
AWS Summit Seoul 2025 Insight
들어가면서 이번 AWS Summit은 생성형 AI를 중심으로, 데이터 엔지니링, 운영, AI모델 활용 측면의 주제가 많았습니다. 생성형 AI(이하 Gen AI)가 업계의 새로운 광산(금을 케는)이 되었고, 이에 따라 기술적 전략을 수립하기 위한 Insight를 얻기에 좋은 자리였습니다. 본문 업계의 트렌드가 보편적인 목적의 AI모델(GPT와 같은 F...
들어가면서 이번 AWS Summit은 생성형 AI를 중심으로, 데이터 엔지니링, 운영, AI모델 활용 측면의 주제가 많았습니다. 생성형 AI(이하 Gen AI)가 업계의 새로운 광산(금을 케는)이 되었고, 이에 따라 기술적 전략을 수립하기 위한 Insight를 얻기에 좋은 자리였습니다. 본문 업계의 트렌드가 보편적인 목적의 AI모델(GPT와 같은 F...
들어가기전에.. 2024 Google MLB가 끝나고, NIPA와 Google MLB와 연계된 실무 프로젝트(이하 NIPA)를 이어가게 되었습니다. NIPA에서 6명이 팀을 이루어 ML을 이용한 ‘Synchro-you’라는 제품을 만들었습니다. Synchro-you 프로젝트 소개 최근 유행하고 있는 각종 챌린지 영상에서 영감을 받아, ‘내가 얼...
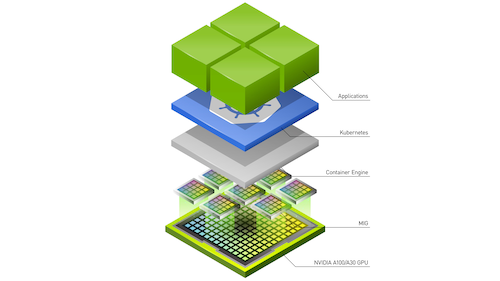
들어가면서 AI시대에 회사에서 GPU를 어떻게 서빙할지에 대한 고민이 있습니다. 이를 위해, GPU가 어떻게 Kubernetes와 결합해서 서빙 되는지 이해하고자, 조사하게 되었습니다. 여러 Inference Accelerator(AWS Inferentia, Google TPU등)들이 있지만, 여기서는 회사에서 사용하고 있는, Nvidia G...

Redis 소개 Redis is the world’s fastest in-memory database. - from redis.io Redis는 C로 작성된, 오픈소스 in-memory key-value 저장소 입니다.(데이터를 Disk가 아닌 RAM에 저장하여 사용합니다.) 빠른 속도와 다양한 자료구조(Data structur...

