
Vector Store로 가능한 옵션들
Gen AI와 MCP(Model Context Protocol)
Gen AI를 좀 더 광범위 하게 활용하기 위해서, 여러 서비스(인터넷, DB등)를 연결시켜 사용하게 됩니다.
이때, Agent와 다른 서비스들을 연결하여, Agent로 발전시키는 ‘핵심 Protocol 역할’을 하는것이 MCP입니다.
RAG와 MCP는 다릅니다.
RAG는 Gen AI의 데이터를 확장주는 ‘전략’이고, MCP는 Gen AI가 특정행위를 하게 만드는 프로토콜(protocol, 약속)입니다. 때문에, MCP는 표준화된 데이터 구조(JSON형식)도 포함하고 있습니다.
Amazon Bedrock를 통해, MCP를 사용하는 사례를 보여주었는데, 특별한건 없었습니다.(스폰서 세션)
우리에게 맞는 AI 서비스 Build하기
이미 업계에서는, Base Model(Foundation model)을 기반으로 Custom을 통해 AI서비스를 만드는 전략이 대세가 되고 있습니다.
여러 서비스들이 Base모델은 같은걸 사용하고 있고, 결국, 모델간 차이를 만드는건 ‘Data’임을 강조하고 있습니다.
Gen AI는 결과물에 해당한다. 이는 빙산의 일각일 뿐이다.
Gen AI라는 결과물 보다, 데이터 파운데이션(데이터 저장소와 같은)것이 더 중요하다.(빠르게 만들어낸 결과물만 보지 말라는 뜻)
- From AWS Summit 2025
데이터로 커스터마이징 하는 방법들을 아래와 같이 제시해주었습니다.
- RAG
- Gen AI에게 추가 데이터 Source를 제공해준다.
- 파인튜닝(fine-tuning)
- Base model에 데이터를 입력시켜, 파라미터를 업데이트(모델 자체를 일부 수정하는것)
- 지속적인 사전학습
- 파운데이션 모델을 직접 만든다
추천받은 자료들
- Amazon Bedrock Knowledge base로 30분 만에 멀티모달 RAG 챗봇 구축하기 실전 가이드
Amazon Bedrock Knowledge base로 30분 만에 멀티모달 RAG 챗봇 구축하기 실전 가이드 | Amazon Web Services
번외. Multi Modal와 AGI
‘Multi Modal’은 text뿐만 아니라, 여러 데이터 Source를 통해 맥락(context)을 파악하는 model입니다.  Multi modal 개념
Multi modal 개념
LLM(ChatGPT와 같은)은 Text 기반의 Model이라면, Multi-modal은 여러 데이터 형태를 받을 수 있는 model을 말합니다.
AGI(일반 인공지능, 인간을 대신할 수 있는 지능)에 도달하기 위해, Multi-modal을 고도화 하는방향으로 진행되고 있습니다.
분석(Analytics), 데이터 수집
도움이 되는 배경정보
데이터의 중요성과 데이터 갯수의 급격한 증가로 인해, 기존에 사용하던 형태의 DB보다, 분석에 특화된 DB가 필요해집니다.
OLAP와 OLTP
DB 시스템을 데이터 처리 방식에 따라, 2가지의 대분류로 분류합니다.
- OLTP(online transaction processing)
- 기존에 사용하던 형태의 DB, Transaction을 다룸
- OLAP(online analytical processing)
- 대량의 데이터 분석에 특화된 기능을 갖춘 구조, 기능을 갖고 있습니다 OLTP와 OLAP 비교 - 데이터 처리 시스템 간의 차이점 - AWS
데이터 레이크(Data Lake)의 필요성
데이터의 중요성이 높아지면서, 데이터 Schema를 정하는 과정 없이, 원본데이터 그대로(비정형 데이터)를 저장하고자 하는 요구가 생기게 됩니다.
데이터의 Schema를 정하는 과정에서, 데이터 수집전에 데이터의 형태를 정해버리면서, 데이터의 한계에 부딪히게 되었습니다.
데이터 레이크가 필요한 이유는 무엇입니까?
데이터에서 비즈니스 가치를 성공적으로 창출하는 조직은 경쟁자를 크게 능가할 것입니다. 451 Research 설문조사에 따르면 설문조사에 참여한 기업 중 절반 이상이 현재 데이터 레이크를 구현했으며, 다른 22%는 36개월 이내에 데이터 레이크를 구축할 계획이라고 답했습니다. 데이터 레이크를 비롯한 최신 데이터 아키텍처를 구현하는 회사는 운영 효율성과 매출 증대에서 측정 가능한 이점을 입증했습니다. 이러한 리더들은 실시간 스트림, IoT 센서, 소셜 미디어 및 고객 상호 작용 데이터를 비롯한 다양한 데이터 소스에서 고급 분석, 인공 지능 및 대규모 언어 모델을 사용합니다. 이 포괄적인 데이터 전략을 통해 데이터 기반 의사 결정을 더 빠르게 내리고, 고객 경험을 개인화하고, 예측 유지 보수를 통해 운영을 최적화하고, 경쟁사보다 먼저 새로운 매출 기회를 식별할 수 있습니다.
AWS document(https://aws.amazon.com/ko/what-is/data-lake/)
데이터 레이크란? - 데이터 레이크 및 분석 소개 - AWS
Open Table Format의 필요성
이런 ‘비정형 데이터’를 관리하는 시스템이 필요해지면서, 별도의 ‘표준’이 생기게 됩니다. 이를 ‘Open Table Format’을 통해, 데이터들에 대한 ‘관리 데이터’를 생성하고 갱신하고, 더 빠르 조회가 가능하게 해주는 시스템이 만들어집니다.
‘Apache Iceberg’, ‘Apache Hudi’, ‘Delta Lake’가 이에 해당합니다.
AWS에서의 Transactional Data Lake를 위한 오픈 테이블 형식(Open table format) 선택 가이드 | Amazon Web Services
Apache Iceberg
- 그중, 이 컨퍼런스에선 ‘Apache Iceberg’를 추천하고 있었습니다.
- ‘Apache Iceberg’는
- transaction 지원.
- 데이터를 버젼관리 하면서, ‘time travel(특정 시간대를 기준으로 SQL을 할 수 있는 기능)’기능을 제공합니다.
AWS에서는 S3를 Storage로 사용하고, AWS Athena를 통해 관리하게 됩니다.
이는 실제로 Query를 실행할때만 비용을 지불하여 비용최적화 됩니다.
파일 저장 비용(S3)는 별도입니다.