‘Consistent Hashing’은 분산 시스템(Distributed System)의 Cluster에서, 데이터를 분산 저장할때 사용하는 기초적인 알고리즘 입니다. 예시로 보는 Consistent Hashing의 필요성 ‘Ticketing System을 구성한다고 해봅시다. Simple System과 Sharding이 적용된 System...
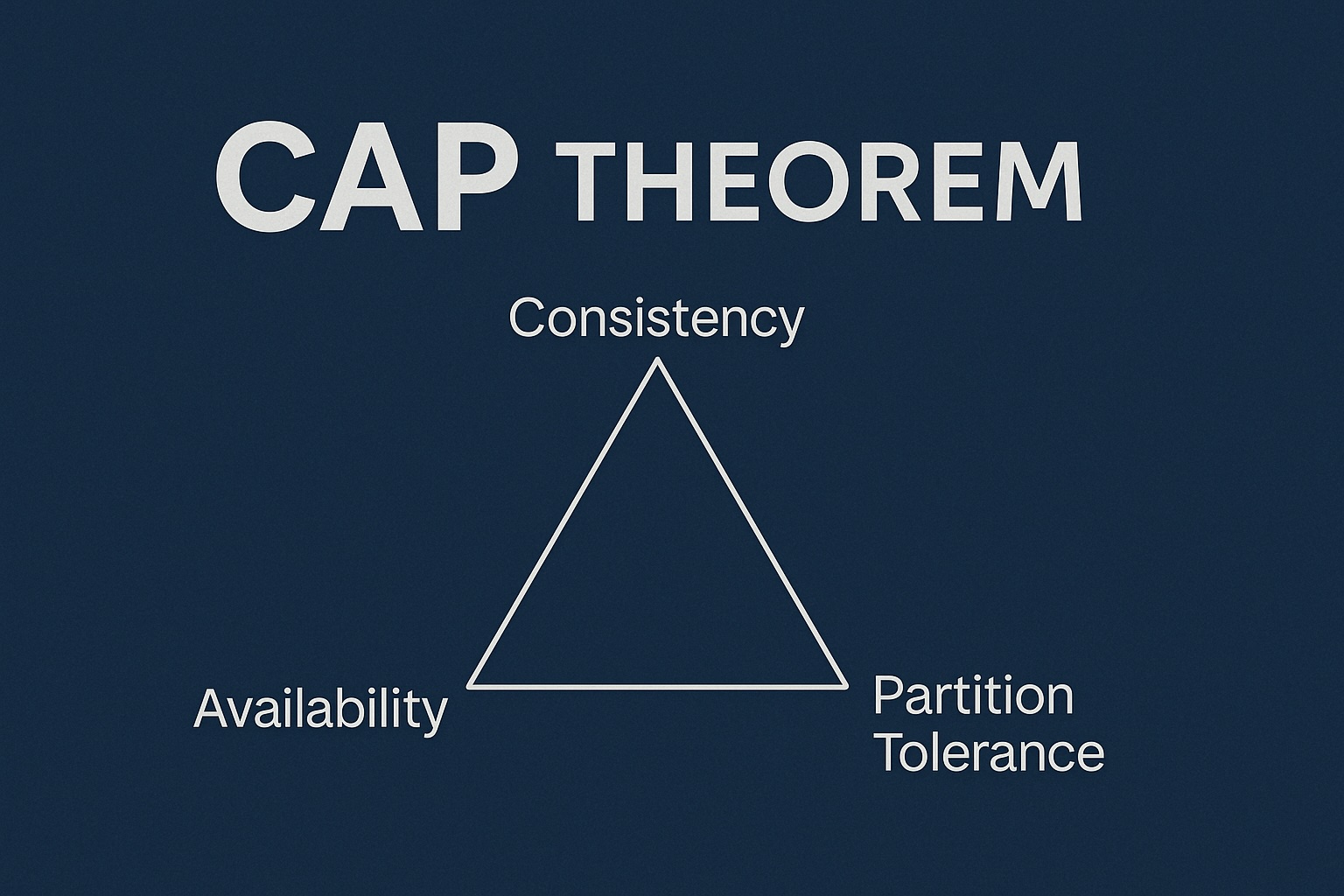
CAP Theorem 소개 CAP는 각각 Consistency, Availability, Partition Tolerance를 의미합니다. 이 ‘CAP Theorem’은 ‘Distributed System(분산처리 시스템)’의 3가지 핵심 속성에서, 이중 딱 2개만 취할 수 있다는 theorem(정리, 일정한 조건하에 참이라는 것이 증명됨...

Kafka 소개 Kafka는 대용량의 실시간 데이터 스트리밍을 처리하는 분산(Distributed) 메시징 시스템입니다. 원래 LinkedIn에서 개발되었고, 이후 Apache Software Foundation에서 오픈소스로 관리되고 있습니다. 탄생 배경(LinkedIn에서) 로그와 사용자 이벤트 데이터 폭증 ‘Li...

CloudNativePG 소개 CloudNativePG(이하 CNPG)는 PostgreSQL을 Kubernetes 환경에 네이티브하게 배포 및 운영할 수 있도록 해주는 오픈소스 오퍼레이터(Operator)입니다. CNCF(Cloud Native Computing Foundation)의 인큐베이팅 프로젝트로 채택되어 있으며, Postgre...
시스템 디자인(System Design)에 있어, 네트워킹(Netwoking)은 고려해야하는 필수적인 부분중 하나입니다. 이 Post에선, 네트워킹에서도 가장 중요한 부분만 정리하려고 합니다. 네트워킹 기초(Networking 101) OSI(Open Systems Interconnection) Model 7 Layers OSI Model 7 L...

Kubernetes는 Infra에 대한 추상화를 제공하는 Framework입니다. 이때, 가장 기본이 되는 추상화 단위가 ‘Pod(파드)’입니다. 이 Pod를 어떻게 다루느냐(Workload Management)에 따라, 한 단계 더 추상화된, ‘Deployments’, ‘ReplicaSet’, ‘DaemonSet’등의 Workload Object가...